Identifying Mislabels
Identifying Mislabels
In the field of machine learning, it is not uncommon to encounter mislabeled data, where the initial labels assigned to the data instances are incorrect.
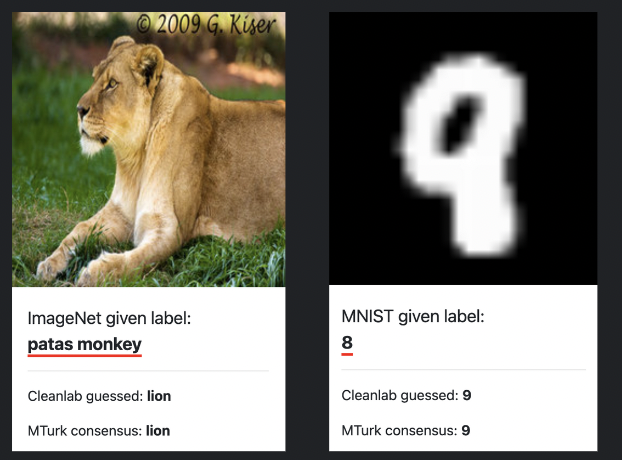
As seen from Cleanlab's labelerrors.com, benchmark test datasets in ML, such as MNIST and IMAGENET, can be riddled with label errors.
In the domain of text data, benchmark datasets sucha as AMAZON REVIEWS and IMDB are also filled with label errors.

Practically, most likely over 10 percent of data has label errors. This problem is only growing with the hallucination of LLMs, making data quality an even more paramount issue. It is essential to identify and rectify these mislabels to ensure the accuracy and reliability of machine learning models.
More Example Datasets with Label Errors
Consider the following example dataset, where each row represents a text instance along with its initial label and the label predicted by a model:
Table 1: GoEmotions
| Text | Initial_label | Predicted_label | Error_threshold |
|---|---|---|---|
| YAY, cold Mc'Donalds. My favorite | LOVE | SARCASM | 0.95 |
| hell yeah my brother | ANNOYANCE | EXCITEMENT | 0.94 |
Table 2: Sentiment Analysis
| Text | Initial_label | Predicted_label | Error_threshold |
|---|---|---|---|
| Like everyone else my preference is for real mashed potatoes, but for fake ones... | NEUTRAL | POSITIVE | 0.87 |
| Helps me realize I am ok Not a big slob now I feel better!!!!!!! Yay Yay Ya! No more... | NEGATIVE | POSITIVE | 0.84 |
Identifying Mislabels for Text Classification
Step 1: Zero-Shot Classification Predictions
Perform zero-shot classification predictions for your data using the three models of your choice. Each model should provide class predictions and probability scores for each instance in your dataset.
| Instance ID | Input Text | Model 1 Prediction | Model 1 Probability | Model 2 Prediction | Model 2 Probability | Model 3 Prediction | Model 3 Probability |
|---|---|---|---|---|---|---|---|
| 1 | Text 1 | Class A | 0.85 | Class B | 0.32 | Class C | 0.74 |
| 2 | Text 2 | Class C | 0.60 | Class C | 0.75 | Class C | 0.42 |
| 3 | Text 3 | Class B | 0.72 | Class A | 0.43 | Class B | 0.55 |
| 4 | Text 4 | Class A | 0.90 | Class A | 0.85 | Class A | 0.88 |
| 5 | Text 5 | Class C | 0.68 | Class B | 0.57 | Class C | 0.61 |
| 6 | Text 6 | Class B | 0.77 | Class B | 0.89 | Class A | 0.76 |
Step 2: Determine Overlapping Predictions
Compare the class predictions of the three models for each instance in your dataset. Identify the rows where the model predictions do not overlap, meaning certain models predicts a different class for that instance than other models.
| Instance ID | Input Text | Non-Overlapping Predictions? |
|---|---|---|
| 1 | Text 1 | Yes |
| 2 | Text 2 | No |
| 3 | Text 3 | Yes |
| 4 | Text 4 | No |
| 5 | Text 5 | Yes |
| 6 | Text 6 | Yes |
Step 3: Calculate Probability Gap
For the rows where the model predictions do not overlap, calculate the gap in probability scores. The probability gap is calculated as the absolute difference between the highest and second-highest probability scores among the models, for the rows where the predictions are non-overlapping.
| Instance ID | Input Text | Model 1 Probability | Model 2 Probability | Model 3 Probability | Probability Gap |
|---|---|---|---|---|---|
| 1 | Text 1 | 0.85 | 0.32 | 0.74 | 0.11 |
| 3 | Text 3 | 0.72 | 0.43 | 0.55 | 0.17 |
| 5 | Text 5 | 0.68 | 0.57 | 0.61 | 0.07 |
| 6 | Text 6 | 0.77 | 0.89 | 0.76 | 0.13 |
Step 4: Sort By Probability Gap
Sort the rows based on the calculated probability gap in descending order. Select the rows with mislabels that have a probability gap greater than a specific threshold that you define.
| Instance ID | Input Text | Model 1 Prediction | Model 1 Probability | Model 2 Prediction | Model 2 Probability | Model 3 Prediction | Model 3 Probability | Probability Gap |
|---|---|---|---|---|---|---|---|---|
| 3 | Text 3 | Class B | 0.72 | Class A | 0.43 | Class B | 0.55 | 0.17 |
| 6 | Text 6 | Class B | 0.77 | Class B | 0.89 | Class A | 0.76 | 0.13 |
| 1 | Text 1 | Class A | 0.85 | Class B | 0.32 | Class C | 0.74 | 0.11 |
| 5 | Text 5 | Class C | 0.68 | Class B | 0.57 | Class C | 0.61 | 0.07 |
Step 5: Present Results
The outputed mislabels table includes the rows that have a probability gap greater than the specified threshold of 0.10, as well as their aggregate model predictions across the 3 models.
| Instance ID | Input Text | Probability Gap | Aggregate Prediction |
|---|---|---|---|
| 3 | Text 3 | 0.17 | Class B |
| 6 | Text 6 | 0.13 | Class B |
| 1 | Text 1 | 0.11 | Class A |
Identifying Mislabels for Q&A Models
In this section, we focus on identifying mislabels for text prompting. We aim to generate freeform text answers given a question and compare the outputs of two models. The outputs will be sorted by similarity, and the least similar responses will be considered as potential mislabels.
Step 1: Zero-Shot Prompting Predictions
To start, we perform zero-shot prompting predictions using the GPT and Claude models. Each model provides freeform text answers for each instance in the dataset.
| ID | Question | Model 1 Answer | Model 2 Answer |
|---|---|---|---|
| 1 | What is the capital of France? | Paris, the romantic city of love and lights. | Tokyo, the bustling metropolis of Japan. |
| 2 | What is the chemical formula of water? | H2O, a compound essential for life. | NaCl, the formula for table salt. |
| 3 | Which planet is closest to the Sun? | Mercury, the scorched planet in our solar system. | Mars, the red planet with its captivating mysteries. |
| 4 | What is the capital of Japan? | Tokyo, the vibrant capital known for its blend of tradition and modernity. | London, the historic city and capital of the United Kingdom. |
| 5 | Which ocean is the largest in the world? | Pacific, the vast expanse of water covering one-third of the Earth's surface. | Arctic, the frigid ocean surrounding the North Pole. |
| 6 | What is the longest river in Africa? | Nile, the legendary river flowing through ancient civilizations. | Amazon, the mighty river teeming with diverse wildlife. |
Step 2: Calculate Text Similarity
Next, we use the Word2Vec model to calculate the similarity between the responses of GPT and Claude for each instance. We can alternatively calculate the similarity between the answers generated by the two models using a text similarity metric, such as cosine similarity or Levenshtein distance. This helps us identify the rows where the model predictions do not overlap, which can help us find where mislabeled prompts may occur.
| ID | Question | Model 1 Answer | Model 2 Answer | Similarity Score |
|---|---|---|---|---|
| 1 | What is the capital of France? | Paris, the romantic city of love and lights. | Tokyo, the bustling metropolis of Japan. | 0.70 |
| 2 | What is the chemical formula of water? | H2O, a compound essential for life. | NaCl, the formula for table salt. | 0.55 |
| 3 | Which planet is closest to the Sun? | Mercury, the scorched planet in our solar system. | Mars, the red planet with its captivating mysteries. | 0.60 |
| 4 | What is the capital of Japan? | Tokyo, the vibrant capital known for its blend of tradition and modernity. | London, the historic city and capital of the United Kingdom. | 0.70 |
| 5 | Which ocean is the largest in the world? | Pacific, the vast expanse of water covering one-third of the Earth's surface. | Arctic, the frigid ocean surrounding the North Pole. | 0.65 |
| 6 | What is the longest river in Africa? | Nile, the legendary river flowing through ancient civilizations. | Amazon, the mighty river teeming with diverse wildlife. | 0.60 |
Step 3: Sort by Similarity
We sort the rows based on the similarity scores in descending order. This allows us to identify the instances with the least similar answers, which may indicate potential mislabels.
| ID | Question | Model 1 Answer | Model 2 Answer | Similarity Score |
|---|---|---|---|---|
| 2 | What is the chemical formula of water? | H2O, a compound essential for life. | NaCl, the formula for table salt. | 0.55 |
| 3 | Which planet is closest to the Sun? | Mercury, the scorched planet in our solar system. | Mars, the red planet with its captivating mysteries. | 0.60 |
| 6 | What is the longest river in Africa? | Nile, the legendary river flowing through ancient civilizations. | Amazon, the mighty river teeming with diverse wildlife. | 0.60 |
| 5 | Which ocean is the largest in the world? | Pacific, the vast expanse of water covering one-third of the Earth's surface. | Arctic, the frigid ocean surrounding the North Pole. | 0.65 |
| 1 | What is the capital of France? | Paris, the romantic city of love and lights. | Tokyo, the bustling metropolis of Japan. | 0.70 |
| 4 | What is the capital of Japan? | Tokyo, the vibrant capital known for its blend of tradition and modernity. | London, the historic city and capital of the United Kingdom. | 0.70 |
Step 4: Present Results
The outputed mislabels table includes the rows that have a similarity score less than the specified threshold of 0.66, which means the model thinks these prompts are incorrect.
| Instance ID | Question | Model 1 Answer | Model 2 Answer | Similarity Score |
|---|---|---|---|---|
| 2 | What is the chemical formula of water? | H2O, a compound essential for life. | NaCl, the formula for table salt. | 0.55 |
| 3 | Which planet is closest to the Sun? | Mercury, the scorched planet in our solar system. | Mars, the red planet with its captivating mysteries. | 0.60 |
| 6 | What is the longest river in Africa? | Nile, the legendary river flowing through ancient civilizations. | Amazon, the mighty river teeming with diverse wildlife. | 0.60 |
| 5 | Which ocean is the largest in the world? | Pacific, the vast expanse of water covering one-third of the Earth's surface. | Arctic, the frigid ocean surrounding the North Pole. | 0.65 |