Named Entity Recognition
Named Entity Recognition (NER) is a natural language processing (NLP) technique that aims to locate and classify named entities in text into predefined categories. Named entities refer to real-world objects such as persons, locations, organizations, dates, and more. NER plays a crucial role in extracting meaningful information from unstructured text data, enabling automated analysis, information retrieval, and data mining.
Example: Identifying PII / PHI with NER
In this example, we will utilize NER to identify and classify different types of Personally Identifiable Information (PII) and Protected Health Information (PHI) within a given text. The following table presents a subset of the example dataset:
| Text |
|---|
| My name is John Doe and my email is johndoe@example.com. |
| I live at 123 Main St, Anytown, USA. |
| My phone number is 555-123-4567. |
| I was born on January 1, 1980. |
| My driver's license number is D1234567. |
| My passport number is 123456789. |
| My social security number is 123-45-6789. |
| My credit card number is 1234 5678 9012 3456. |
| My medical record number is MR12345. |
| My car's license plate number is ABC 1234. |
| My IP address is 192.0.2.0. |
| My employee ID number is E12345. |
| My student ID number is S12345. |
| I can't login to my account, my username is johndoe. |
| My VIN is 1HGCM82633A123456. |
| My biometric ID is BD12345. |
Categories of PII
We would like to identify the following types of PII in the given text:
- Name: Full Name - The complete name of an individual.
- Address: Home Address - The residential address of an individual.
- Email: Email Address - Personal email addresses.
- SSN: Social Security Number - A unique number assigned to individuals in the United States for identification purposes.
- Passport: Passport Number - A unique number assigned to a passport document.
- License: Driver's License Number - A unique number assigned to a driver's license.
- CreditCard: Credit Card Numbers - Numbers associated with personal credit cards.
- Birthdate: Date of Birth - The birth date of an individual.
- Phone: Telephone Number - Personal landline or mobile phone numbers.
- MedicalRecord: Medical Record Numbers - Unique identifiers for personal medical records.
- Biometric: Biometric Identifiers - Fingerprints, facial recognition patterns, DNA, etc.
- Vehicle: Vehicle Identifiers - License plate numbers, Vehicle Identification Number, etc.
- InternetActivity: Internet Activity - IP addresses, cookie IDs, device identifiers, etc.
- Employment: Employment Information - Employee ID number, work email, work phone number, etc.
- Education: Educational Records - Student ID number, transcripts, etc.
Using Anote to extract entities within text
Upload Data: Start by uploading the dataset into Anote. We upload the CSV in Unstructured format, choose the NLP task of Named Entity Recognition, and choose the per line decomposition.
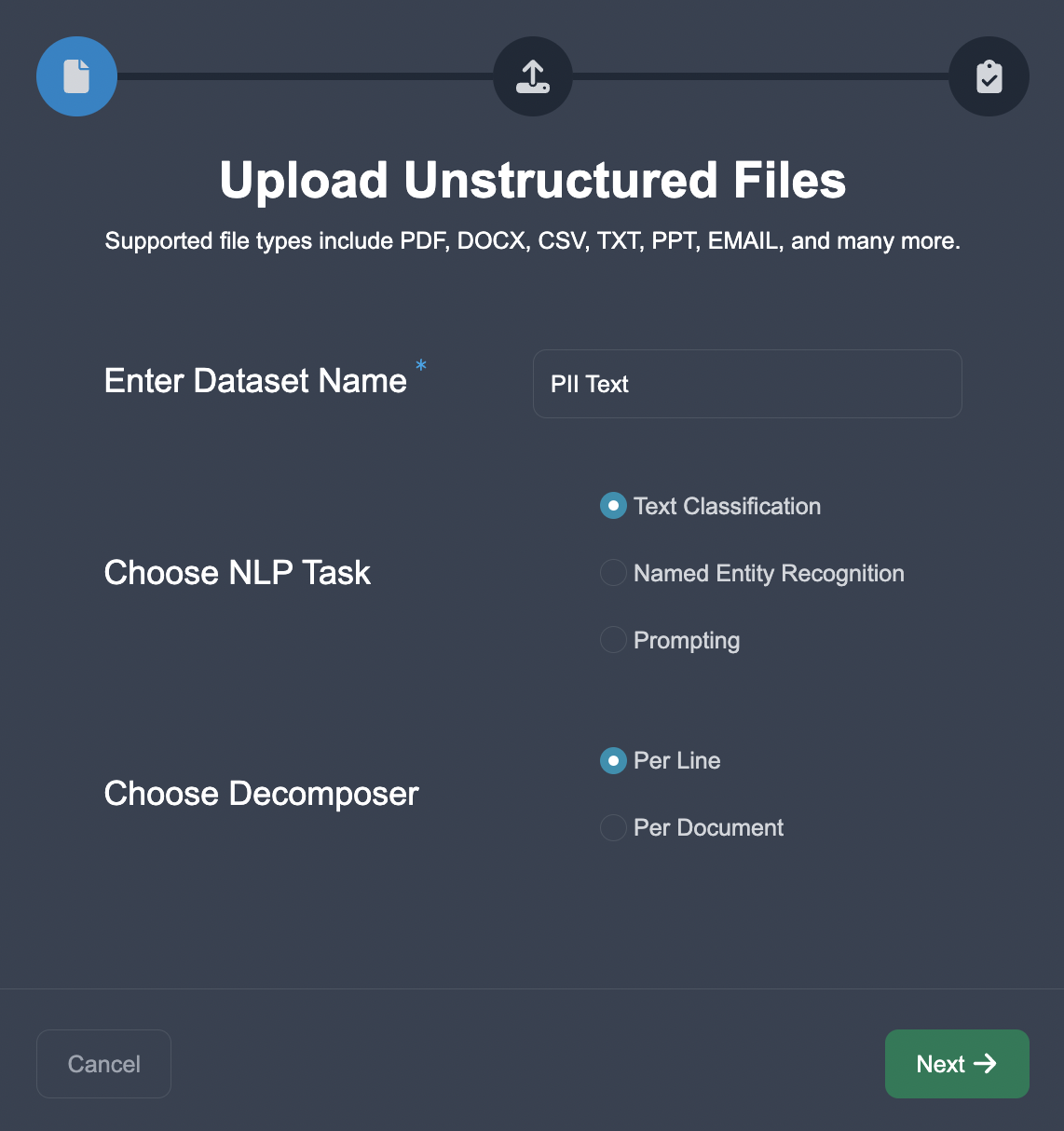
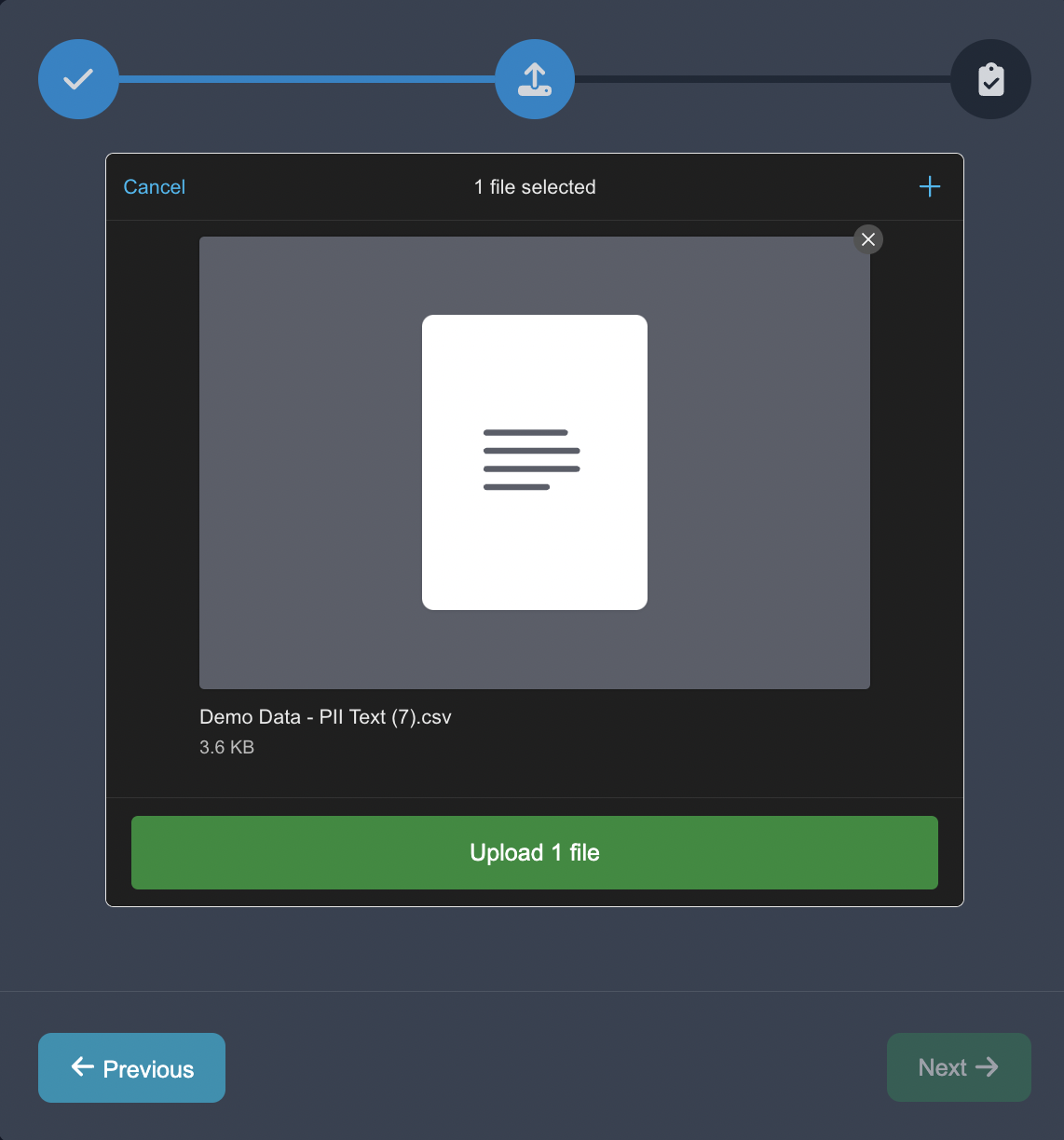
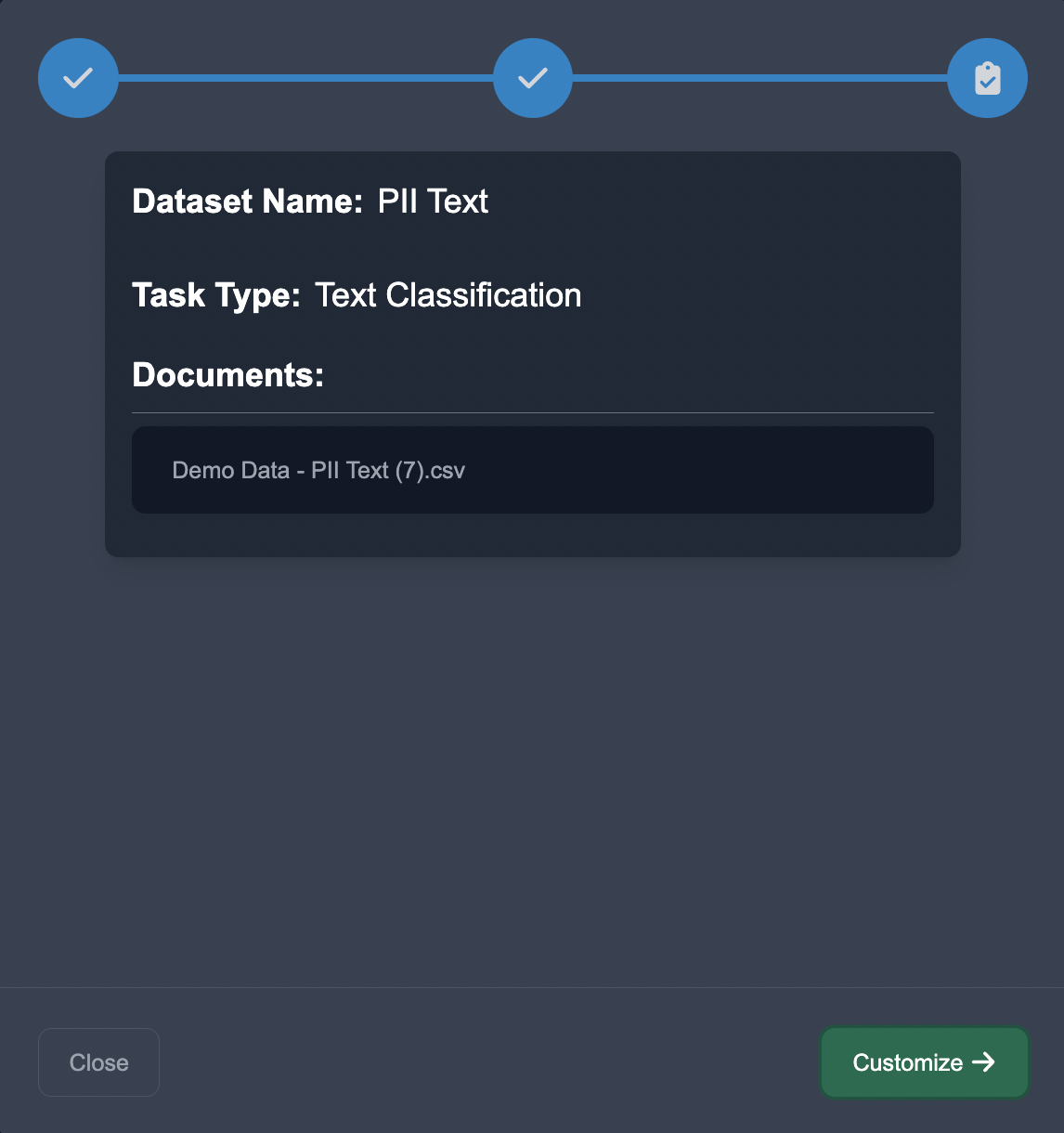
Customize Categories: In the annotation interface, we want to set up the entity categories as listed above. We customize the entities in Anote's configuration settings by pressing the + Add Taxonomy button to add the entities.
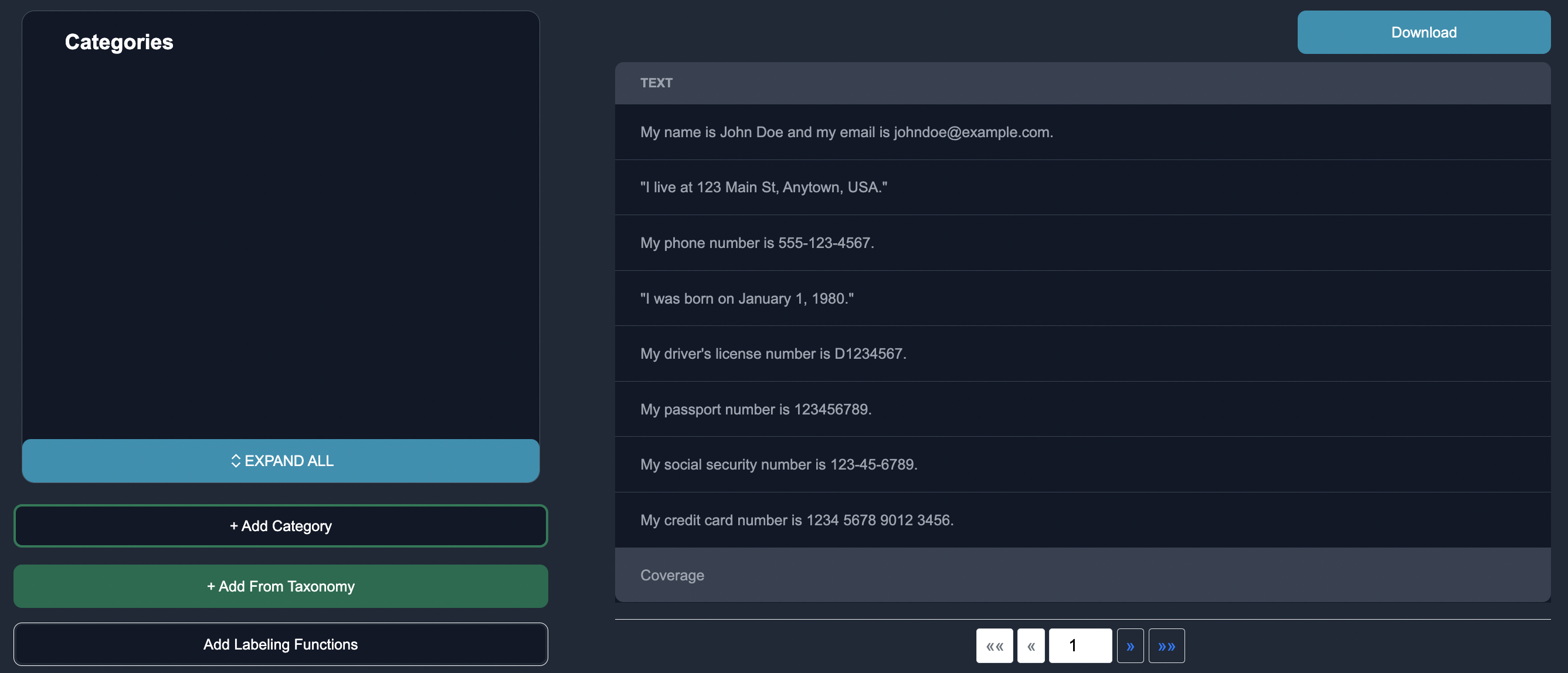
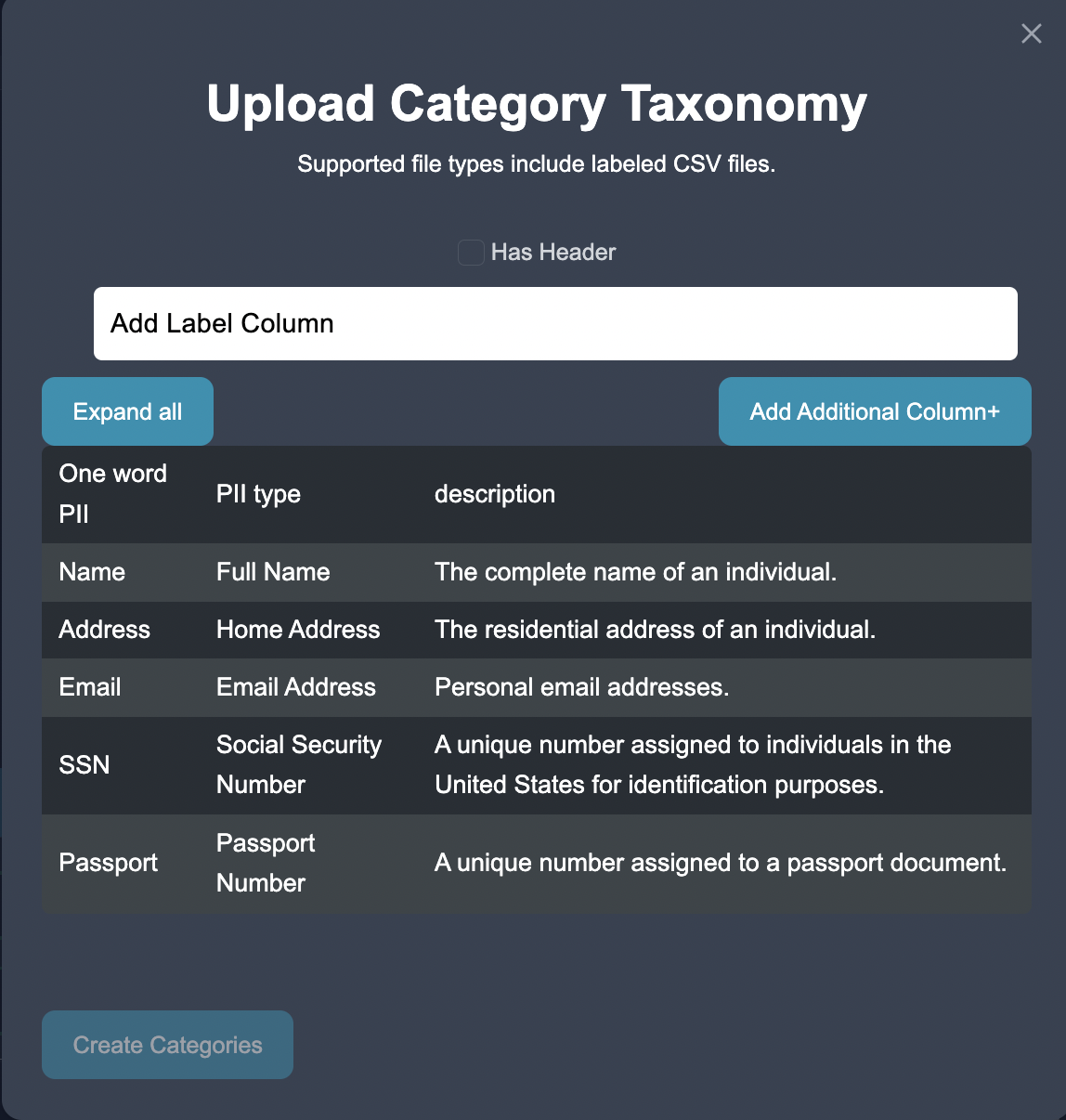
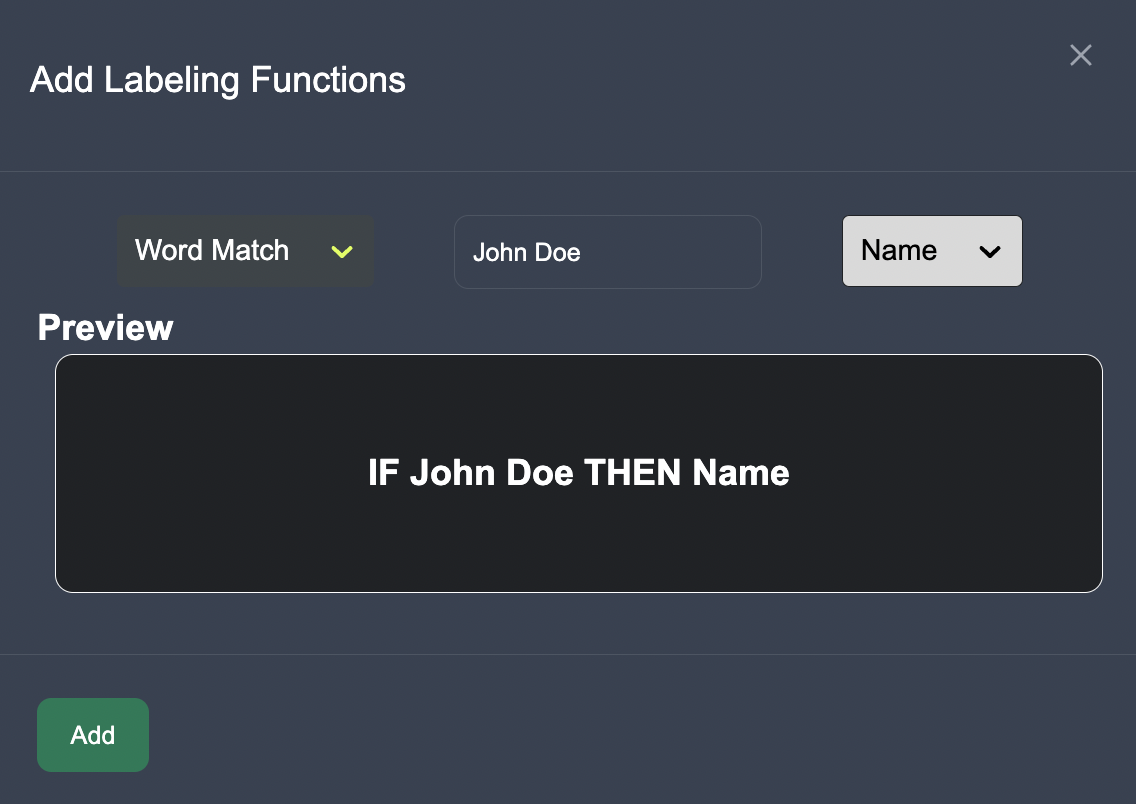
We can add labeling function to identify key words where entities may appear in the text.
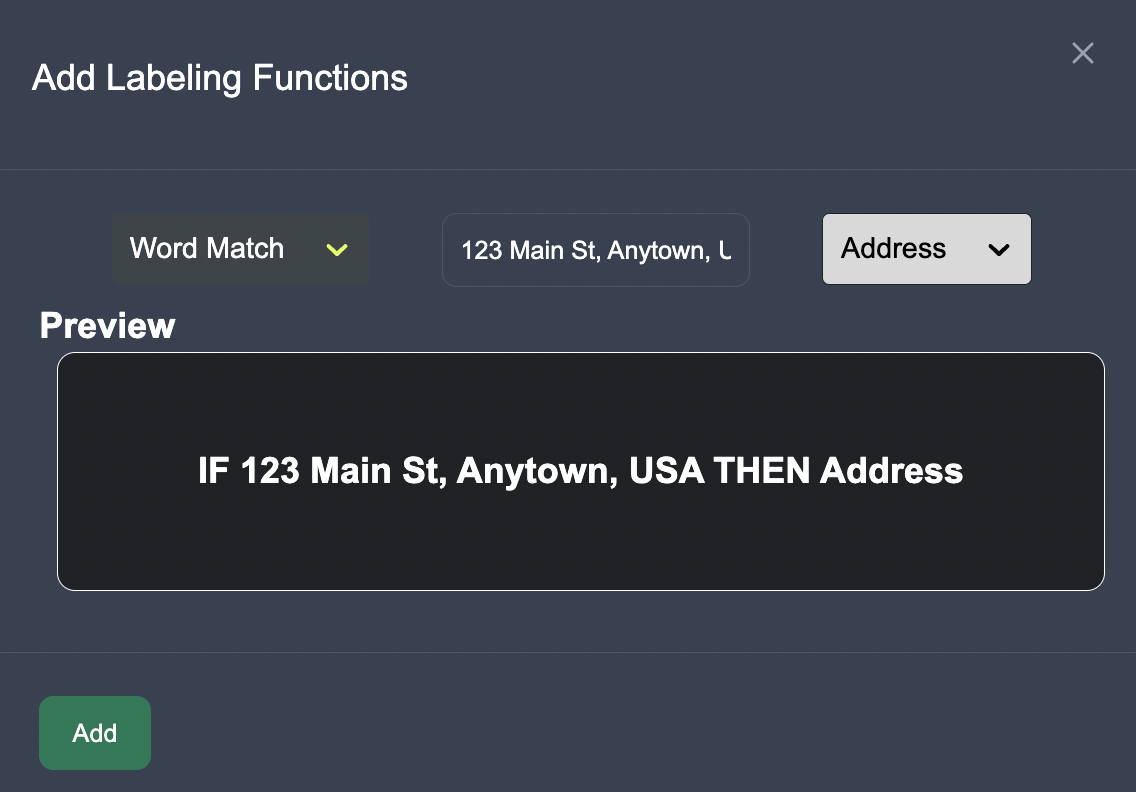
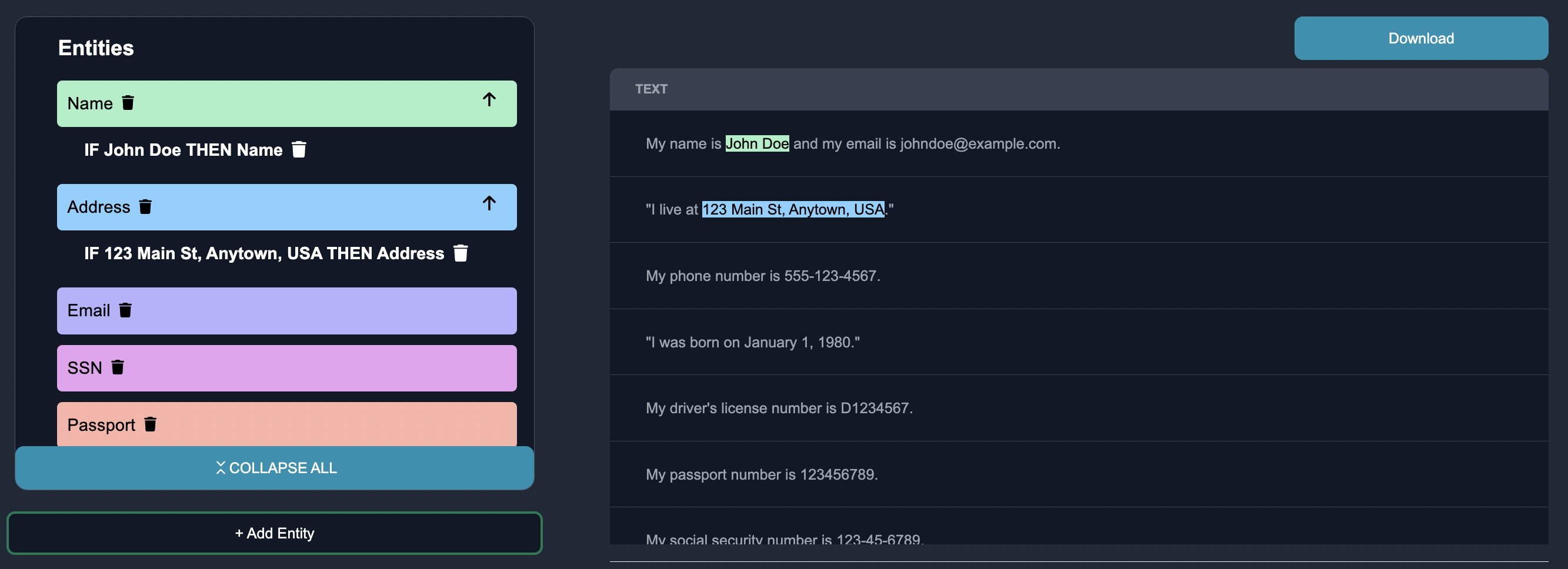
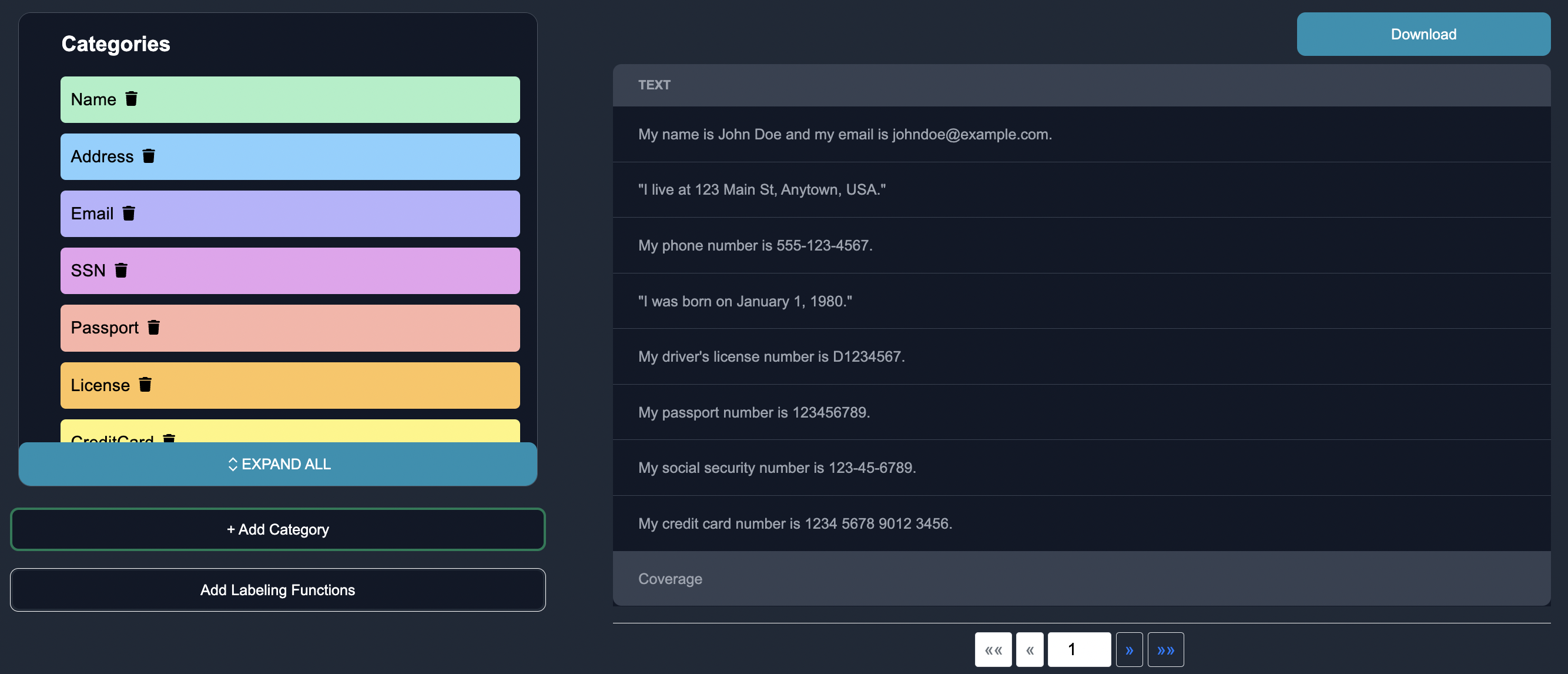
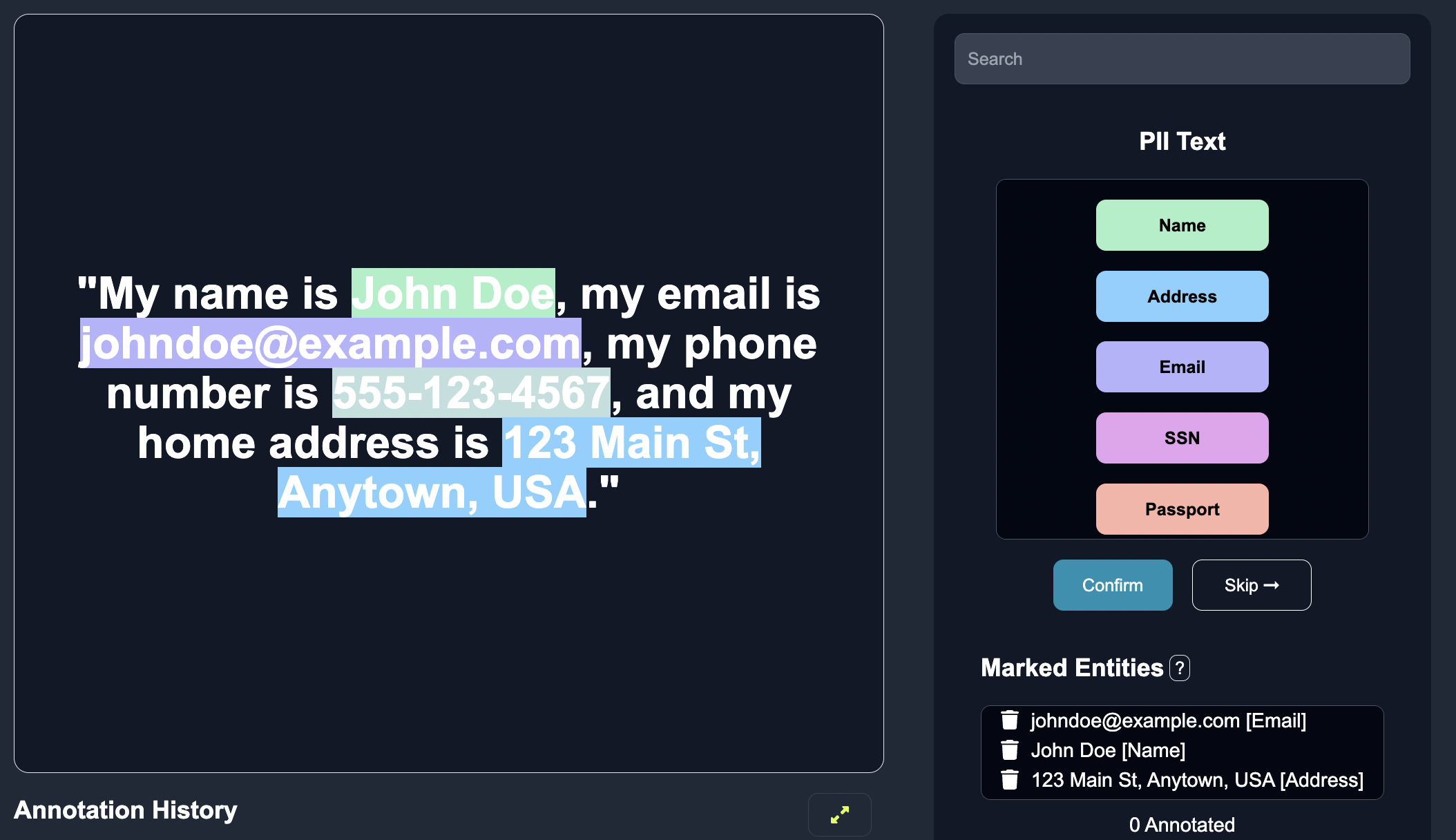
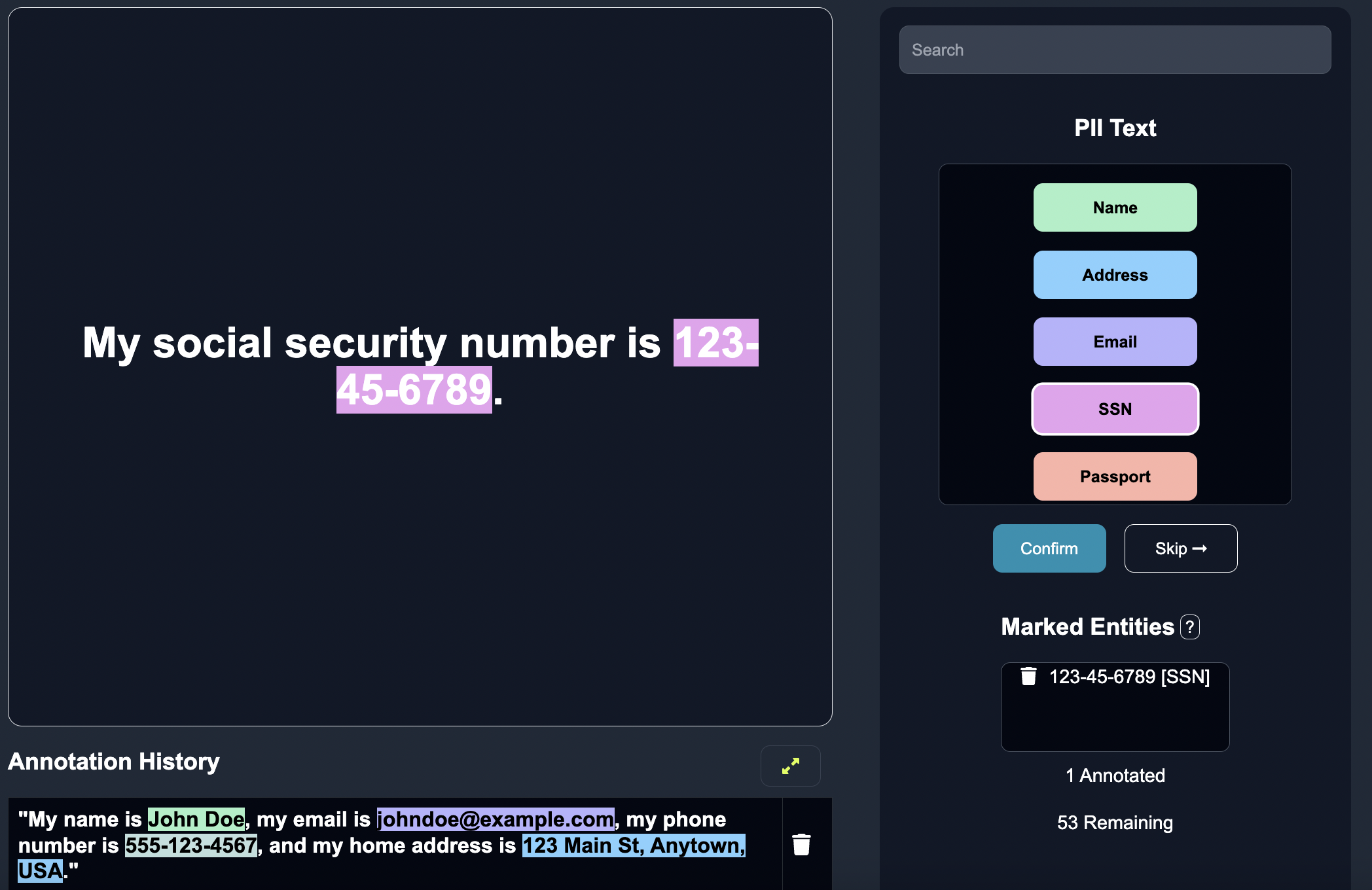
Annotate a Subset of Text Data: Anote provides an intuitive interface where we can view the text data that the model is least certain about, and annotate the edge cases with one of the defined categories above. On Anote, we label few rows of entities by highlight all the entities in the given row of text, and then clicking the "confirm" button once completed. We can also remove entities that the model may predict incorrectly.
Export as CSV: Once finished annotating a few entities, we can download the resulting entities in CSV format. The entity category should be in parenthesis, to the right of where the entity was identified, as seen below.
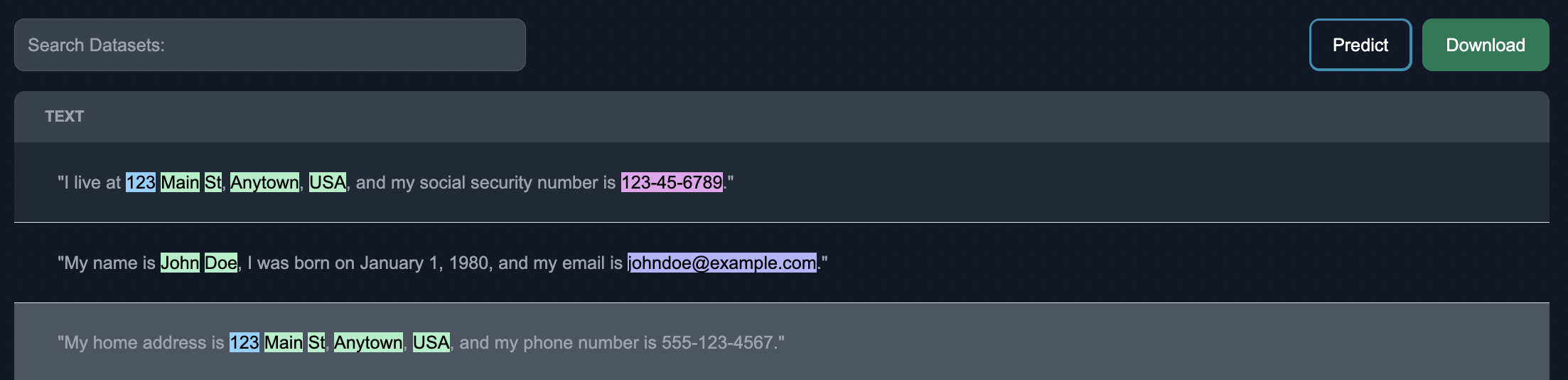
Notice below that the NER model is able to pick up entities such as credit card information that weren't even annotated yet, this is through a fusion with the zero shot NER model.

Below is what a proper output should look like.
| Text |
|---|
| My name is [John Doe] (Name). |
| I live at [123 Main St, Anytown, USA] (Address). |
| My phone number is [555-123-4567] (Phone). |
| I was born on [January 1, 1980] (Birthdate). |
| My driver's license number is [D1234567] (License). |
| My passport number is [123456789] (Passport). |
| My social security number is [123-45-6789] (SSN). |
| My credit card number is [1234 5678 9012 3456] (CreditCard). |
| My medical record number is [MR12345] (MedicalRecord). |
| My car's license plate number is [ABC 1234] (Vehicle). |
| My IP address is [192.0.2.0] (InternetActivity). |
| My employee ID number is [E12345] (Employment). |
| My VIN is [1HGCM82633A123456] (Vehicle). |
| My biometric ID is [BD12345] (Biometric). |
Hierarchical PII Taxonomy
Due to changing business requirements, we want to refine our entity identification requirements on this example dataset. The rationale behind this decision lies in the pursuit of more granular entities that can be precisely identified within text data.
Introduction of Hierarchies: To better organize and manage the diverse types of PII, we introduced hierarchical structures within the entity identification process. This approach allowed us to establish clearer relationships between PII categories, such as IDs and Contact Info.
Addition of New Categories: Recognizing the evolving nature of data, we decided to incorporate additional categories, such as usernames and student IDs.
Table 2: Subcategories - ID and Contact Info
| Subcategory | Description |
|---|---|
| ID | Includes IDs such as SSN, Passport, License, CreditCard, MedicalRecord, Biometric, Vehicle, and Education. |
| Contact Info | Includes Phone, Email, InternetActivity, Employment, and Education. |
IDs
- License
- Passport
- SSN
- CreditCard
Contact
- Phone
- Username
- Student ID
Categories without Subcategories
- Name
- Address
- Birthdate
Adapting to Changing NER Requirements
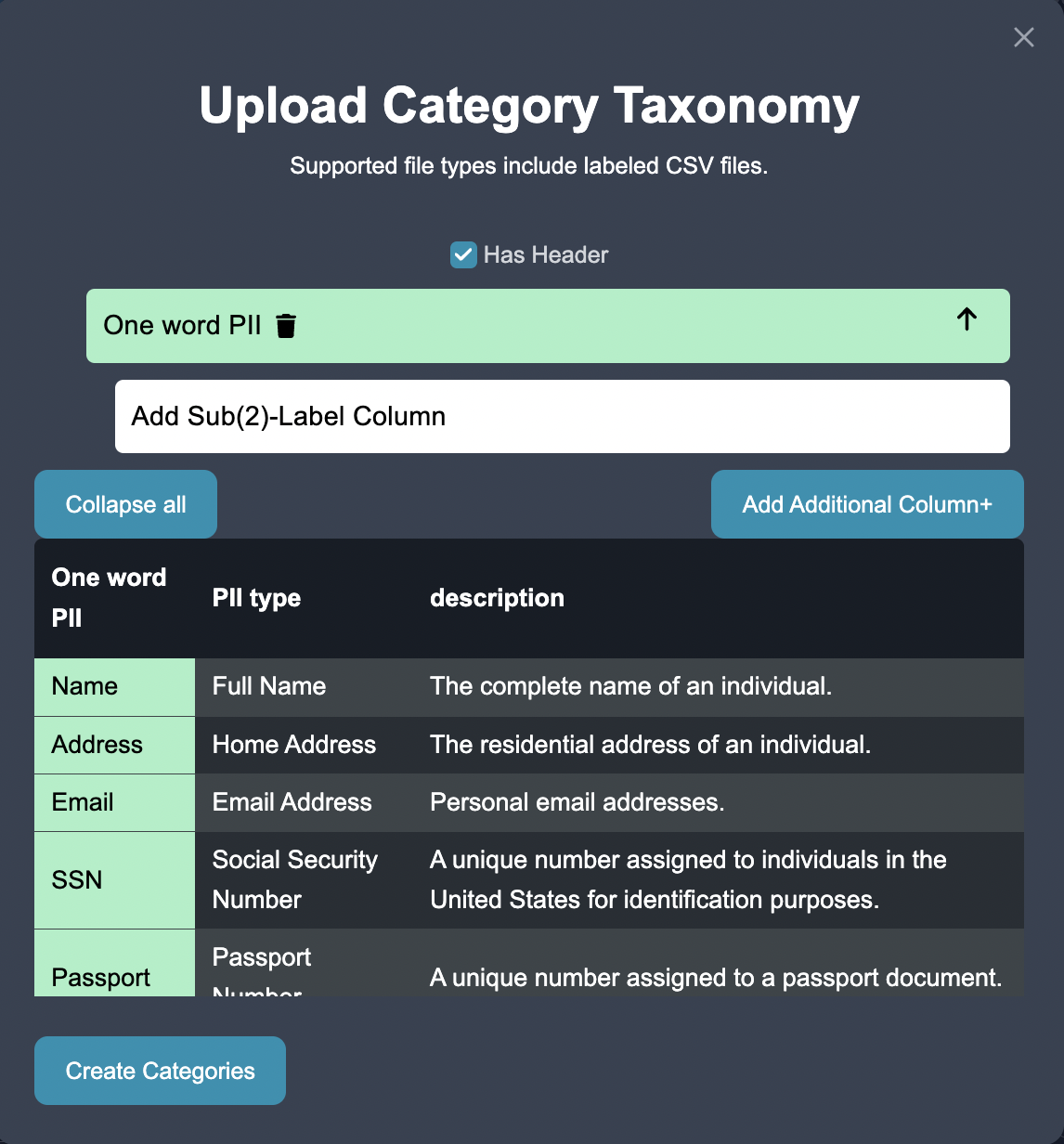
To make adjust to the changing business requirements, we navigate to the customize tag. We can add nested sub-entities underneath existing entities. We can also define new entities. After we make the modifications, we can expand our categories to see all of the categories.
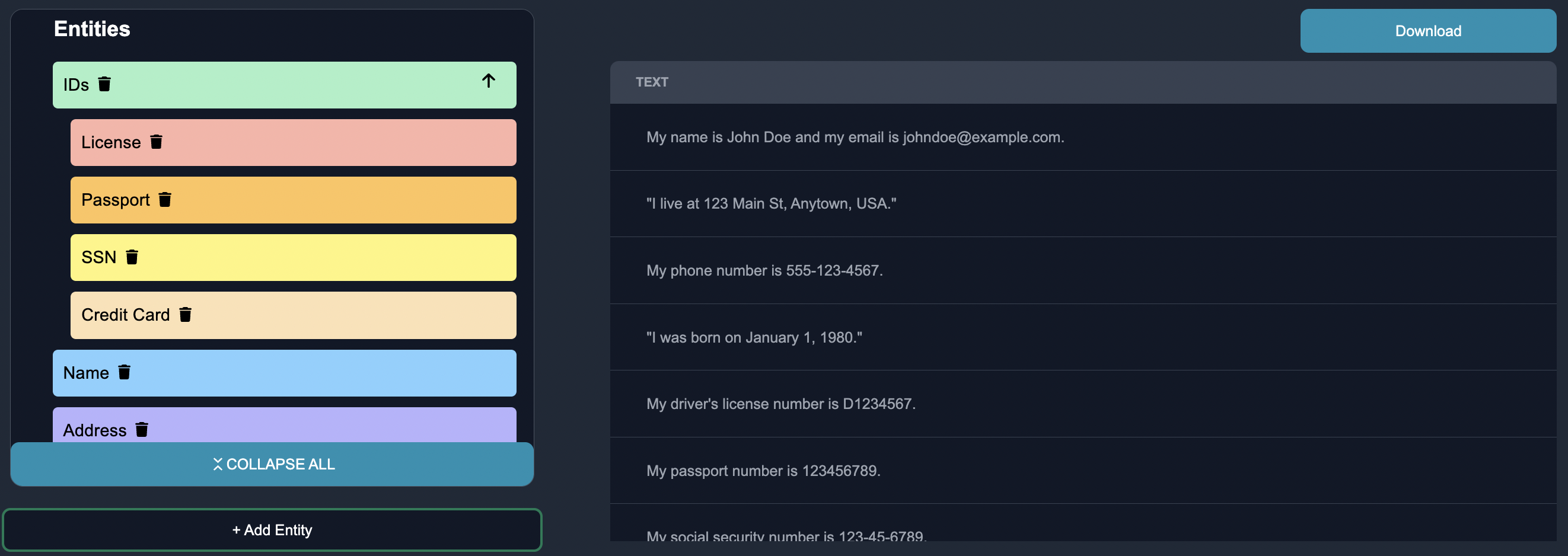
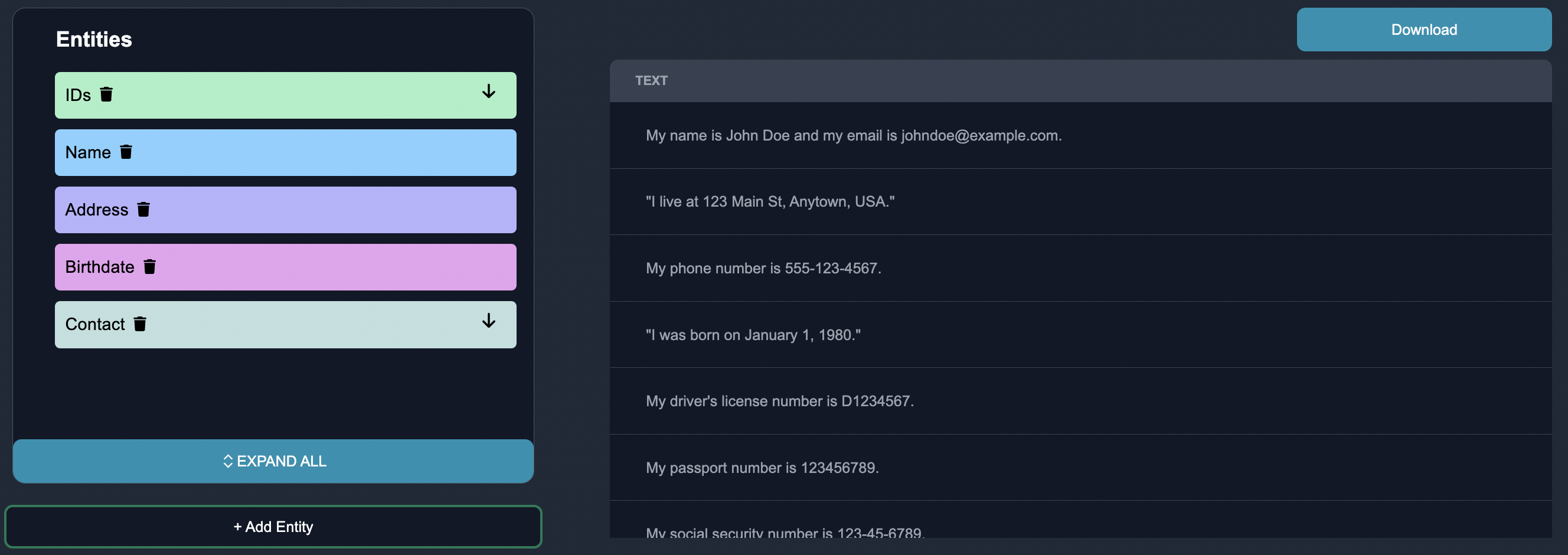
We can also collapse the categories to only see the parent categories.
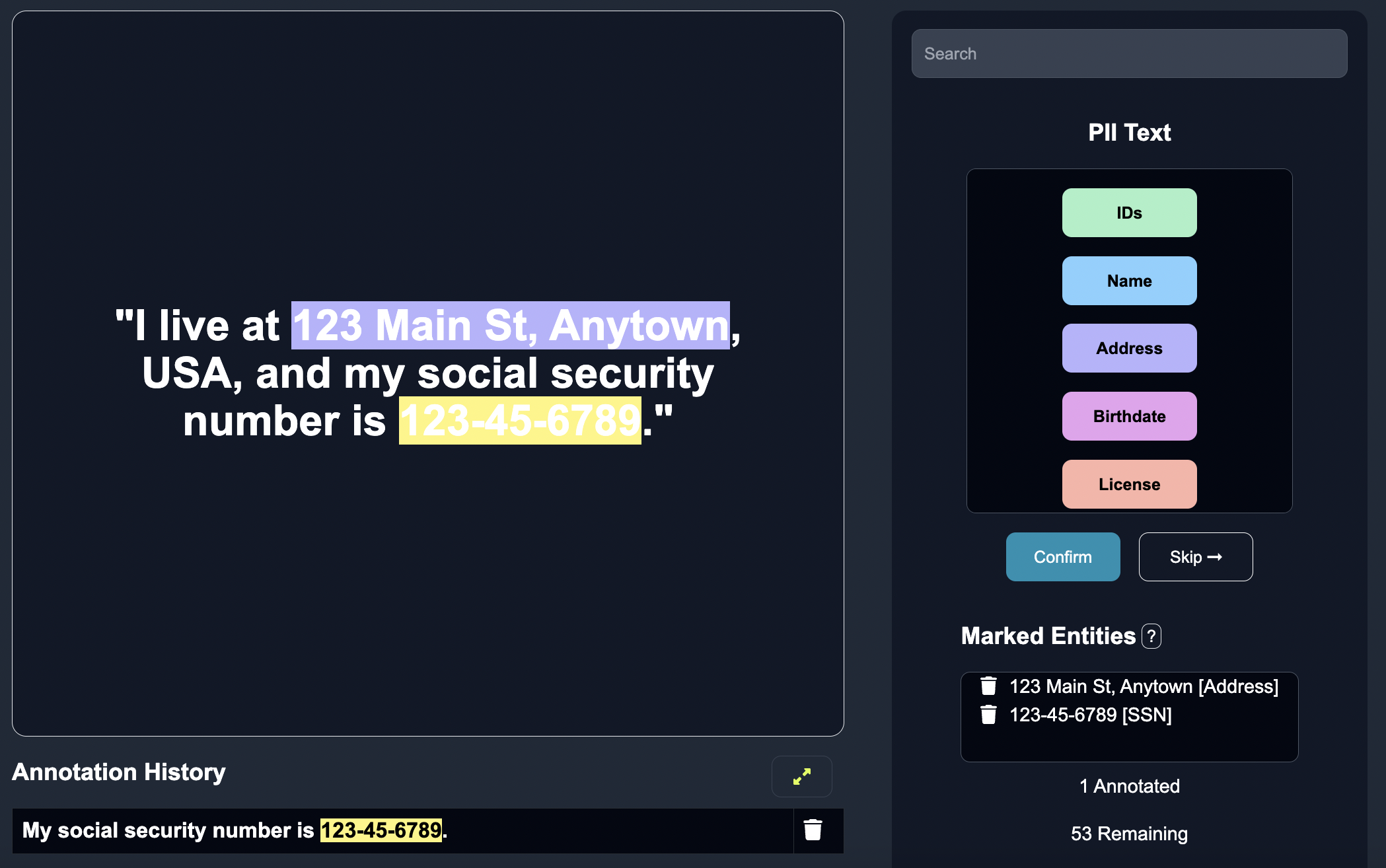
Once confirmed, we can begin annotating, incorporating the previous knowledge to inform our updated entity predictions. Once again, we can highlight over the key words in the text that are indicative of the entity, predict the entity, and click confirm when finished.
Real Time Updates
One important concept regarding Anote is the dynamic nature of our product. As business requirements change, as we add hierarchies and add new categories, our model is able to auto-adjust, incorporating previous knowledge to update the entity predictions synchronously in real time. Here is the resulting download table, from the CSV output.
| Text |
|---|
| My name is [John Doe] (Name). |
| I live at [123 Main St, Anytown, USA] (Address). |
| My phone number is [555-123-4567] (Contact Info: Phone). |
| I was born on [January 1, 1980] (Birthdate). |
| My driver's license number is [D1234567] (IDs: License). |
| My passport number is [123456789] (IDs: Passport). |
| My social security number is [123-45-6789] (IDs: SSN). |
| My credit card number is [1234 5678 9012 3456] (IDs: CreditCard). |
| My medical record number is [MR12345] (IDs: MedicalRecord). |
| My car's license plate number is [ABC 1234] (Vehicle). |
| My IP address is [192.0.2.0] (InternetActivity). |
| My employee ID number is [E12345] (IDs: Employment). |
| My student ID number is [S12345] (Contact Info: Student ID). |
| I can't login to my account, my username is [johndoe] (Contact Info: Username). |
| My VIN is [1HGCM82633A123456] (Vehicle). |
| My biometric ID is [BD12345] (IDs: Biometric). |