Single Layer Classification
Text classification is a machine learning technique that involves categorizing or classifying text documents into predefined categories or classes. It is a common task in natural language processing (NLP) and has various applications, such as sentiment analysis, spam detection, topic labeling, and language identification. In this example, we will demonstrate how to use Anote to solve a text classification problem. We have a dataset of Amazon reviews, and our goal is to classify each review into the appropriate category.
Dataset
This dataset represents a collection of JIRA tickets, with their associated text and category. Each ticket is described by a brief text description, indicating a specific task, issue, or improvement. The dataset consists of two columns:
Text: This column contains the text description of the JIRA ticket. It provides information about the nature of the task or issue being addressed in the ticket.
Category: This column represents the category or classification assigned to each JIRA ticket. It specifies the type or nature of the ticket, such as Bug, Feature, Task, Improvement, or Documentation
| Text | Category |
|---|---|
| Fix login page validation issue | Bug |
| Add search functionality to the website | Feature |
| Implement user profile management module | Task |
| Optimize database queries for better performance | Improvement |
| Update user guide documentation | Documentation |
| Implement email notification system | Feature |
| Fix broken links on the homepage | Bug |
| Create API documentation for integration | Task |
| Improve user interface design | Improvement |
| Write release notes for version 1.2 | Documentation |
| Create automated test scripts | Task |
| Implement file upload functionality | Feature |
| Update installation guide documentation | Documentation |
| Fix formatting issue in the reports module | Bug |
| Optimize memory usage for better scalability | Improvement |
| Improve error handling mechanism | Improvement |
| Create user management module | Task |
| Fix performance degradation issue | Bug |
| Update API reference documentation | Documentation |
| Implement multi-language support | Feature |
| Fix permission issue in the admin panel | Bug |
| Implement social media sharing feature | Feature |
| Create automated build process | Task |
| Improve search functionality speed | Improvement |
| Update user manual documentation | Documentation |
Using Anote
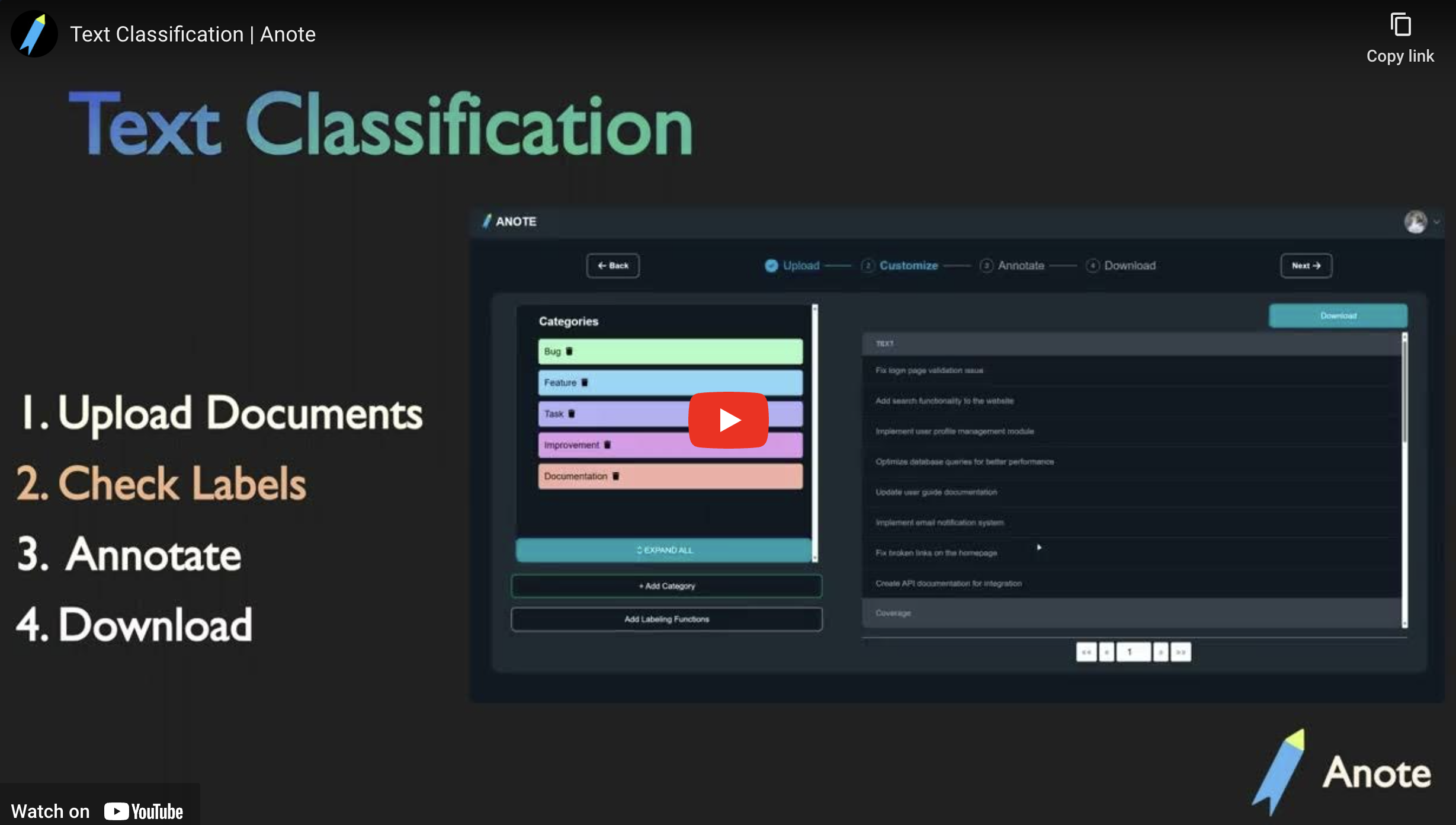
To solve this problem, we can utilize the following steps in Anote:
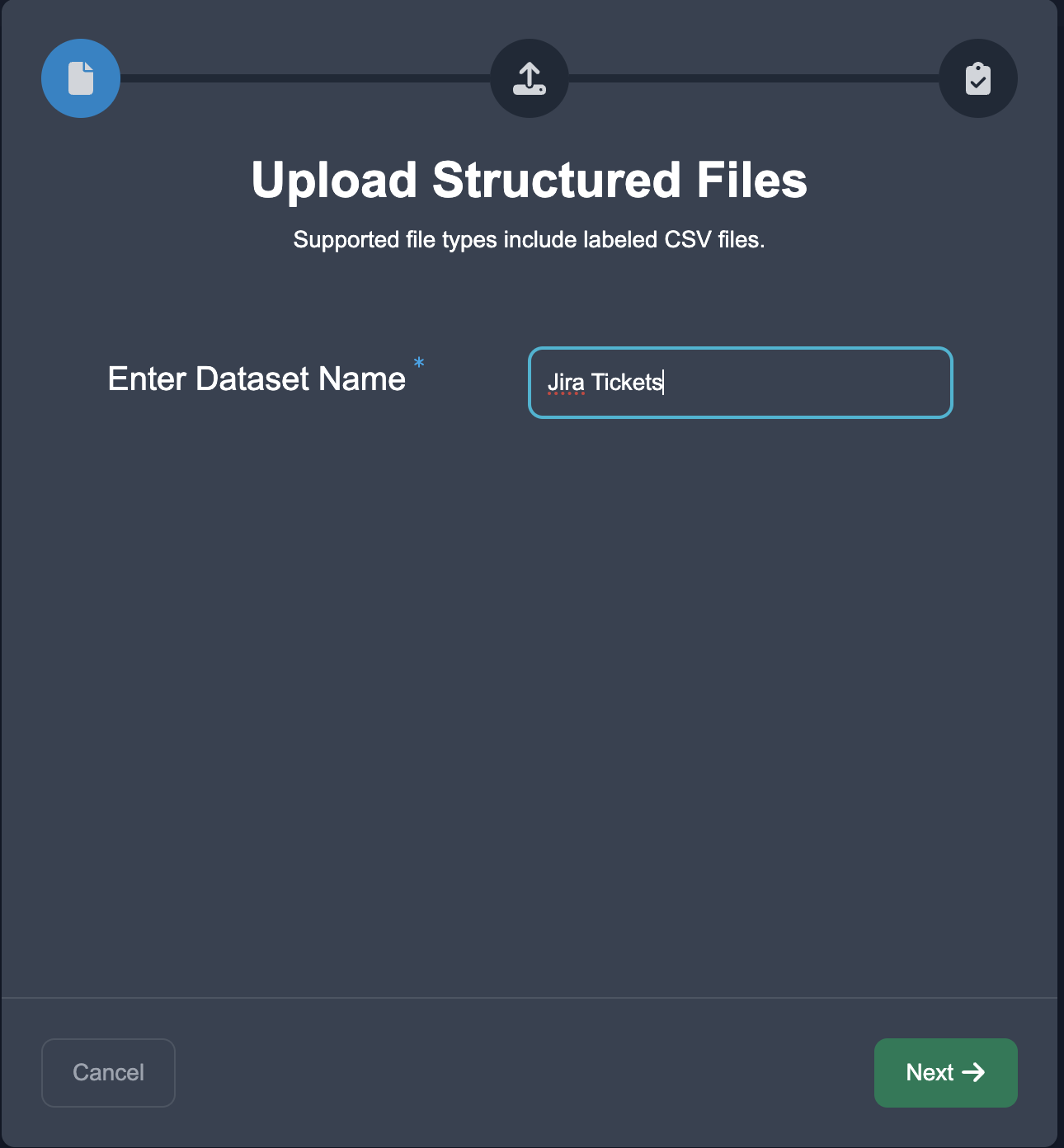
Upload Data: To initiate the process, we begin by uploading our text data. When proceeding to the upload page, make sure to click the Upload Structured button, since our dataset already has labels. Select the NLP Task of Text Classification, and choose the per line decomposition.
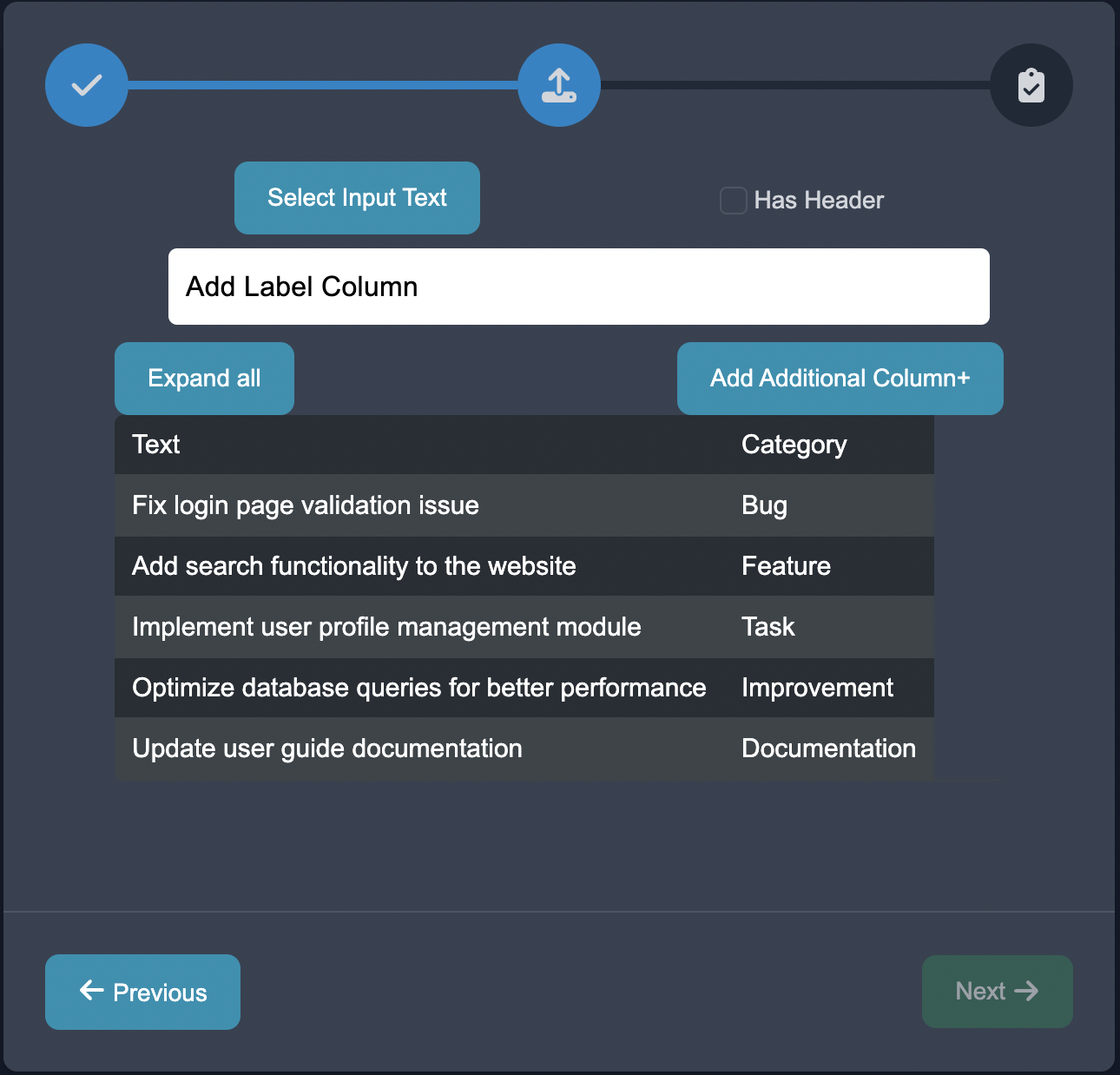
Select the text column, select the label column, assert header is true, and create your dataset.
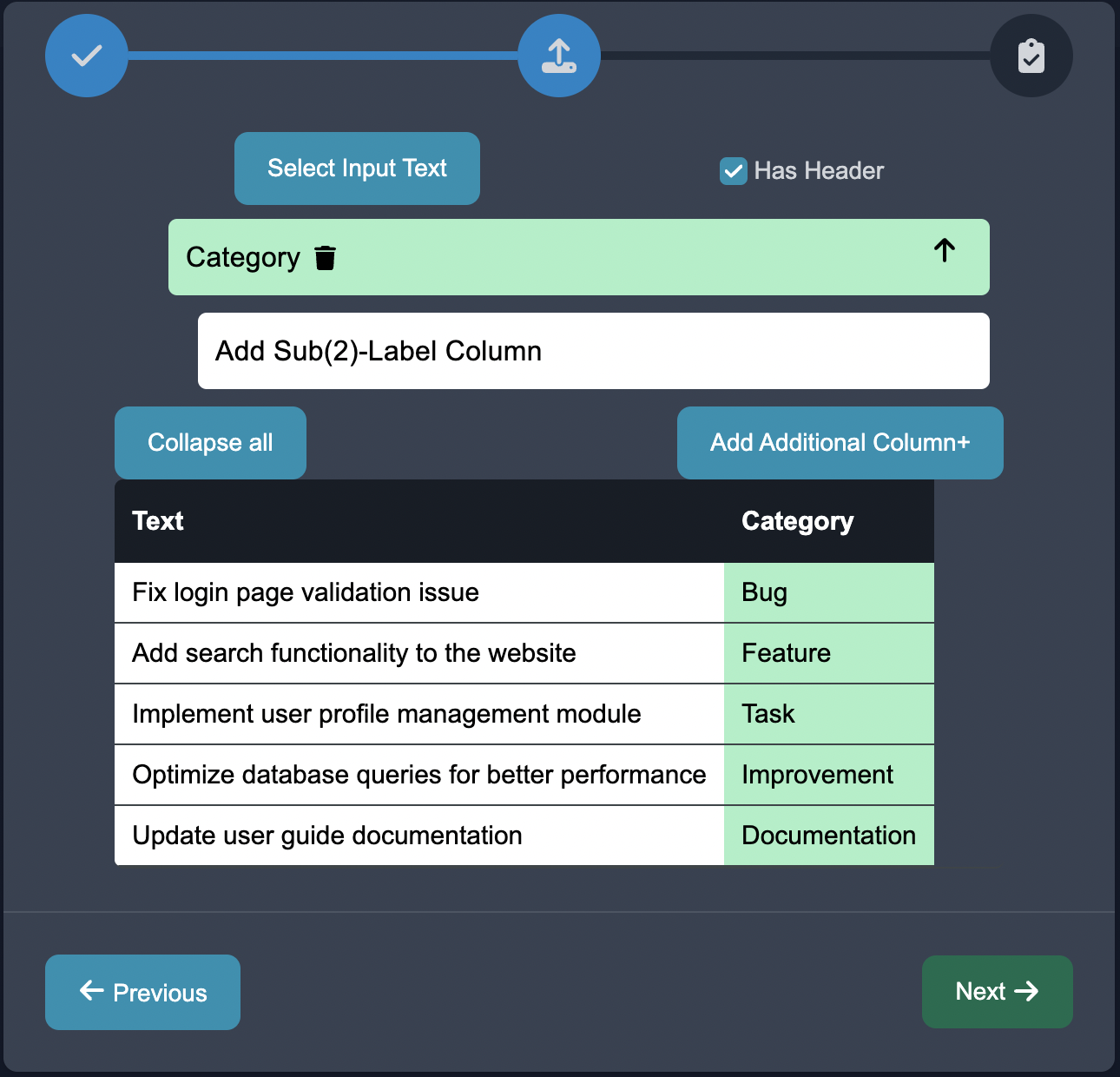
Customize: After you click the Create Dataset button, once the upload succeeds you can navigate to customize. You should see the labels already preloaded from the CSV into your console:
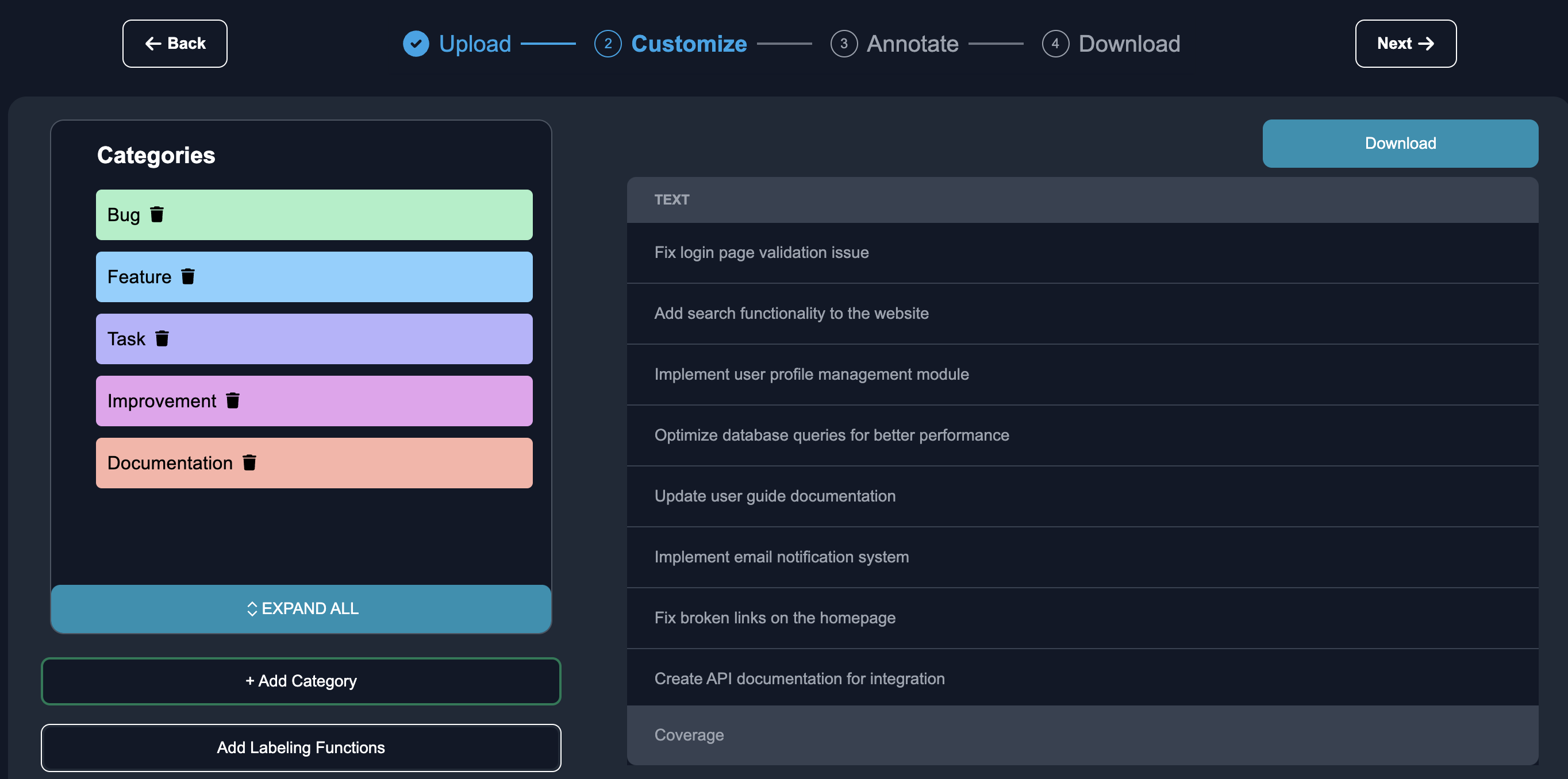
Annotate: We can begin the annotation process. Anote provides an intuitive interface where we can reviews the rows of data that the model predicts to be mislabels, and can annotate the edge cases straight away.
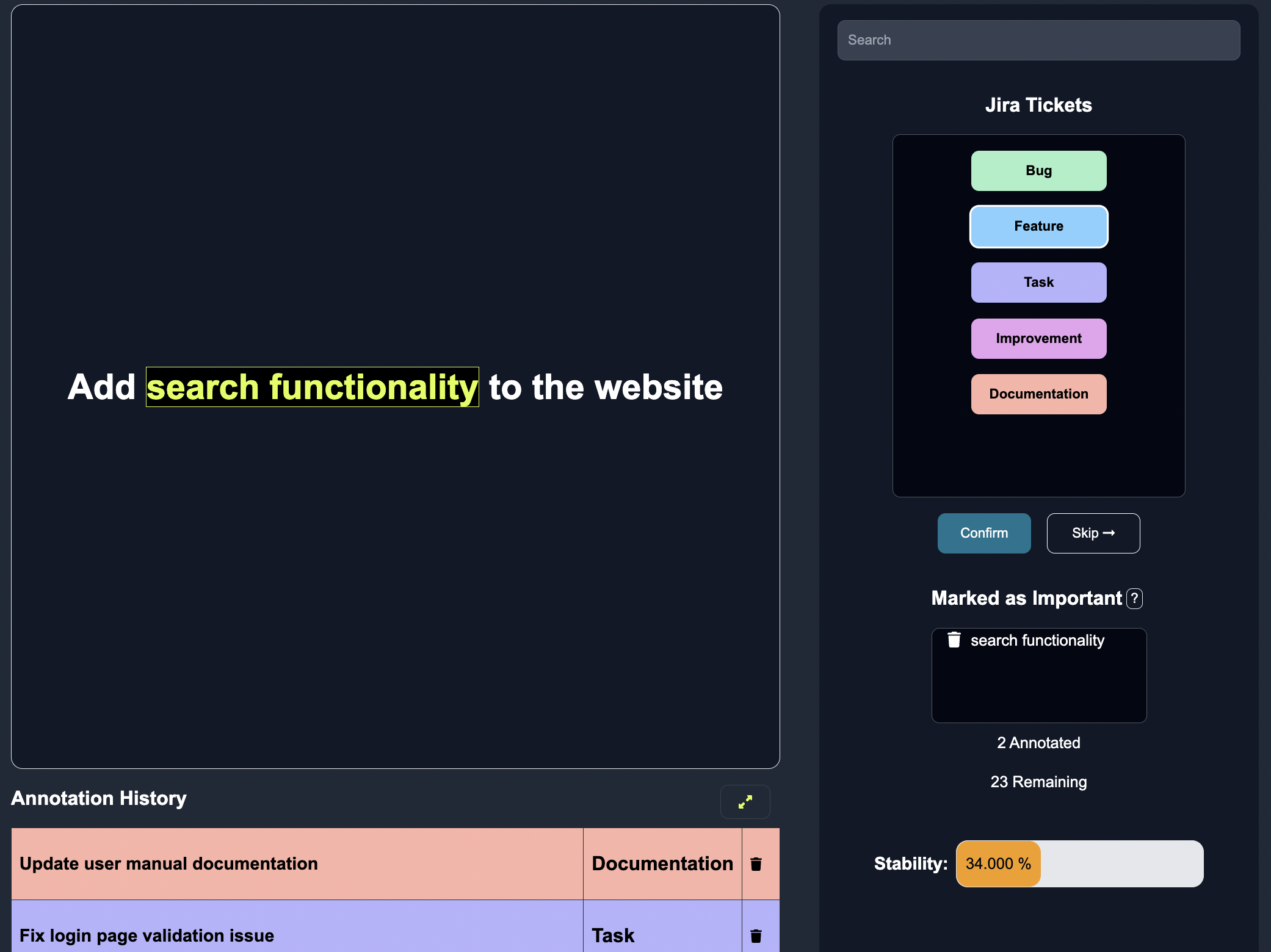
As we label a few reviews, the model actively learns from our input to better predict the label errors within the structured dataset.
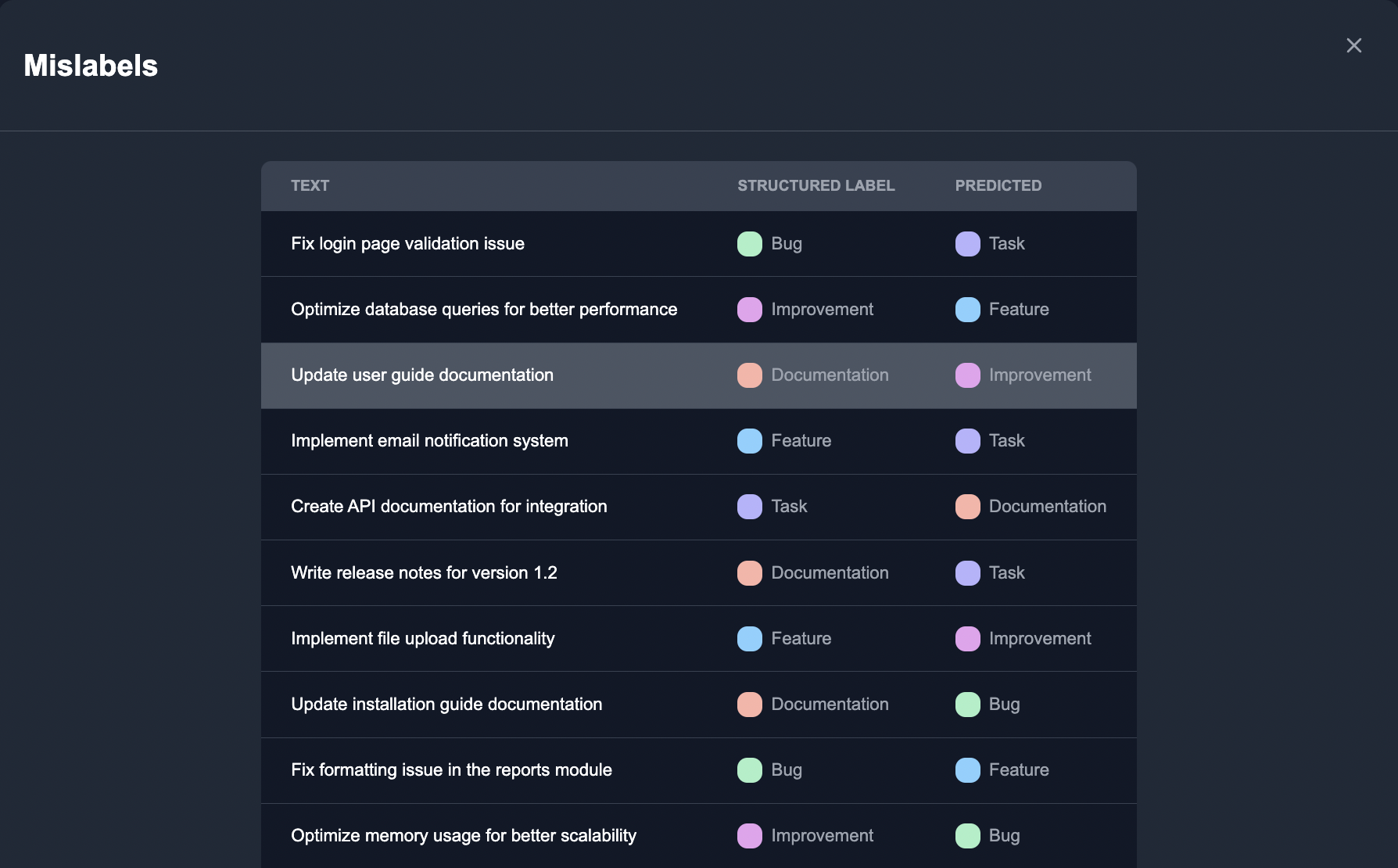
Notice that the model finds that Create API documentation for integration, while labeled Task, should probably be changed to Documentation.
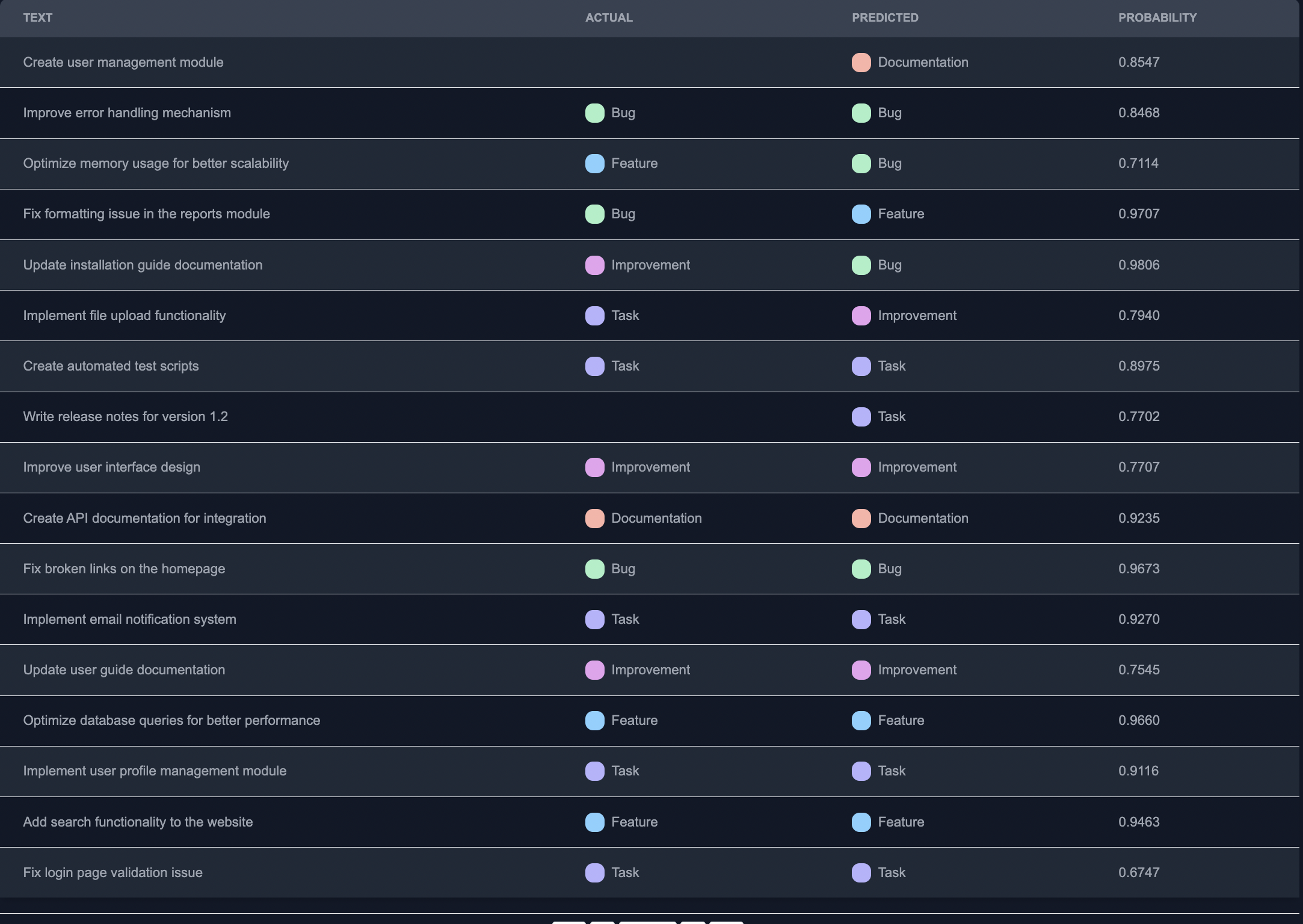
Export Results: Once we are satisfied with the mislabel predictions, we can export the results from Anote. We can choose the desired output format, such as CSV or JSON, and download the annotated data along with the assigned categories.
Summary
Starting with our state of the art zero shot model, and improving over time via human input, Anote is able to classify text really well. This can be very helpful not only for text classification, but also for data validation purposes. Oftentimes, many companies may start with an autolabeling AI model like GPT-3, or may want to review labels made from teams of manual annotators. Data quality is a very important issue, as both autolabeling and manual annotations don't provide sufficient accuracy when ontologies and taxonomies become relatively complex. Via actively learning from human feedback, Anote can quick identify mislabels when classifying text, not only making great inferences, but also making sound predictions of which rows of data you should fix if using alternative means of classifying data.