Analyzing Legal Contracts
Sector: Legal
Capability: Question and Answering

Legal expert Mia aimed to unlock critical information from an extensive collection of legal case studies. However, she found that extracting necessary information from these documents manually was an arduous and time-consuming task. In her quest to streamline the process, she sought the aid of AI. She tested language learning models (LLMs) like ChatGPT to automate data extraction, but the model's general nature impeded accurate extraction of information specific to the legal domain. Thus, Mia sought assistance from Anote to create an effective, AI-enabled solution that could provide accurate responses to complex legal questions and continually improve its performance through human feedback.
To address the problem, a structured process was implemented where the dataset was divided into training and testing data. Initially, ChatGPT's zero-shot capabilities were used to generate preliminary answers for legal questions in the test documents. After these initial predictions, expert legal practitioners reviewed the model's answers and provided feedback, which was used to fine-tune the model and enhance its understanding of the legal questions. This iterative process, which included feedback integration and model fine-tuning, was repeated for each document in the training dataset. This approach gradually refined the model's performance with each document review, resulting in more accurate and higher quality answers.
The results of this approach were evaluated using a pre-defined evaluation set. For each training document feedback was added to, feedback was evaluated on 25 testing dataset documents. After multiple iterations, the model demonstrated significantly improved ability to derive insights from legal documents. This approach proved to be effective with both private and public LLMs, catering to different data security needs. Ultimately, this solution revolutionized the way legal data was processed. By automating the process, it drastically reduced the time and effort required to manually review and extract information, leading to increased efficiency and productivity.
Example: Human Feedback for Legal Contract Analysis
Analyzing legal contracts is a complex task that requires understanding specific clauses, terms, and legal language. Leveraging the power of large language models (LLMS) like ChatGPT with semi-structured prompting can enhance the accuracy and efficiency of contract analysis. Here is an example of how semi-structured prompting on legal contracts can work on Anote, where we can ask questions on legal contracts, and leverage human input to refine the predictions of LLMs. Let's show how we can use Anote to do this:
Upload Data
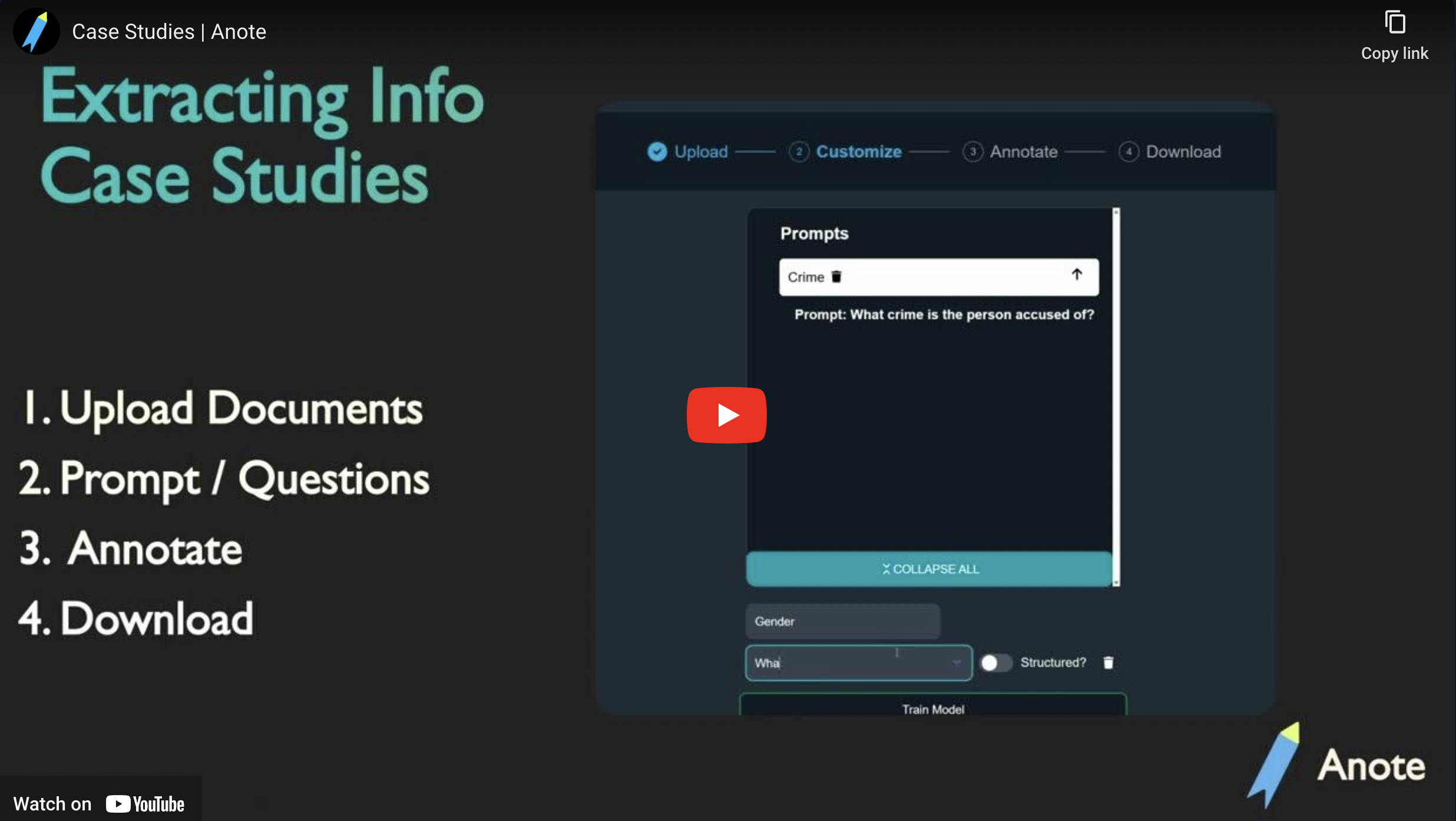
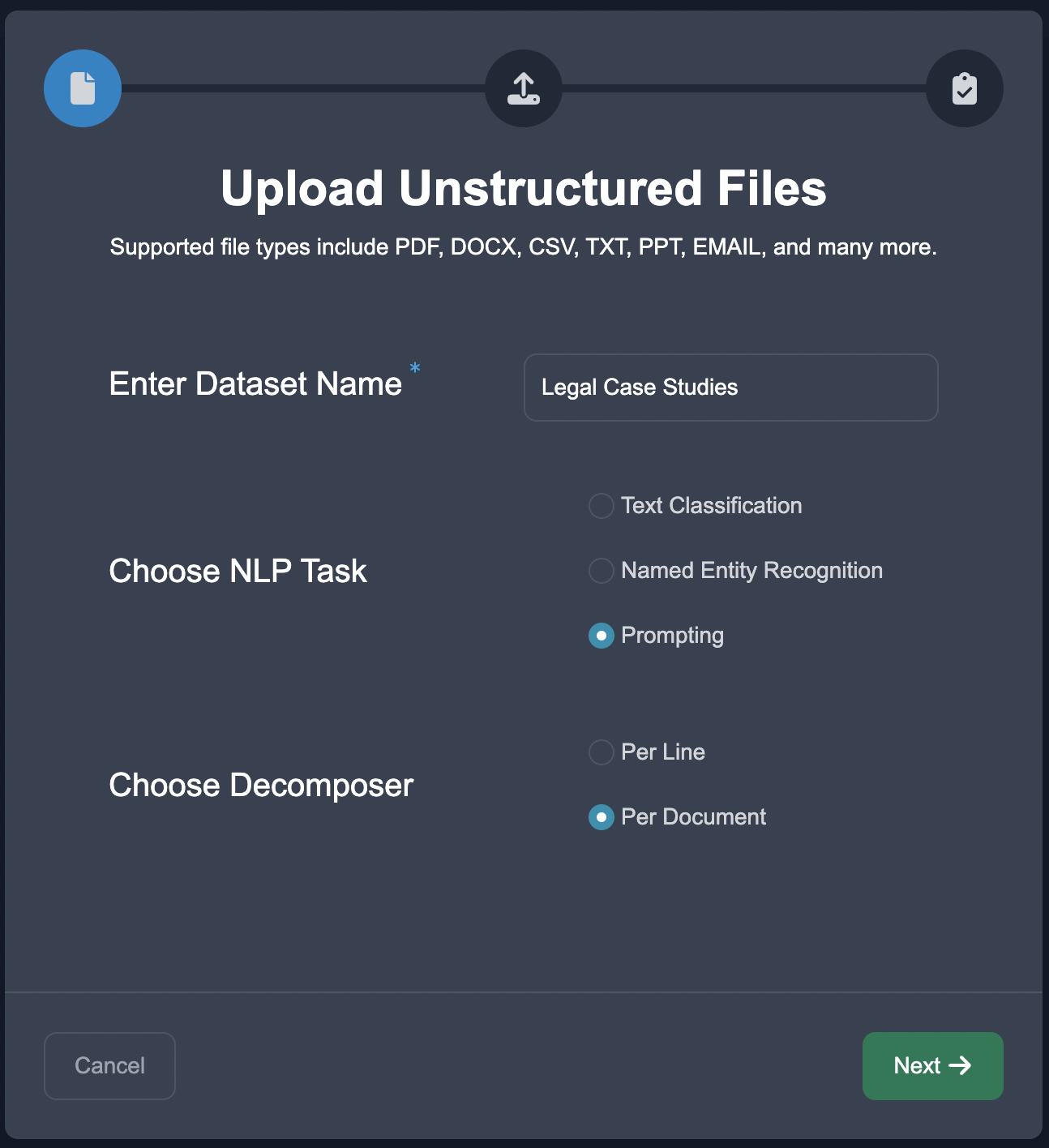
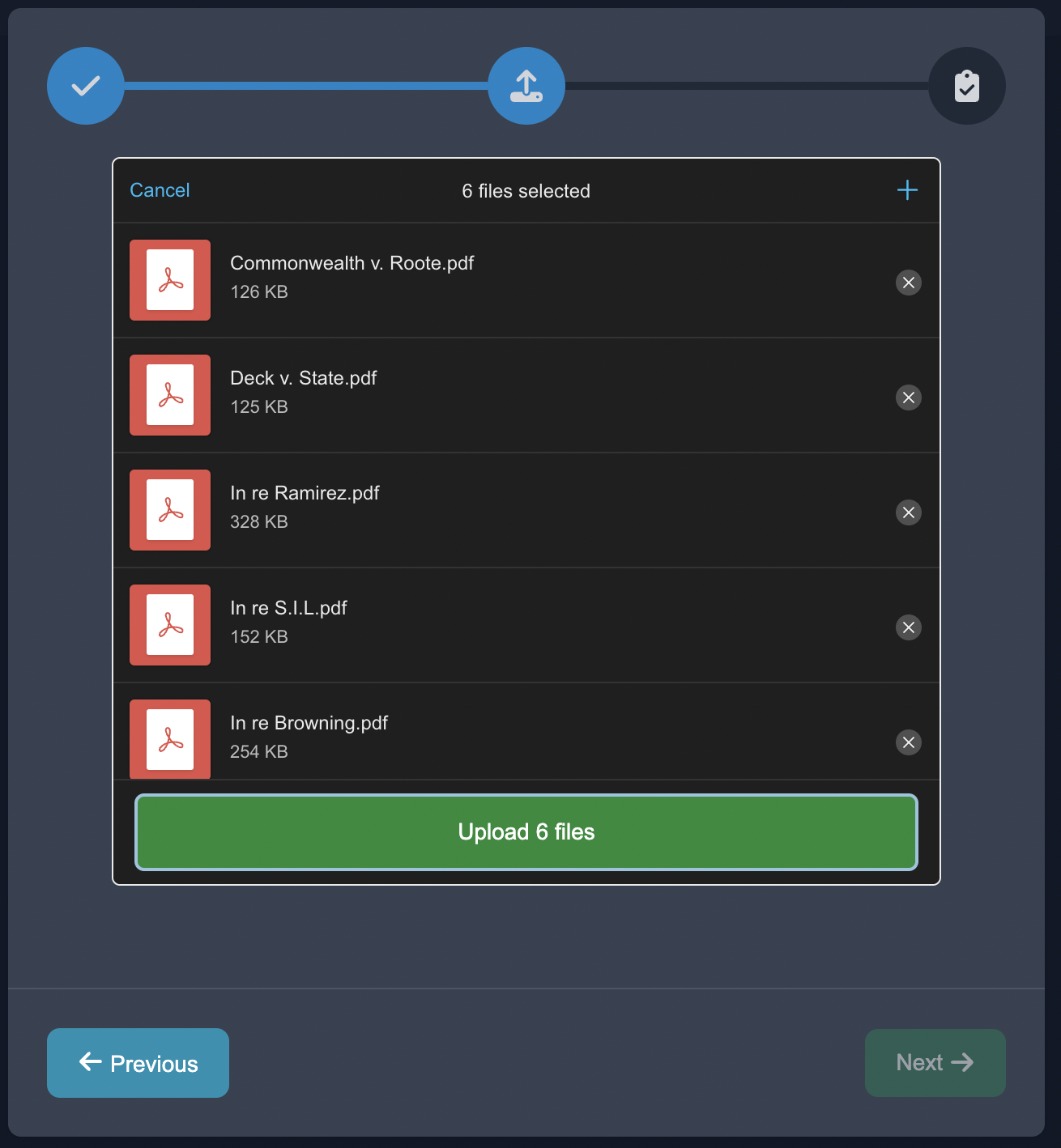
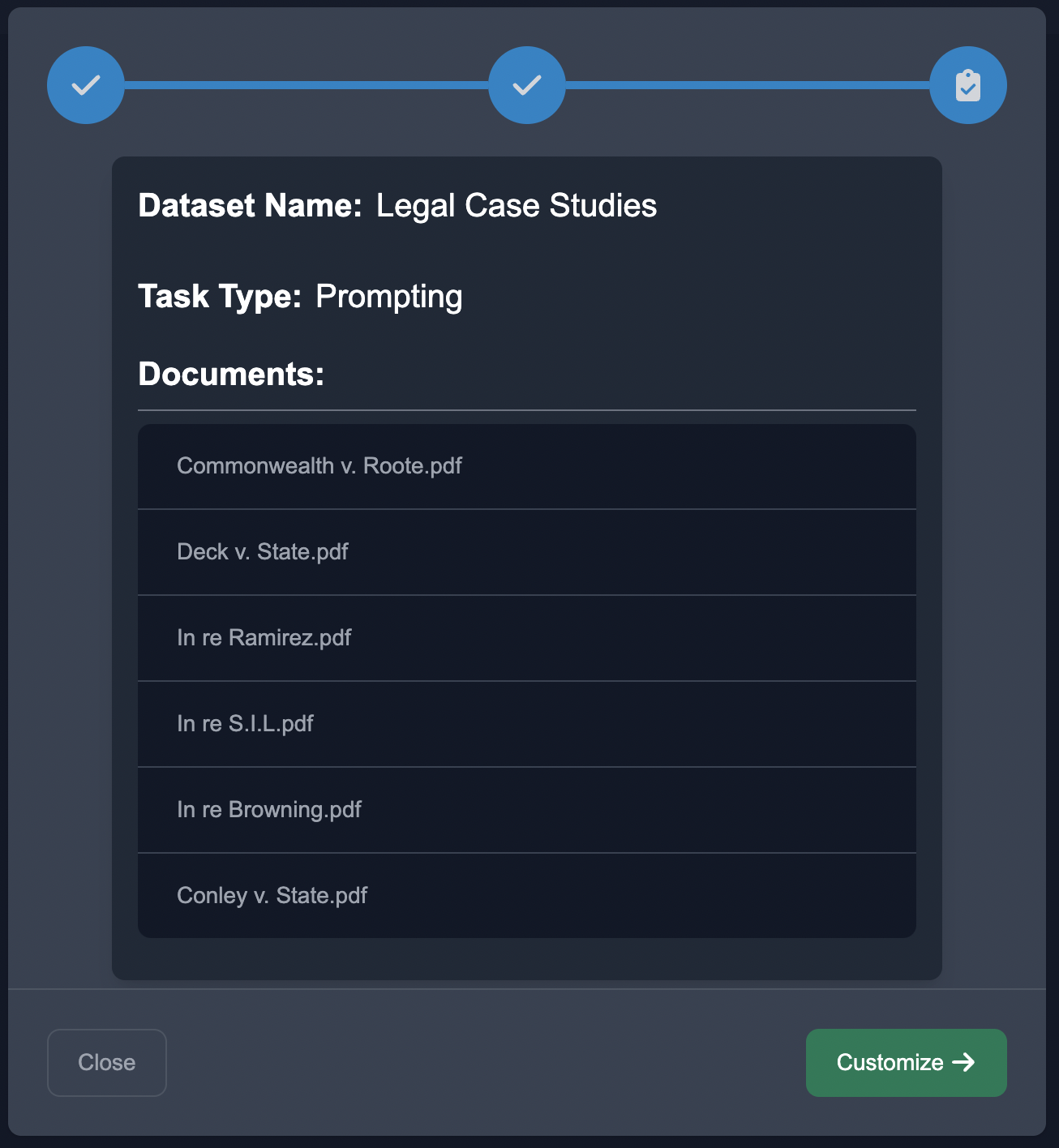
Start by uploading the case studies in the Upload Unstructured format, choose the NLP task of Prompting, and choose the document decomposition.
Customize Questions
Input the relevant questions for the case studies. On Anote, there are two main types of questions, Unstructured Question and Structured Questions.
Unstructured Questions - Open-Ended Questions
Open-ended questions allow users to query specifics or seek clarifications:
- "Can you simplify the termination provisions in this contract?"
- "Explain the non-compete clause in layman's terms."
Structured Questions - Categorical Questions
Categorical question, such as Yes/no or multiple choice questions provide confirmations or clarifications:
- "Is there a confidentiality agreement in this contract?"
- "Does the contract include a severability clause?"

Annotate
Insert human feedback via inputing the relevant structured and unstructured answers for the questions in the case studies.
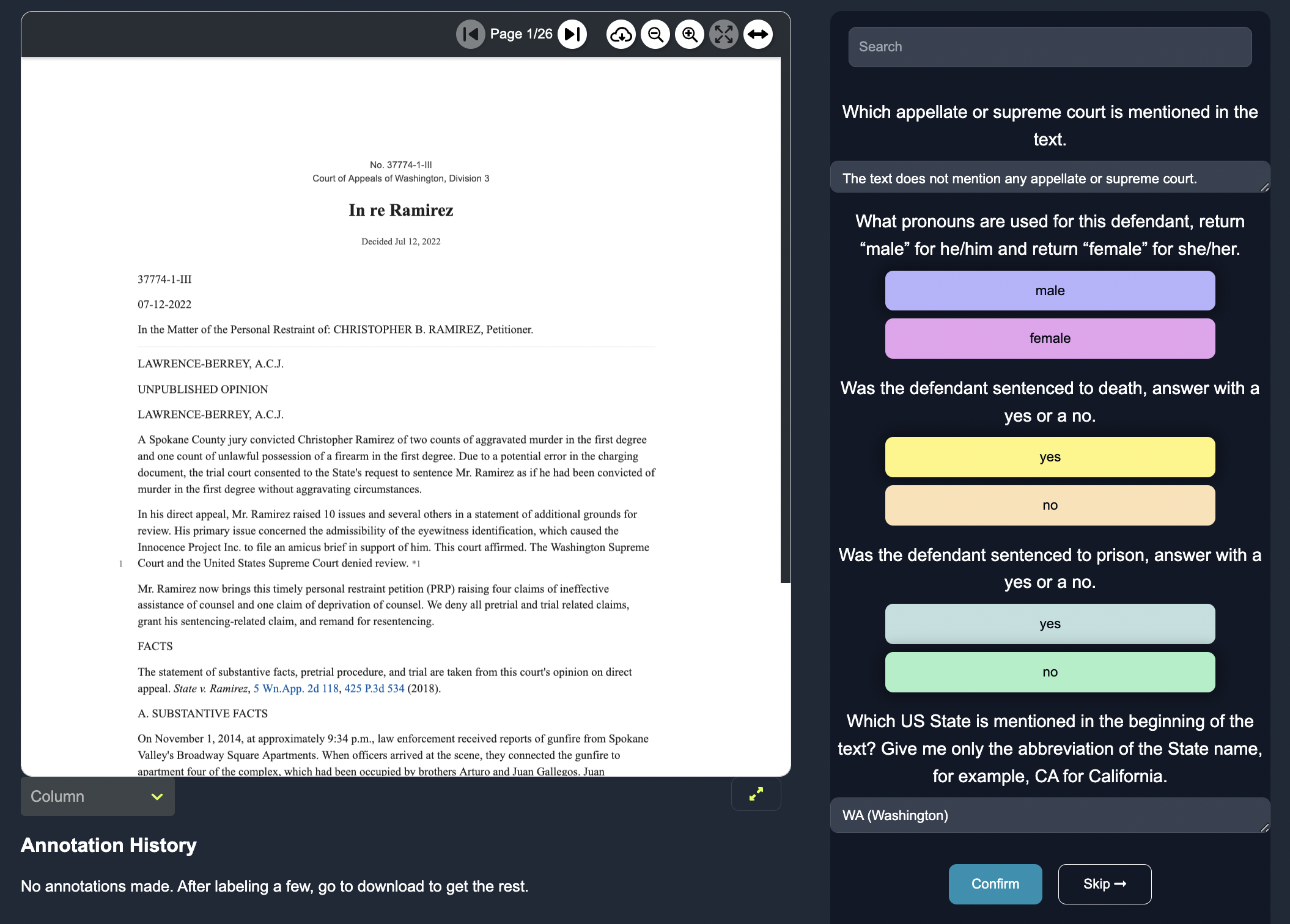
Learning from Feedback: A Path to Improvement
By analyzing user feedback on the generated responses, we can pinpoint discrepancies, inaccuracies, or gaps in information. This crucial feedback sharpens the language model's comprehension and bolsters its contract analysis performance.
Here is an example of how this would look on the Anote interface:
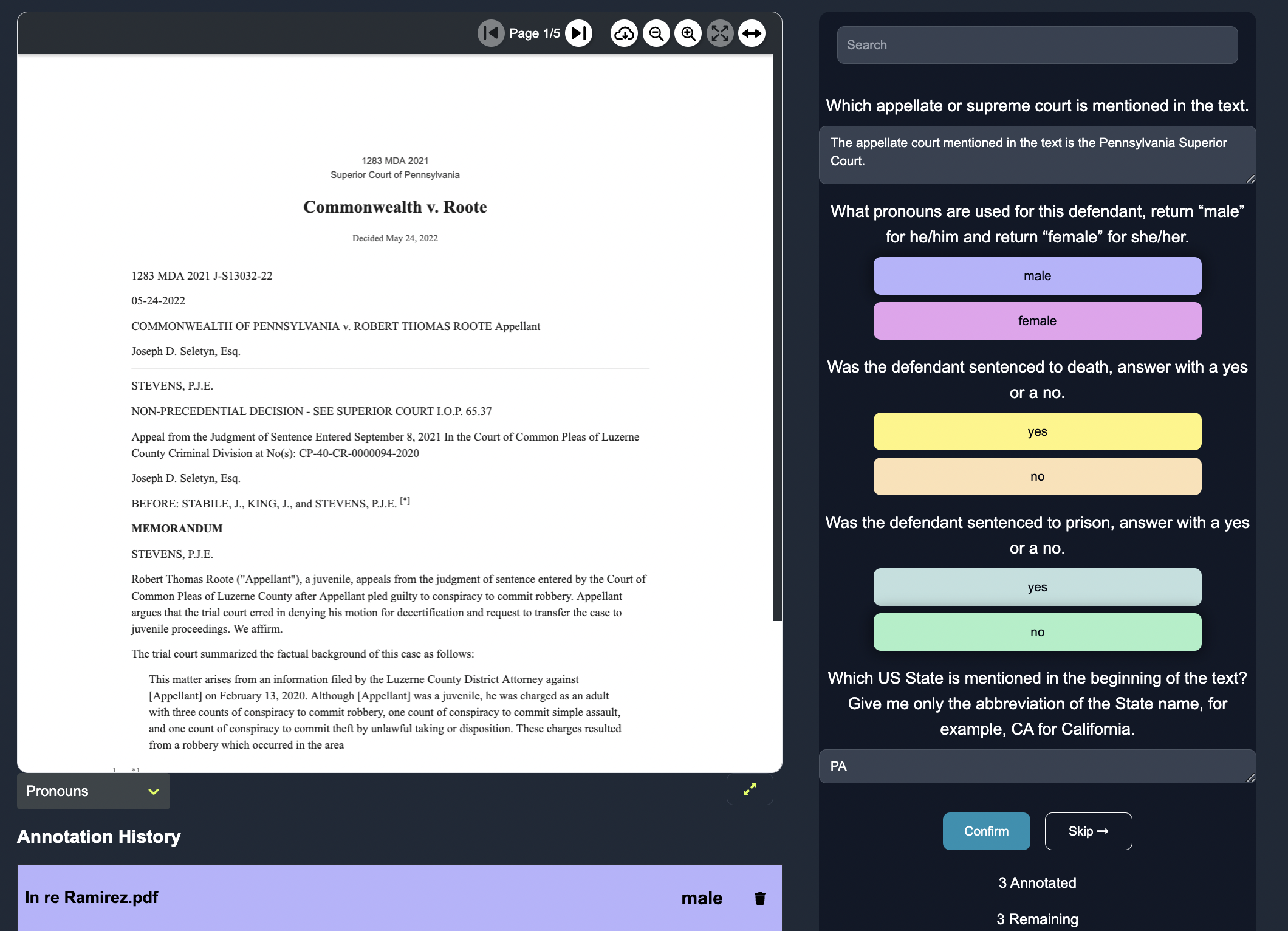
The model responds based on its understanding of the contract, actively learning and refining its knowledge through user feedback. The model's responses, validated and corrected through user feedback, ensure higher accuracy than the zero shot models, and improve per iteration.
Refinement Through Iteration
The process of iterative refinement forms a feedback loop that fosters continuous learning and improvement in contract analysis. By assimilating user feedback on each annotation, modifying prompts, and calibrating the model, we continually enhance its accuracy, deepen its legal understanding, and enrich its capacity to deliver pertinent insights. This ongoing process underscores our commitment to accuracy and continuous improvement in our AI-driven legal contract analysis services. At Anote we emphasize continuous improvement of our existing models, leveraging human feedback on model outputs, enabling users to rectify incorrect responses. Here are a few examples:
Example: User feedback helped the model to include "third-party claims" in its explanation of an "indemnity clause".
Example: User feedback corrected the model's misinterpretation of a "force majeure clause", improving its comprehension.
This process enhances the model's learning as corrected responses feedback into the system, resulting in the model's accuracy and efficiency improving over time.
Download Results
When finished annotating, you can download the results from the legal case study. Below, you can see both the predicted results from the model, as well as the actual answers from the annotators / subject matter experts.
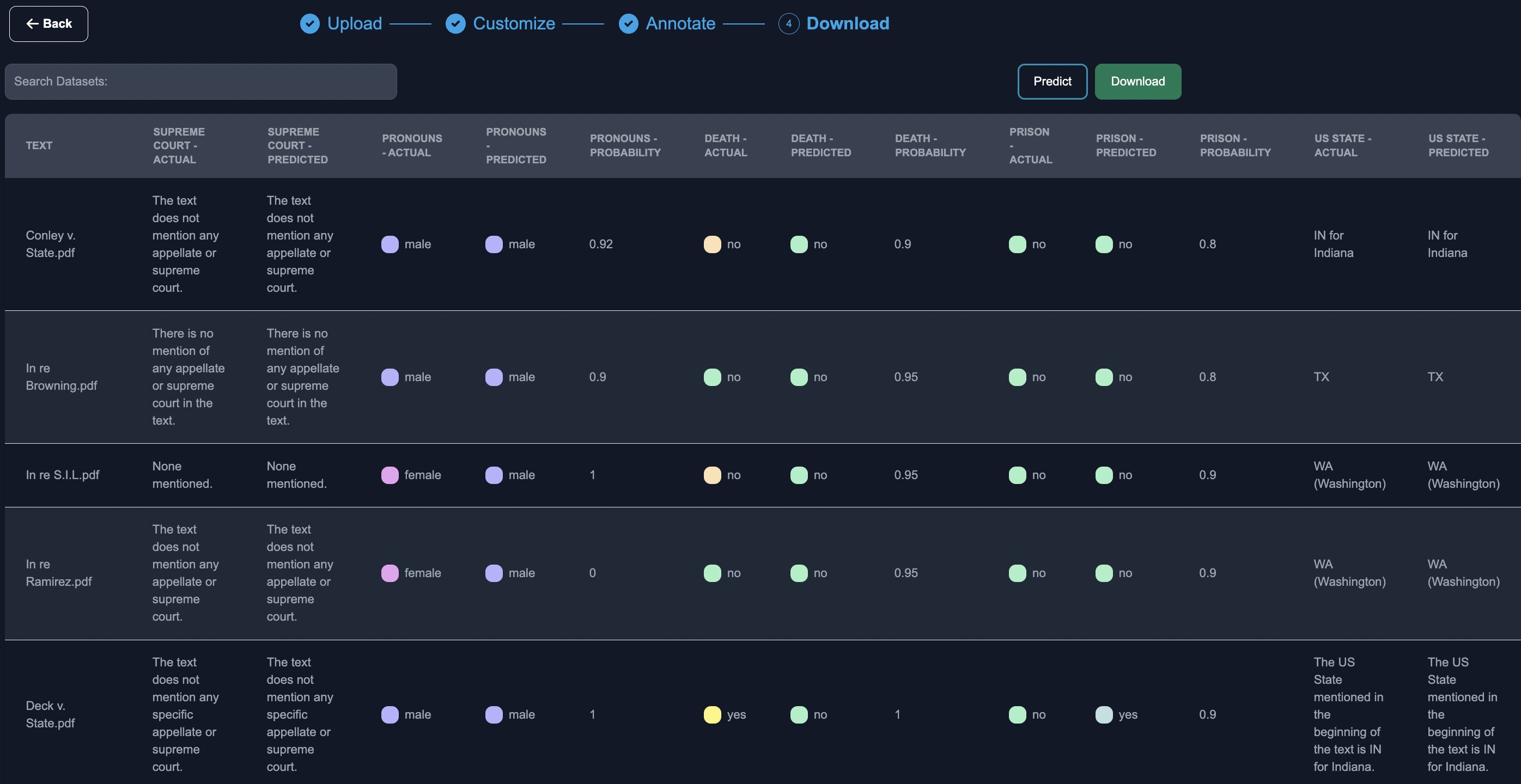
You can download the final results in CSV format.
