Few Shot Text Classification
Few-shot text classification is an approach that enables accurate classification of text data with only a few labeled examples. Traditional supervised learning methods rely on large amounts of labeled data to train models effectively. However, in many real-world scenarios, obtaining a vast amount of labeled data can be time-consuming, costly, or simply not feasible.
Few-shot learning techniques aim to address this limitation by leveraging pretrained language models and innovative training strategies. SetFit is one such approach that we will delve into, offering an efficient framework for few-shot fine-tuning of Sentence Transformers.
SetFit: Efficient Few-Shot Learning with Sentence Transformers
SetFit is an efficient framework for few-shot fine-tuning of Sentence Transformers, developed by Hugging Face in collaboration with Intel Labs and the UKP Lab. It leverages pretrained language models to achieve high accuracy even with minimal labeled data, making it a powerful tool for various natural language processing tasks.
How SetFit Works
SetFit stands out as a powerful solution for few-shot text classification. It combines the strengths of Sentence Transformers, which generate dense embeddings for text data, with a two-stage training process. Here's how SetFit works:
-
Stage 1: Fine-tuning Sentence Transformers: In the initial stage, SetFit fine-tunes a pretrained Sentence Transformer model on a small number of labeled examples. Contrastive training is employed, creating positive and negative pairs through in-class and out-class selection. This process enhances the model's ability to encode meaningful representations for text examples.
-
Stage 2: Training the Classification Head: After fine-tuning the Sentence Transformer, SetFit trains a classification head on the encoded embeddings generated in the previous stage. The classification head learns to associate the embeddings with their respective class labels, enabling accurate classification of unseen text examples.
By following this two-stage training process, SetFit achieves impressive accuracy with minimal labeled data, making it an efficient and effective approach for few-shot text classification tasks.
End to End Example of Setfit
from datasets import load_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer, sample_dataset
# Load a dataset from the Hugging Face Hub
dataset = load_dataset("sst2")
# Simulate the few-shot regime by sampling 8 examples per class
train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
eval_dataset = dataset["validation"]
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-mpnet-base-v2",
use_differentiable_head=True,
head_params={"out_features": num_classes},
)
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=16,
num_iterations=20, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for contrastive learning
column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
)
# Train and evaluate
trainer.freeze() # Freeze the head
trainer.train() # Train only the body
# Unfreeze the head and freeze the body -> head-only training
trainer.unfreeze
Benchmarking SetFit
| Rank | Method | Accuracy | Model Size |
|---|---|---|---|
| 2 | T-Few | 75.8 | 11B |
| 4 | Human Baseline | 73.5 | N/A |
| 6 | SetFit (Roberta Large) | 71.3 | 355M |
| 9 | PET | 69.6 | 235M |
| 11 | SetFit (MP-Net) | 66.9 | 110M |
| 12 | GPT-3 | 62.7 | 175B |
Results
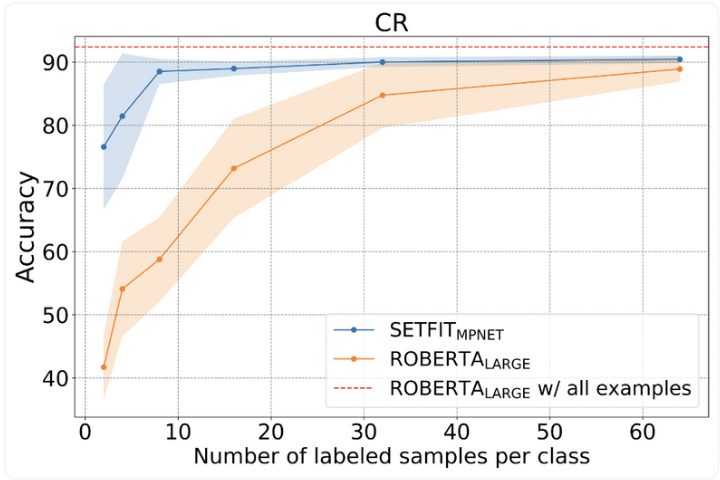
SetFit achieves impressive results with only a few labeled examples, delivering high accuracy for specific text classification tasks across various domains and verticals. The following benchmarks showcase SetFit's performance on popular datasets:
- SST-5: SetFit demonstrates remarkable accuracy on the Stanford Sentiment Treebank (SST-5) dataset, showcasing its effectiveness in sentiment analysis tasks.
- Emotions: SetFit achieves high accuracy in classifying emotional states, making it valuable for applications requiring emotion recognition.
- AmazonCF: SetFit performs well in classifying customer reviews on the AmazonCF dataset, enabling sentiment analysis for e-commerce platforms.
- Enron Spam: SetFit effectively distinguishes spam emails from legitimate ones in the Enron Spam dataset, showcasing its ability in email classification tasks.
- Ag News: SetFit demonstrates reliable performance in classifying news articles on the Ag News dataset, providing efficient topic classification capabilities.
Fast training and inference
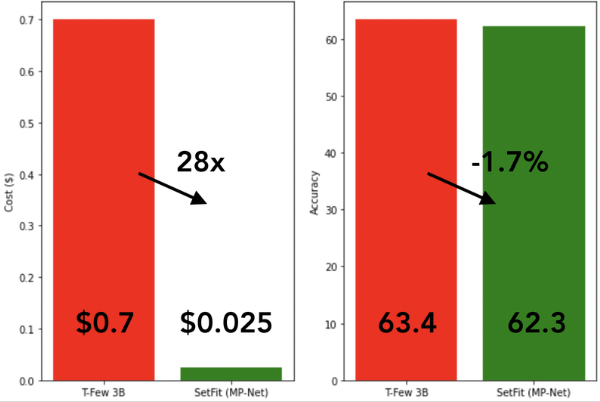
Since SetFit achieves high accuracy with relatively small models, it's blazing fast to train and at much lower cost. For instance, training SetFit on an NVIDIA V100 with 8 labeled examples takes just 30 seconds, at a cost of $0.025. By comparison, training T-Few 3B requires an NVIDIA A100 and takes 11 minutes, at a cost of around $0.7 for the same experiment - a factor of 28x more. In fact, SetFit can run on a single GPU like the ones found on Google Colab, and you can even train SetFit on CPU in just a few minutes! As shown in the figure above, SetFit's speed-up comes with comparable model performance. Similar gains are also achieved for inference, and distilling the SetFit model can bring speed-ups of 123x.
The Siamese Network
The Siamese Network is a popular approach in few-shot learning and text classification tasks. While it offers certain strengths, it also presents weaknesses that SetFit addresses.
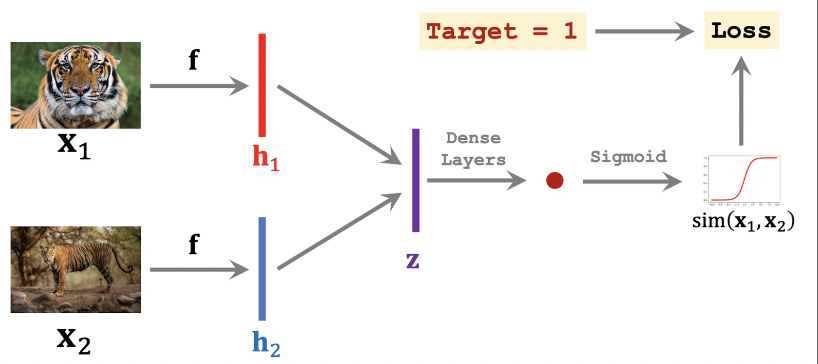
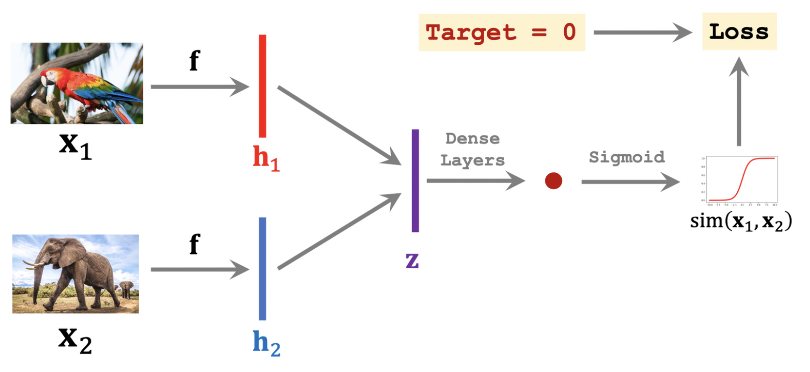
Strengths
Here's an overview of the strengths of Siamese Networks:
- High Degree of Accuracy with Few Labels: Siamese Networks excel in achieving high accuracy even with a limited number of labeled examples. This makes them suitable for few-shot learning scenarios.
- Smaller and Cost-Effective: Siamese Networks are generally smaller in size compared to large language models like GPT-3. They offer a more cost-effective solution for training models, as they require fewer computational resources and reduced training time.
SetFit leverages the strengths of Siamese Networks. By combining efficient training strategies with Sentence Transformers, SetFit achieves high accuracy even with limited labeled data, making it a powerful alternative to traditional language models.