Identifying Mislabeled Emotions
Sector: Big Tech
Capability: Identifying Mislabels


Kenneth, an employee at Amazon, encountered a challenge: determining the specific emotion associated with a given Amazon review. Emotions such as joy, annoyance, anger, love, approval, sadness, surprise, neutral, optimism, etc. needed to be identified. To address this, Kenneth employed a pre-trained model based on Google's GoEmotion dataset, which consisted of 58,000 Reddit comments manually labeled with emotions. He then attempted to fine-tune the model using the Amazon Reviews dataset. Despite implementing a BERT model from Tensorflow Hub, Kenneth's model exhibited inexplicable errors and achieved only 82% accuracy.
To investigate the cause of this underperformance, Kenneth manually examined 1,000 data points in the structured GoEmotion dataset. His analysis revealed that 308 of these data points contained labeling errors, resulting in an error rate exceeding 30%. Committed to improving the model, Kenneth spent approximately two days manually rectifying these label errors. As a result, his fine-tuned model experienced a remarkable boost, reaching an accuracy of 87%.
Kenneth expressed satisfaction with the 5% improvement in model performance. However, when scrutinizing the incorrect predictions made by the fine-tuned model on the Amazon Reviews dataset, he realized that many of the labels assigned to the reviews were questionable. While his model performed admirably, the training data (Reddit GoEmotion) and fine-tuning data (Amazon Reviews) were plagued with label errors, which ultimately hampered its overall performance. Lets see if we can use Anote to do better, find mislabels, and improve performance.
Upload Data
Start by uploading the CSV in the Upload Structured format, enter the name of the dataset emotions.
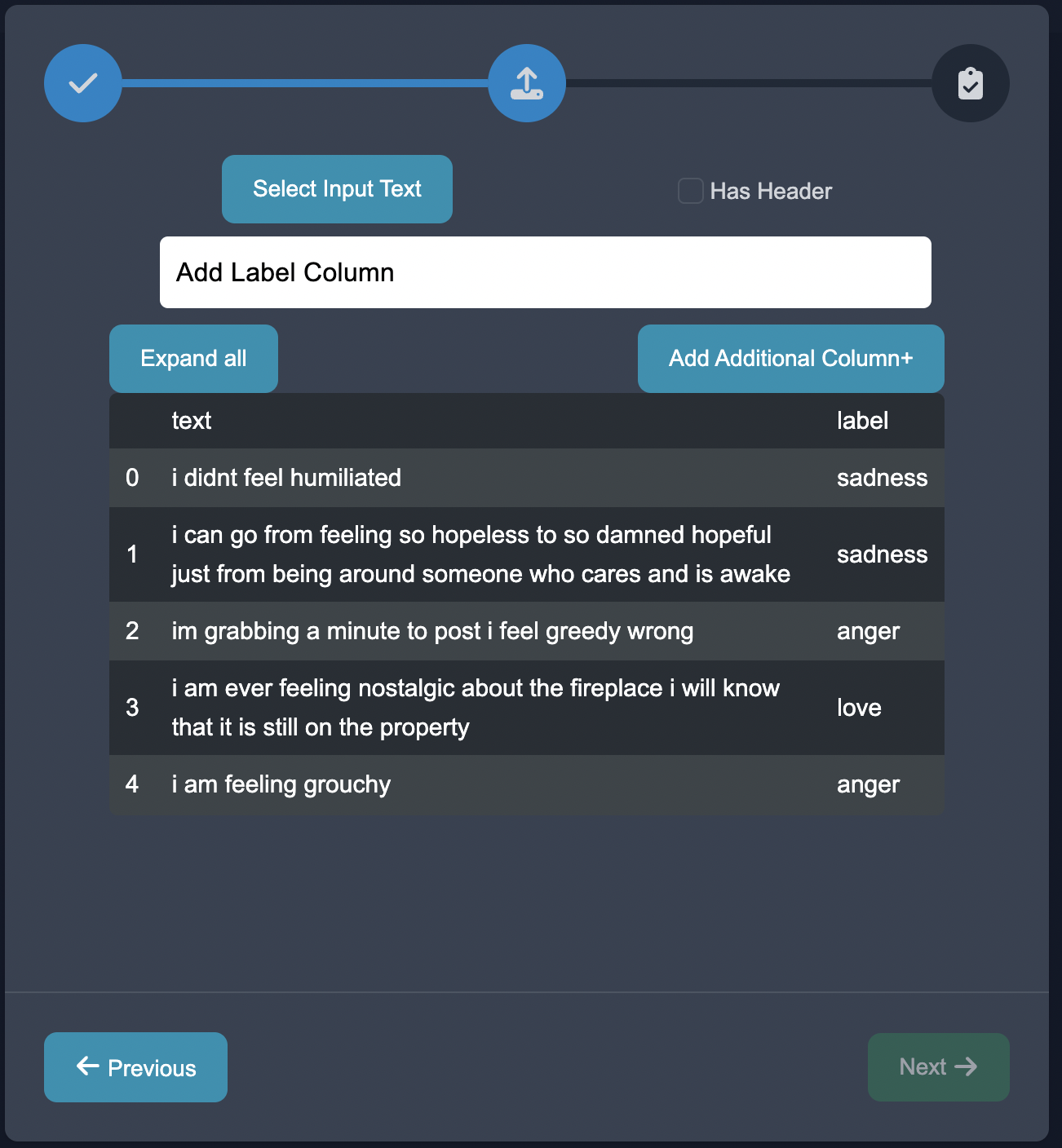
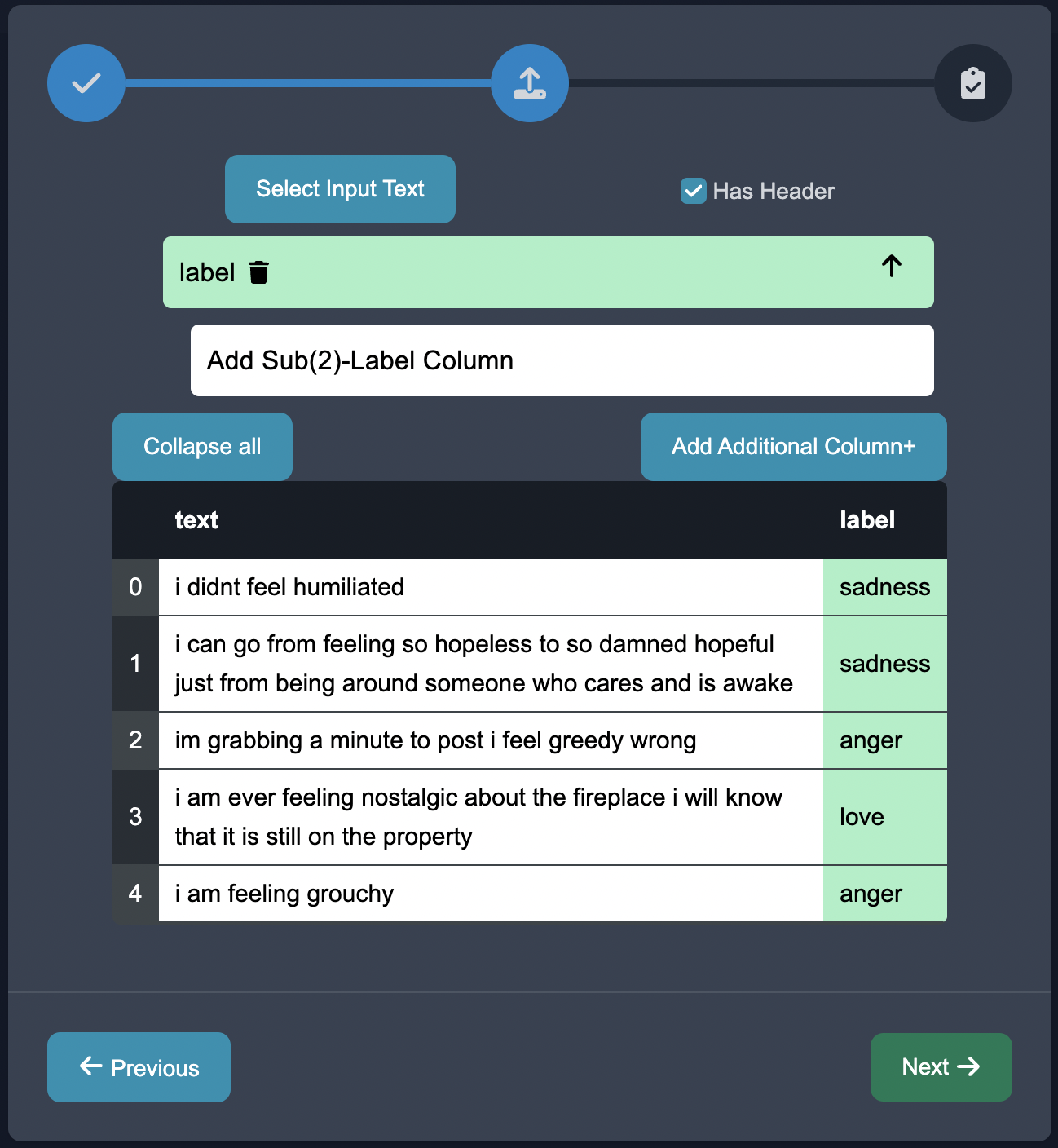
Select the text column as the text, and the emotions label column as the label.
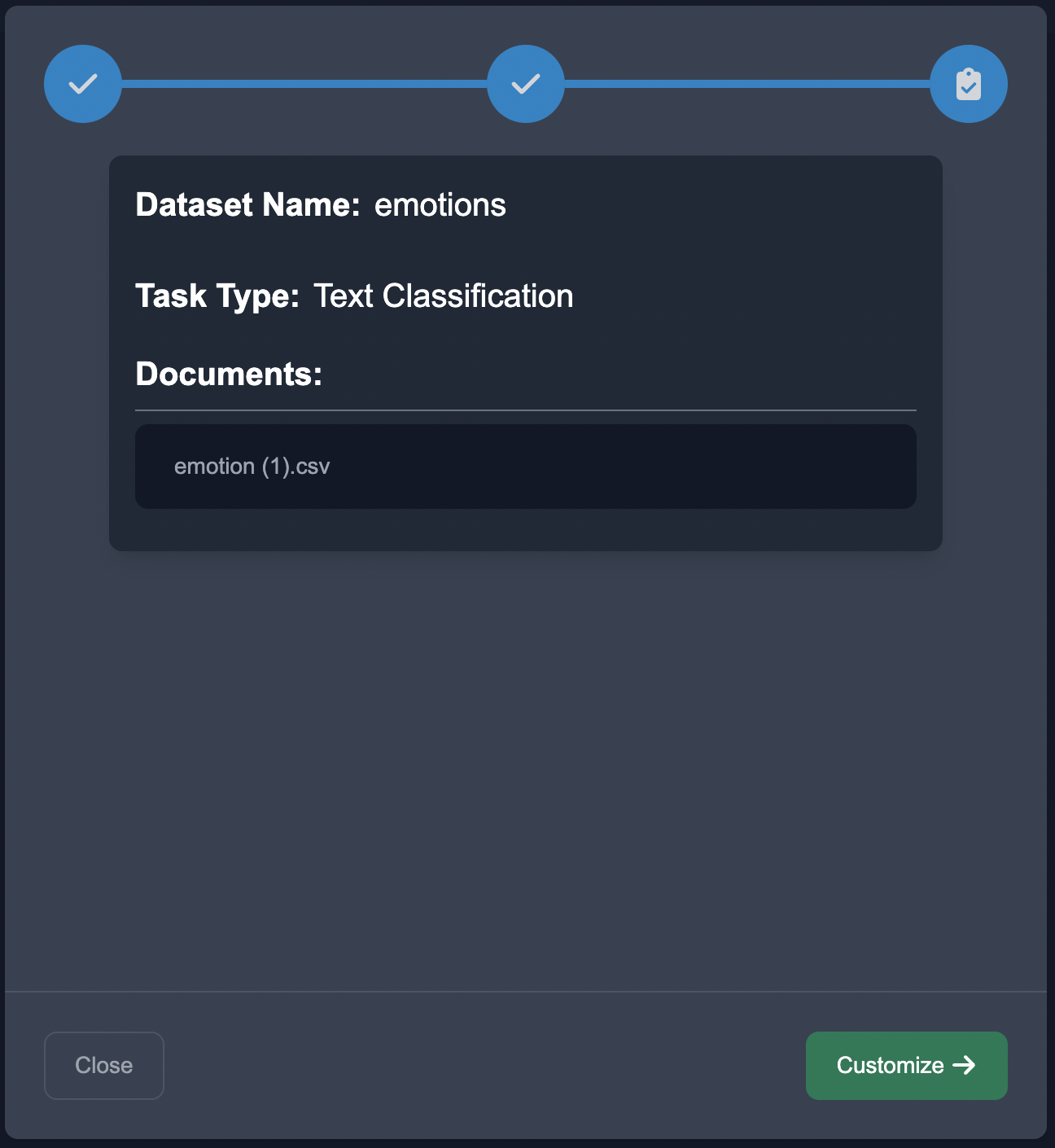
On press of the next button the dataset is now uploaded.
Customize Questions
Because this is a structured dataset, the emotions are already prefilled.
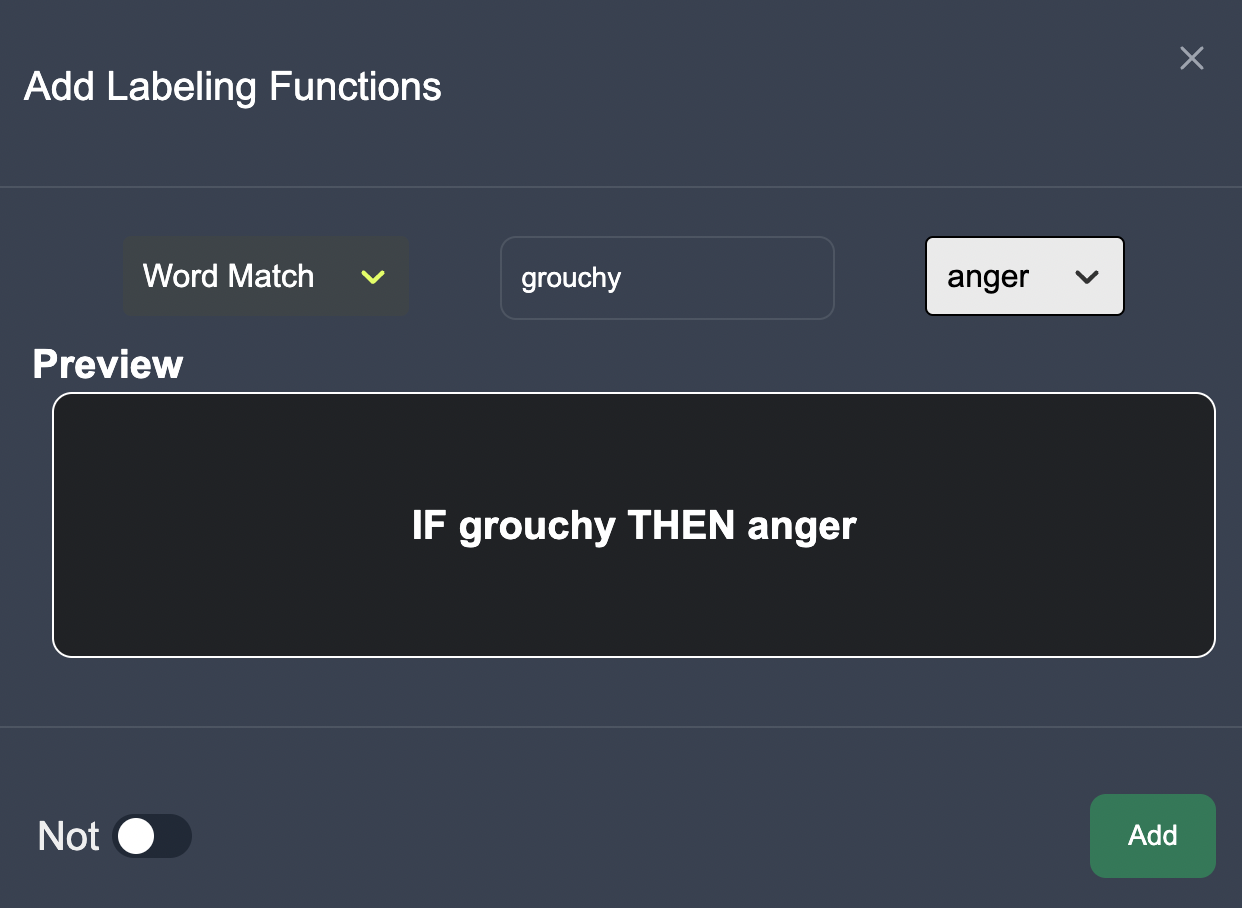
We can add labeling functions to highlight keywords and entities associated with an emotion.
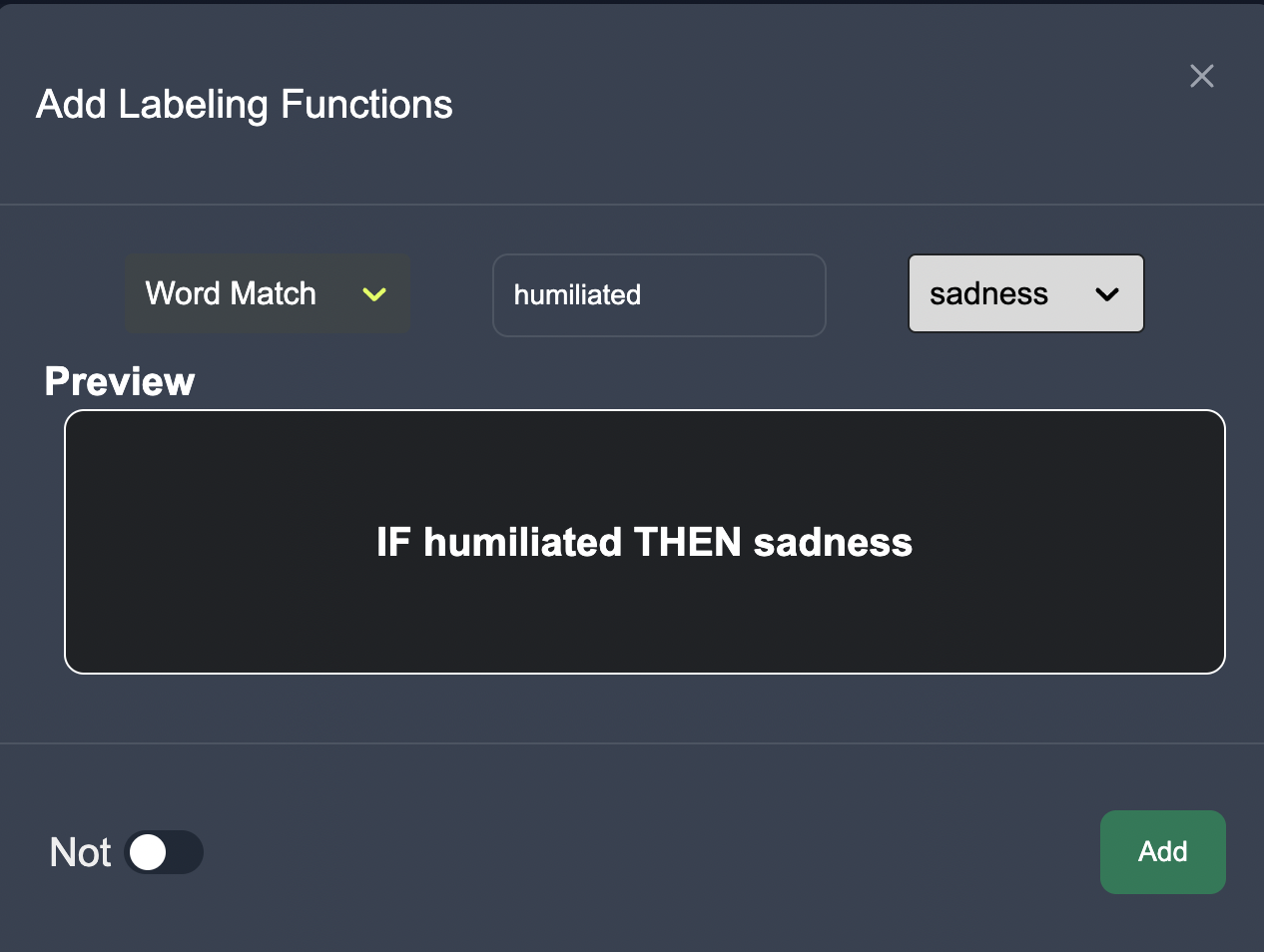
Now we are able to see the tagged emotions data.
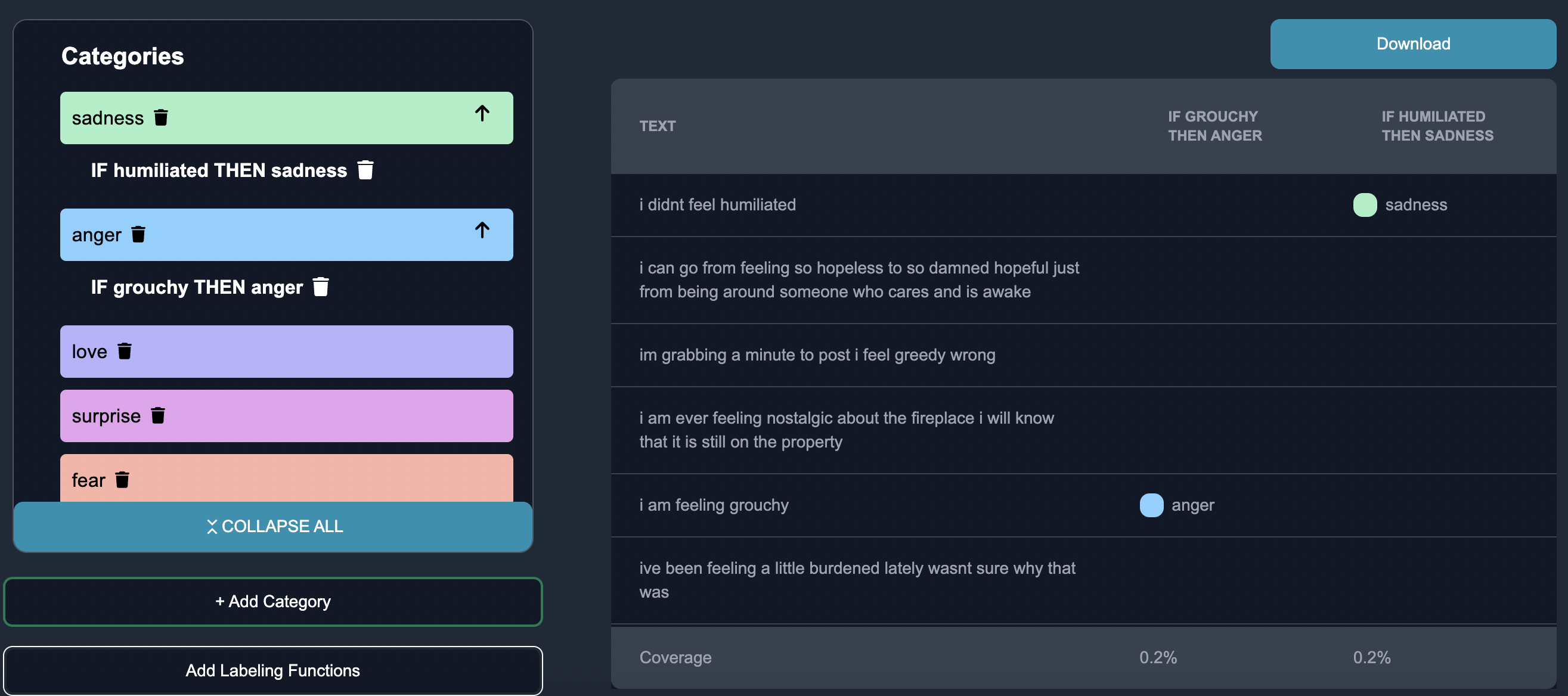
We can download the tagged data as a CSV if we would like to.
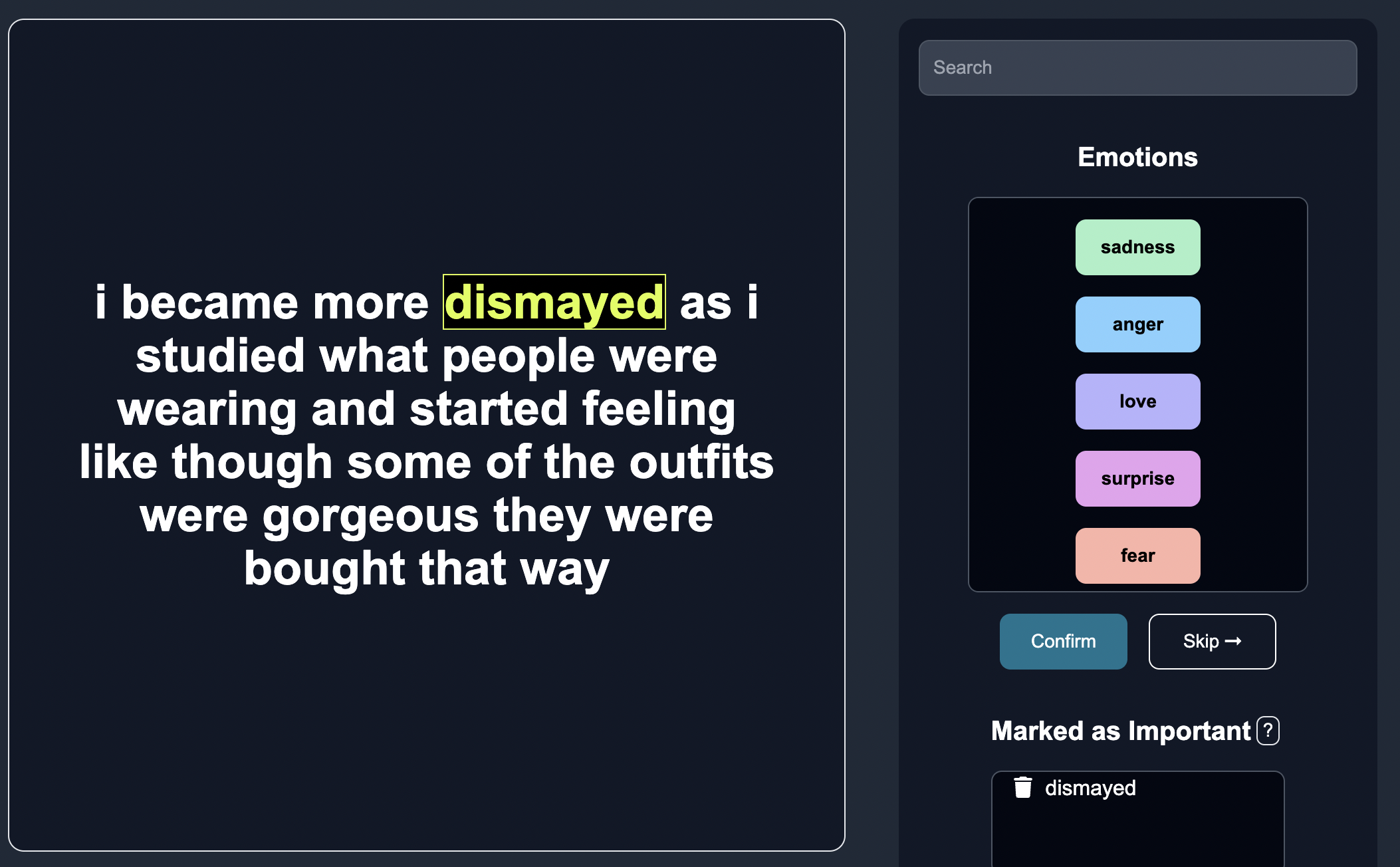
Annotate
Insert human feedback via the correct categories on a few edge cases.
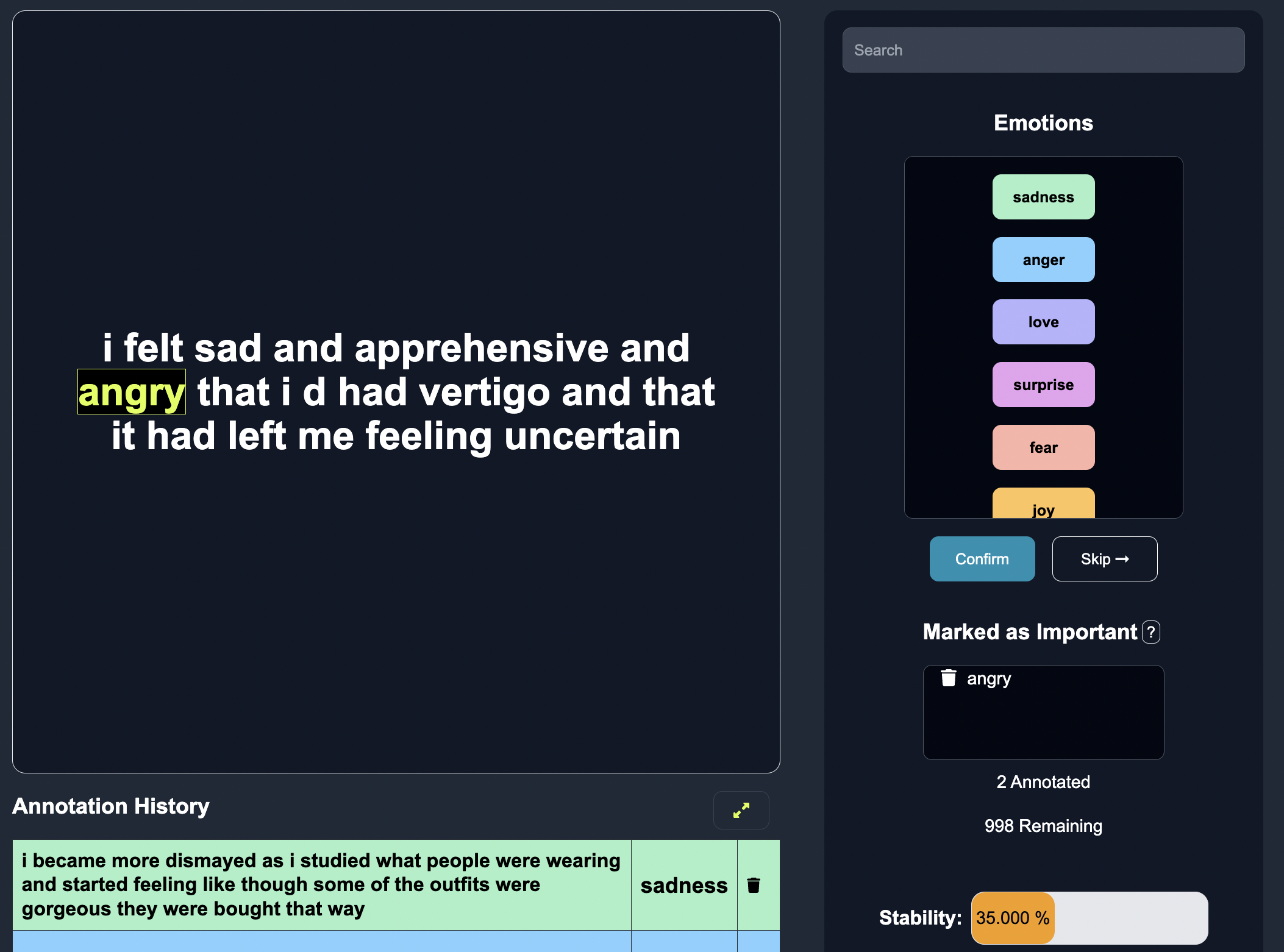
As we annotate more posts, the model is able to learn better predictions over time.
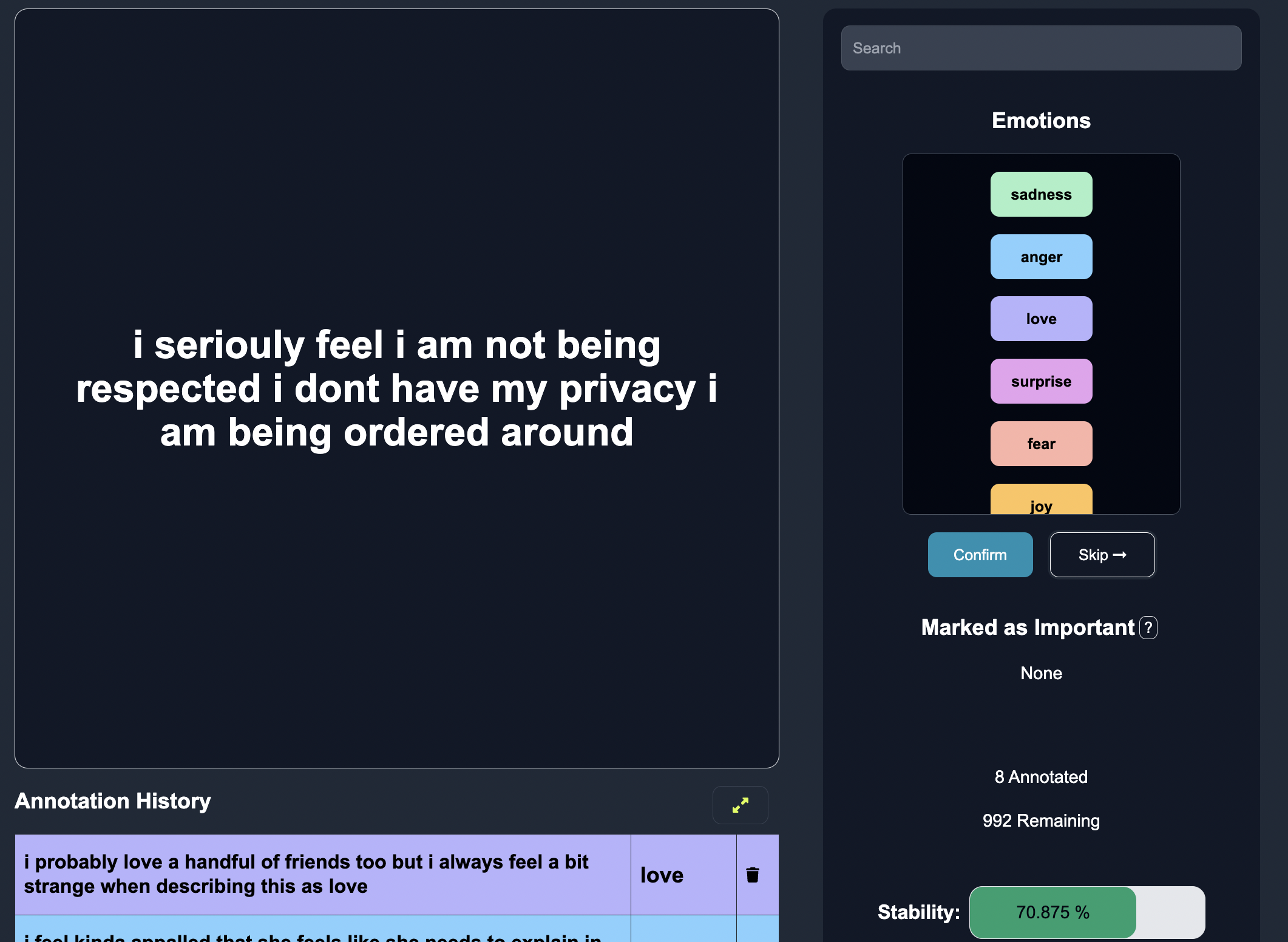
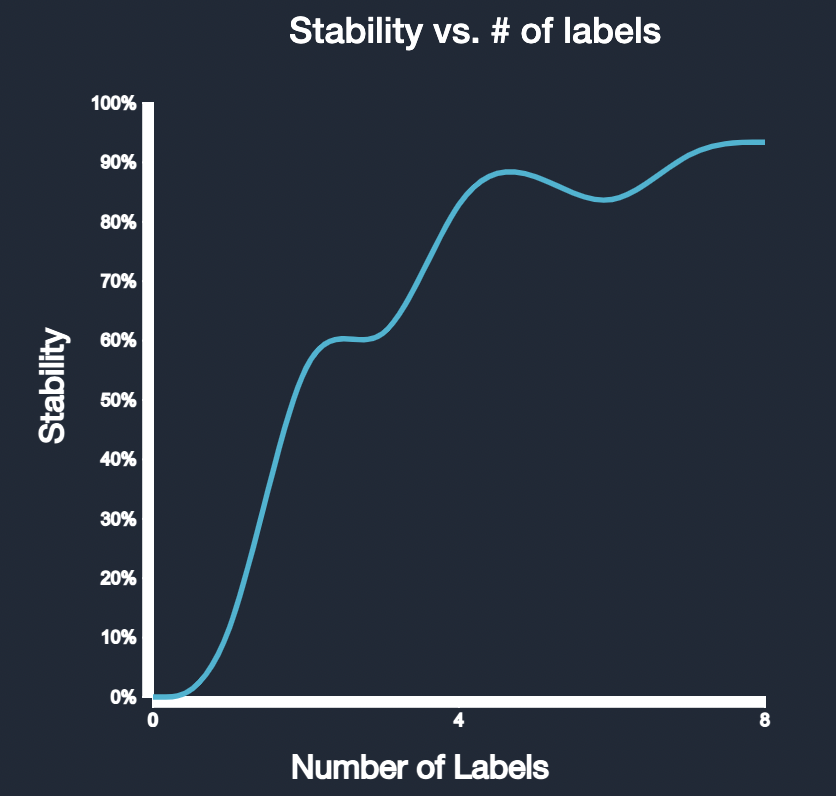
Notice that the stability is now green, which means we should have good enough predictions to stop annotating.
Download
When we go to the download tab, we can download the CSV, or we can click the dashboard button to view the stability as a function of the number of labels on the dashboard, as well as other class specific metrics.
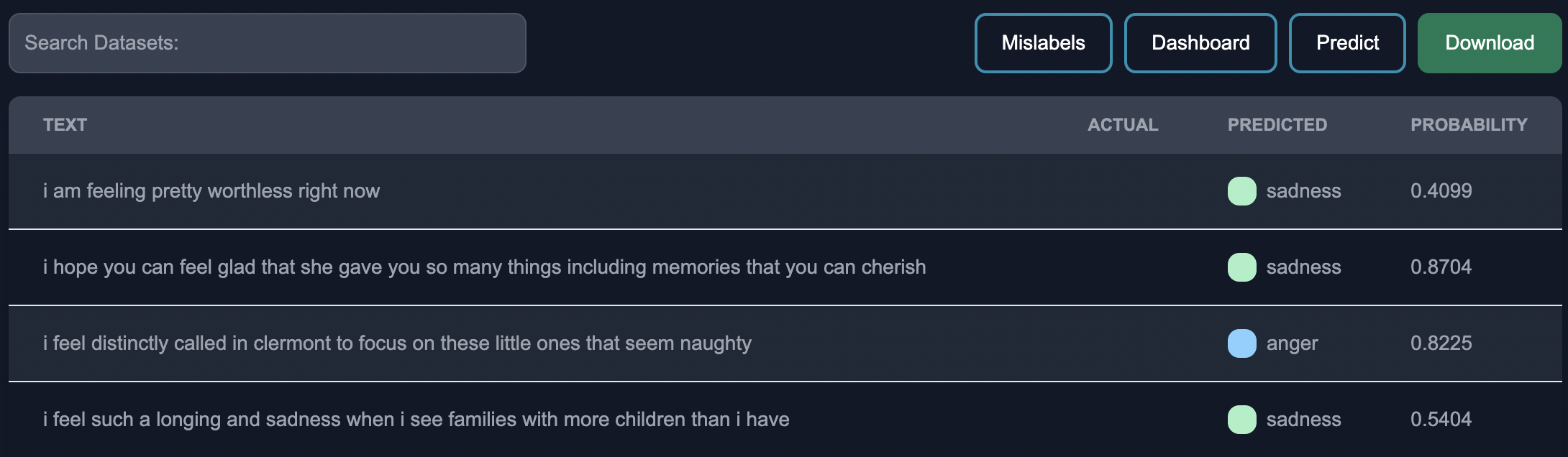
We can also click the mislabels button to view the mislabeled rows from the model.
