Enhancing RAG
Metadata Annotations
When interacting with several different documents, there might be key data points within the metadata that standard retrieval algorithms completely miss out on. A struggle we had faced previously when trying to chat with multiple documents, is that original RAG pipelines would confuse chunks of different documents, so to overcome this, separate vector databases were created for each document. However, this is not practical for large-scale applications and if the user wants to switch between documents or chat with multiple simultaneously. Metadata annotations is a method to overcome this hurdle and enhance retrieval further.
The nature of metadata annotations should be considered with the chunking strategies used. For example, since we will chunk the documents based on elements, details about each element can be included in the annotations. For example, if a table is created in a separate chunk, the metadata can include what kind of table it is (ex. income statement, cash flow statement, etc). Additionally, it is common to add summaries and representative keywords to metadata annotations for additional context.
for i, row in test_df.iterrows():
row["metadata_annotations_answer"], row["metadata_annotations_chunk"] = Anote.predict(
model_name="metadata_annotations",
model_type="metadata_annotations",
question_text=row["question"],
context_text=row["context"]
)
test_df[["id", "metadata_answer"]].to_csv("metadata_submission.csv")
FLARE
Forward-looking active retrieval augmented generation (FLARE) addresses the pitfalls of traditional RAG techniques by employing a much more active approach rather than a one-and-done retrieval pipeline. Instead of doing a similarity search of just the query and document embeddings, FLARE prompts the LLM to generate a hypothetical response from the query without context, and then both the query and hypothetical response are used to trigger the RAG step to search for the most similar chunks. FLARE builds on top of this by setting a threshold when to and when to not trigger retrieval. Only if the next generated tokens have a probability under a certain threshold, meaning that the model is not confident in the next predictions, it will go and try to retrieve relevant chunks from the document. This way, the model does not have to rely on the initial chunks it retrieved but can actively update the context based on confidence.
for i, row in test_df.iterrows():
row["flare_answer"], row["flare_chunk"] = Anote.predict(
model_name="flare",
model_type="flare",
question_text=row["question"],
context_text=row["context"]
)
test_df[["id", "flare_answer"]].to_csv("flare_submission.csv")
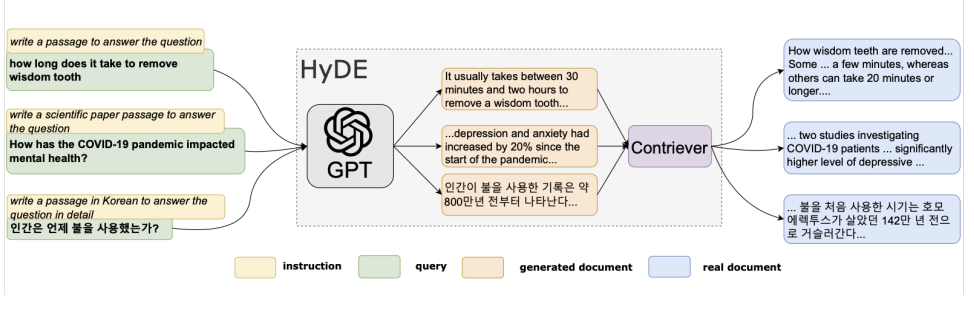
HyDE
Hypothetical Document Embeddings (HyDE). With HyDE, instead of just doing a similarity search with just the user’s original query, it uses an LLM to generate a theoretical document when responding to
a query and then does the similarity search with both the original question and hypothetical answer. This technique has been shown to outperform standard retrievers and eliminate the need for custom
embedding algorithms, but can occasionally lead to incorrect results as it is dependent on another LLM for additional context.
for i, row in test_df.iterrows():
row["hyde_answer"], row["hyde_chunk"] = Anote.predict(
model_name="hyde",
model_type="hyde",
question_text=row["question"],
context_text=row["context"]
)
test_df[["id", "hyde_answer"]].to_csv("hyde_submission.csv")
Reranking
With standard RAG pipelines, one can specify the number of documents or chunks the algorithm should return and therefore how many chunks should be fed as context to the input query. Generally, the top 1 or 2 chunks are included as context, and these are the best results given a cosine similarity or k-nearest neighbors search. However, such algorithms will give the most similar chunks, which might not corre- spond to the most relevant chunks for context.
Re-ranking algorithms is a method to prioritize the relevance over the similarity of the chunks. Essentially, a method like cosine similarity might rank the top 10 chunks, but a separate algorithm will re-rank the algorithms to be based on relevance, and then the top one or two chunks after the re-ranking will be augmented as context to the input query. Cohere’s re-ranking algorithm is a popular one and it along with others uses additional machine learning and natural language processing techniques to further evaluate relevance beyond a similarity search.
for i, row in test_df.iterrows():
row["reranking_answer"], row["reranking_chunk"] = Anote.predict(
model_name="reranking",
model_type="reranking",
question_text=row["question"],
context_text=row["context"]
)
test_df[["id", "reranking_answer"]].to_csv("reranking_submission.csv")
Recursive Chunking
Recursive Chunking is an example of a more adaptable chunking strategy that uses other indicators and rules like punctuation to make chunking more dynamic. While the chunks will still be of relatively equal size, the additional parameters will ensure that the chunks are not cut mid-sentence, for example. Through using Python libraries like Spacy and NLTK, we can use more sophisticated sentence-spitting techniques that use natural language processing techniques to be more aware of the context of the document.
for i, row in test_df.iterrows():
row["recursive_chunking_answer"], row["recursive_chunking_chunk"] = Anote.predict(
model_name="recursive_chunking",
model_type="recursive_chunking",
question_text=row["question"],
context_text=row["context"],
)
test_df[["id", "recursive_chunking_answer"]].to_csv("recursive_chunking_submission.csv")
Element Based Chunking
When it comes to financial reports, these documents are generally quite long and contain more complicated structures like tables. Documents of the same nature, such as 10-ks also generally follow a specific format that can be indicated by the headings and subheadings of the documents. Due to the special nature of these financial reports, a version of element-based chunking that takes such facts into account could help to further improve retrieval. For instance if a title element is found, a new chunk is started and if a table element is found, a new chunk is started, preserving the entire table.
for i, row in test_df.iterrows():
row["element_based_chunking_answer"], row["element_based_chunking_chunk"] = Anote.predict(
model_name="element_based_chunking",
model_type="element_based_chunking",
question_text=row["question"],
context_text=row["context"],
)
test_df[["id", "element_based_chunking_answer"]].to_csv("element_based_chunking_submission.csv")