Named Entity Recognition with Active Learning
Named Entity Recognition (NER) is the task of identifying and classifying named entities, such as person names, locations, organizations, and other specific categories, within text documents. While traditional NER approaches rely on labeled data for training machine learning models, actively learning from human input can improve the accuracy and efficiency of the NER process. This markdown will explore the integration of active learning into NER tasks, using models like Concise Concepts.
Example Dataset
In this example, we have text data from cooking instructions online. We want to find where in the instructions there are fruits, vegetables or meats, highlighting the specific food we find that pertains to that entity. We want to use this dataset to train a model which we will use to find the entities of food in menus. This is applicable for restaurants who are looking to determine the best prices for their offerings - via finding granular entities of foods in their menus, we can help ensure that the cost per serving is proportional to the expenses for a specific food entity. Here is the example data we will look into:
| Text |
|---|
| Chop the onions and bell peppers. |
| Grill the chicken until it is cooked thoroughly. |
| Add sliced tomatoes and cucumbers to the salad. |
| Season the steak with salt and pepper. |
| Peel and slice the bananas for the dessert. |
| Boil the broccoli until tender. |
| Marinate the pork in soy sauce and garlic. |
| Garnish the dish with parsley leaves. |
| Bake the apples until they are soft. |
| Grill the zucchini until it has grill marks. |
| Roast the lamb in the oven at 350°F. |
| Steam the spinach until wilted. |
| Slice the carrots and steam them until tender. |
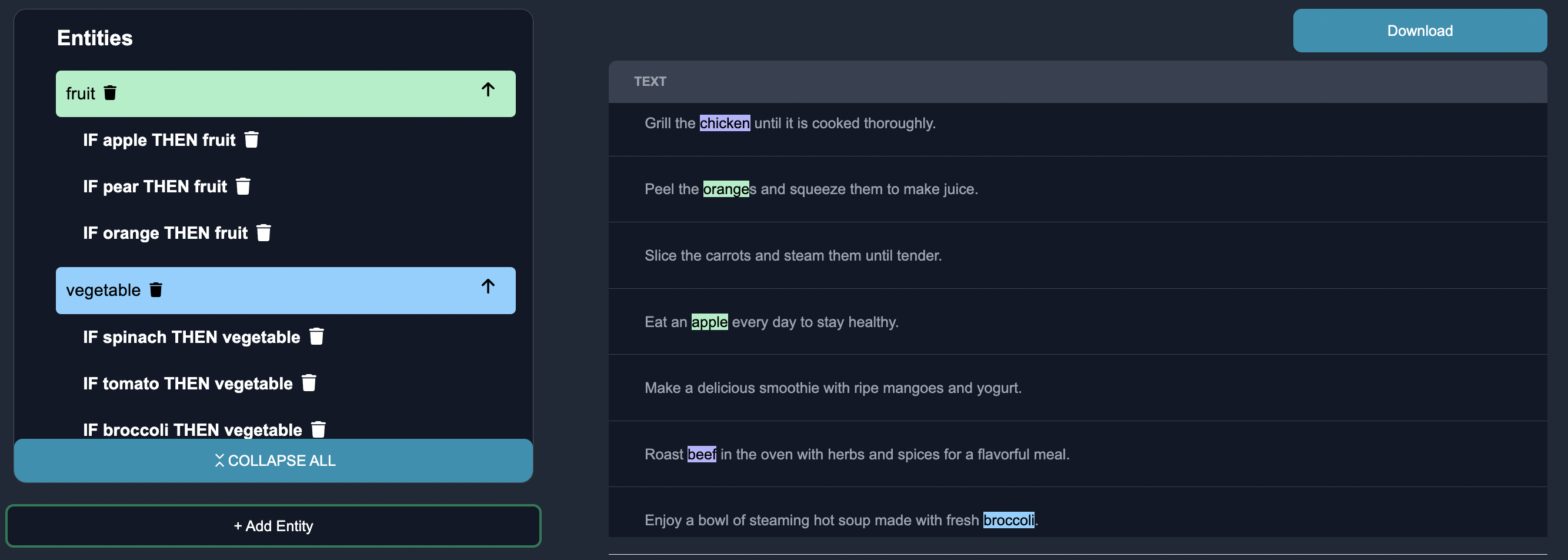
Using Anote
Let's upload the dataset onto Anote using task type of NER and per line decomposition:
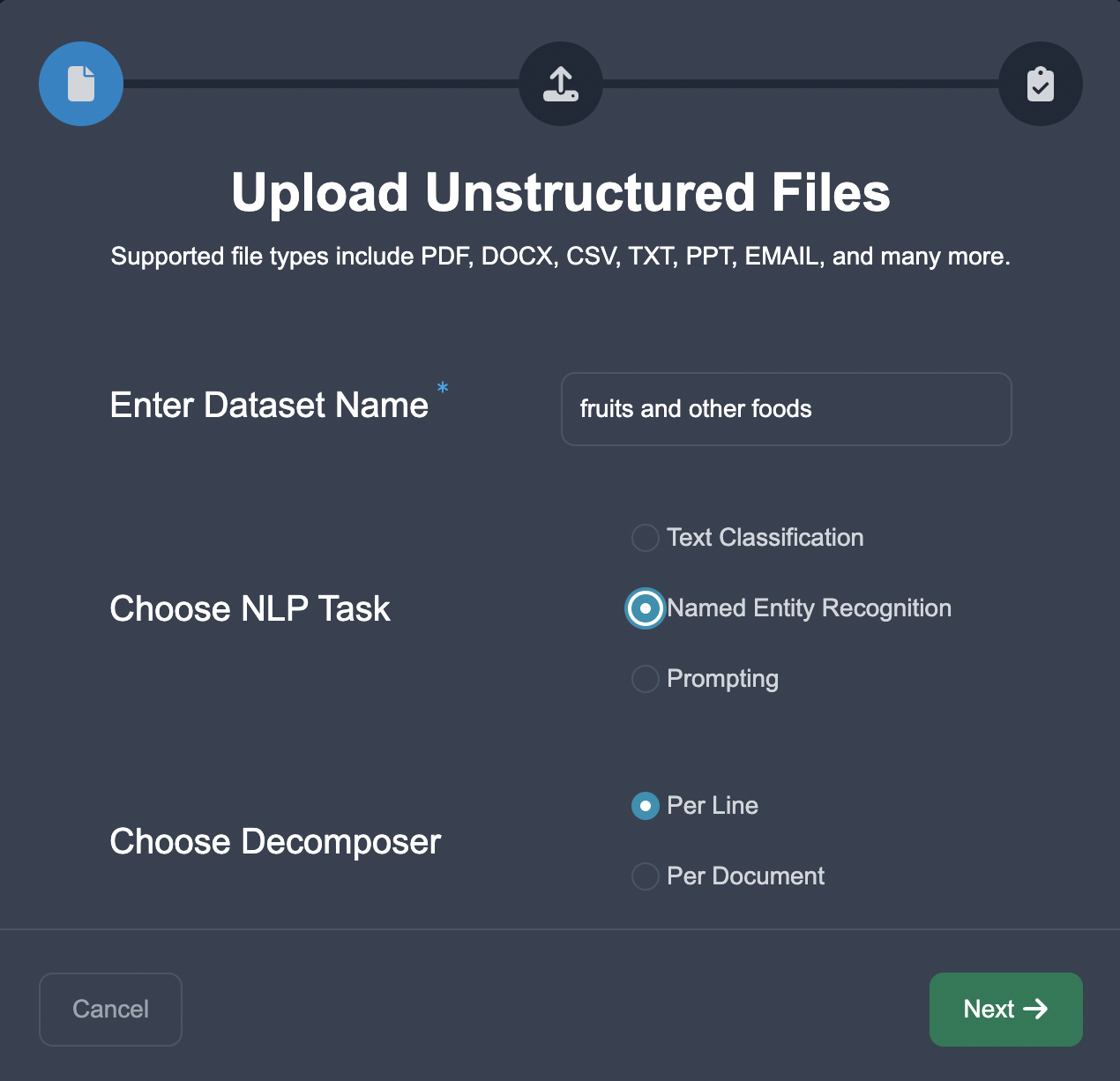
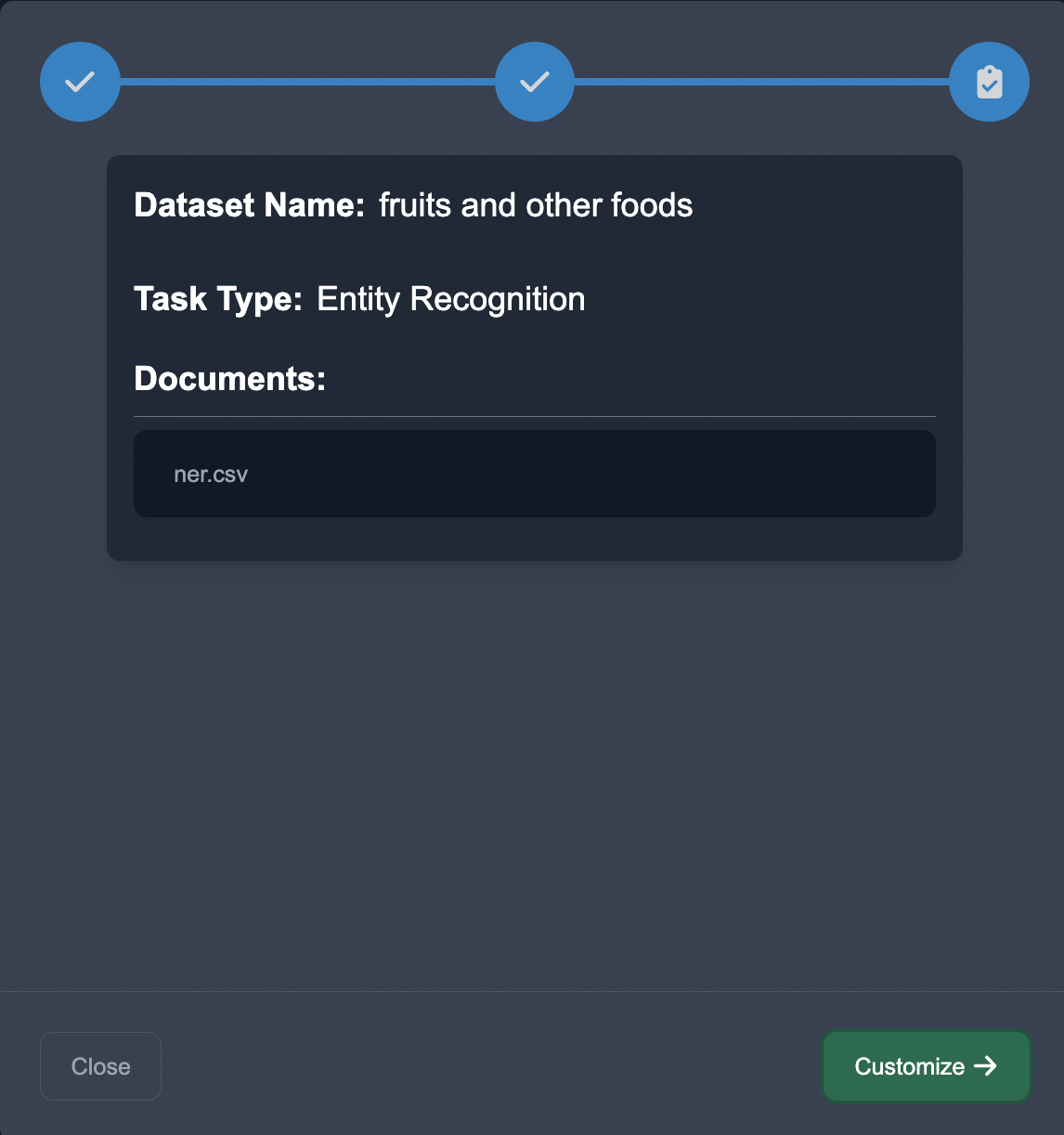
We then begin defining the entities we would like to extract from the text. On the backend, to simplify things, let's say we are using a NER model like concise concepts.
Incorporating Concise Concepts into NER
The following code demonstrates how to incorporate Concise Concepts into the NER process:
import spacy
import concise_concepts
data = {
"fruit": ["apple", "pear", "orange"],
"vegetable": ["broccoli", "spinach", "tomato"],
"meat": ["beef", "pork", "fish", "lamb"]
}
text = """
Heat the oil in a large pan and add the Onion, celery and carrots.
Then, cook over a medium–low heat for 10 minutes, or until softened.
Add the courgette, garlic, red peppers and oregano and cook for 2–3 minutes.
Later, add some oranges and chickens."""
# Use any model that has internal spaCy embeddings
nlp = spacy.load('en_core_web_lg')
nlp.add_pipe("concise_concepts", config={"data": data})
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)
In the provided code snippet, we first import the necessary libraries, including spacy and concise_concepts. Next, we define a dictionary called data that contains entity categories as keys and their corresponding values. We then load a spaCy model and add the concise_concepts component to the pipeline, providing the data dictionary as a configuration. After that, we process the input text using the pipeline and iterate over the recognized entities in the document, printing each entity's text and its associated label.

How Concise Concepts Works
When processing the input text, Concise Concepts performs the following steps:
Word2Vec Embeddings: Concise Concepts uses word2vec embeddings to represent each word in the data dictionary and the input text.
Similarity Calculation: For each value in the data dictionary, Concise Concepts finds the n=150 most similar words based on the word2vec embeddings. This step helps in identifying words related to each entity category.
Conflict Resolution: Concise Concepts ensures that different entity categories do not have the same similar words. It performs conflict resolution to eliminate ambiguity and ensure accurate entity recognition.
Iterative Entity Recognition with Concise Concepts
Concise Concepts allows for an iterative process of building the dictionary, finding similar words, and resolving conflicts to enhance entity recognition. Let's go through iterations of this process:
Iteration 1
In the first iteration, we start with an empty dictionary of entities we would like to find. Let's consider the following initial dictionary:
During this iteration, we annotate the text data and identify entities without any predefined values in the dictionary.
| Text |
|---|
Cut the pears (fruit) into slices |
Grill the beef (meat) with salt. |
Boil the broccoli (vegetable) until tender. |
Marinate the pork (meat) in soy sauce and garlic. |
Bake the apples (fruit) until they are soft. |
Steam the spinach (vegetable) until wilted. |
Iteration 2
In the second iteration, the values to the dictionary are added based on the annotations:
data = {
"fruit": ["apple", "pear"],
"vegetable": ["broccoli", "spinach"],
"meat": ["beef", "pork"]
}
After adding the values, we utilize word2vec embeddings to calculate four similar words for each entity value. This step helps identify words related to each entity category and enriches the dictionary.
For Iteration 2, with top_n_similar_words = 4, the similar words for each value could be:
Fruit category:
-
apple(similar:fruit,peach,banana,tomato) -
pear(similar:fruit,mango,plum,cherry)
Vegetable category:
-
broccoli(similar:vegetable,lettuce,cauliflower) -
spinach(similar:vegetable,carrot,kale,tomato)
Meat category:
-
beef(similar:meat,chicken,pork,steak) -
pork(similar:meat,steak,bacon,sausage)
Through conflict resolution, Concise Concepts ensures that the most appropriate category is assigned to each value based on contextual cues or predefined rules. For example, tomato is initially considered similar to both the fruit and vegetable categories, Concise Concepts resolves this conflict to assign the most appropriate entity category, fruit.
During this iteration, we annotate a few more rows of text data and identify entities.
| Text |
|---|
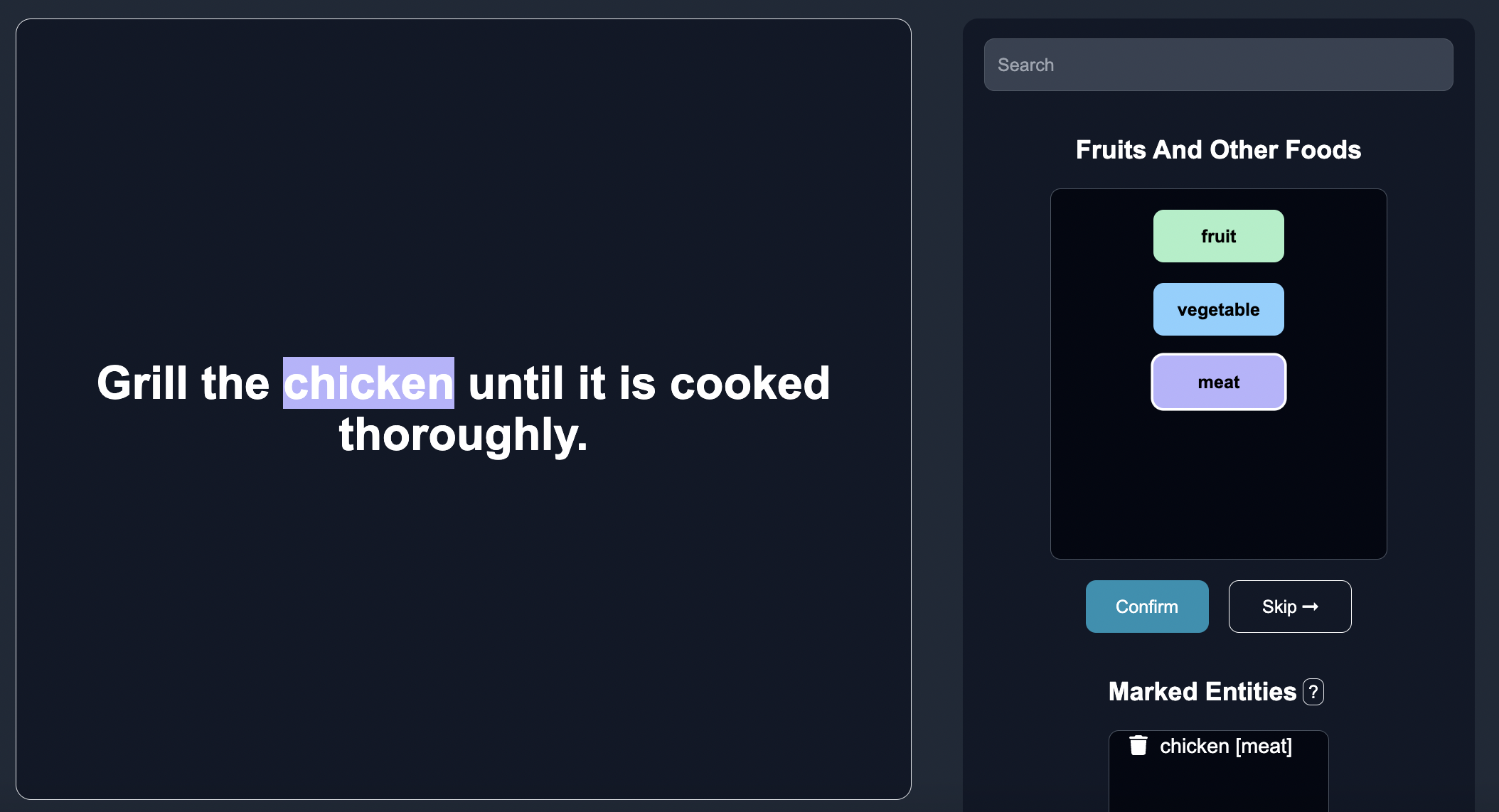
Grill the chicken (meat) until it is cooked thoroughly. |
Peel the oranges (fruit) and squeeze them to make juice |
Slice the carrots (vegetable) and steam them until tender. |
Iteration 3
In the third iteration, the values are added to the dictionary, based on the previous annotations:
data = {
"fruit": ["apple", "pear", "orange"],
"vegetable": ["broccoli", "spinach", "carrot"],
"meat": ["beef", "pork", "chicken"]
}
By incorporating additional values to the existing entity categories, Concise Concepts further improves its entity recognition capabilities. It recalculates four similar words for each expanded value and leverages conflict resolution for accurate categorization.
For Iteration 3, with top_n_similar_words = 4, the similar words for each value could be:
Fruit category:
-
apple(similar:fruit,peach,banana,tomato) -
pear(similar:fruit,mango,plum,cherry) -
orange(similar:fruit,lemon,grapefruit,tangerine)
Vegetable category:
-
broccoli(similar:vegetable,lettuce,cauliflower) -
spinach(similar:vegetable,carrot,kale,tomato) -
carrot(similar:vegetable,celery,radish,onion)
Meat category:
-
beef(similar:meat,chicken,pork,steak) -
pork(similar:meat,steak,bacon,sausage) -
chicken(similar:meat,beef,turkey,duck)
Things are going well, so we continue to annotate more data. As we label more data, we realize that there are categories that we initially missed, so we add labels for grain and dairy too:
| Text |
|---|
Grill the chicken (meat) until it is cooked thoroughly. |
Peel the oranges (fruit) and squeeze them to make juice. |
Slice the carrots (vegetable) and steam them until tender. |
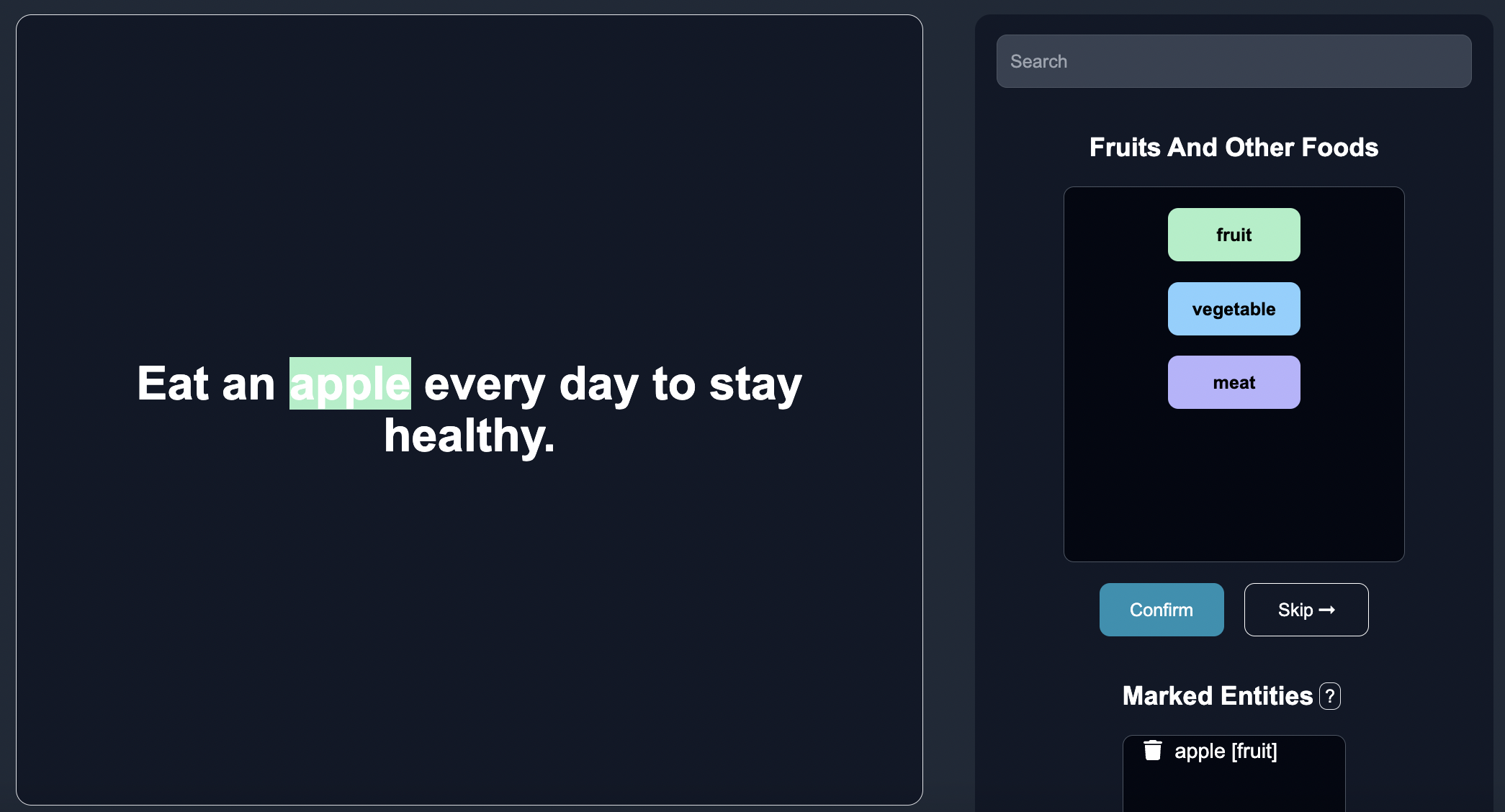
Eat an apple (fruit) every day to stay healthy. |
Make a delicious smoothie (fruit) with ripe mangoes and yogurt. |
Roast beef (meat) in the oven with herbs and spices for a flavorful meal. |
Enjoy a bowl of steaming hot soup (vegetable) made with fresh broccoli. |
Top your pizza (vegetable) with spinach and sliced tomatoes for added freshness. |
Prepare a nutritious salad (vegetable) with mixed greens, carrots, and celery. |
Indulge in a cheesy sandwich (dairy) filled with melted cheese and ham. |
Cook a juicy steak (meat) to perfection on the grill. |
Add rice (grain) to boiling water and simmer until tender. |
Spread wheat (grain) bread with your favorite sandwich fillings. |
Quinoa (grain) is a nutritious and versatile grain to include in your meals. |
Pour milk (dairy) over your cereal for a creamy and delicious breakfast. |
Enjoy a cheese (dairy) platter with a variety of artisanal cheeses. |
Have a refreshing yogurt (dairy) parfait with layers of fruits and granola. |
Peel the oranges (fruit) and squeeze them to make juice |
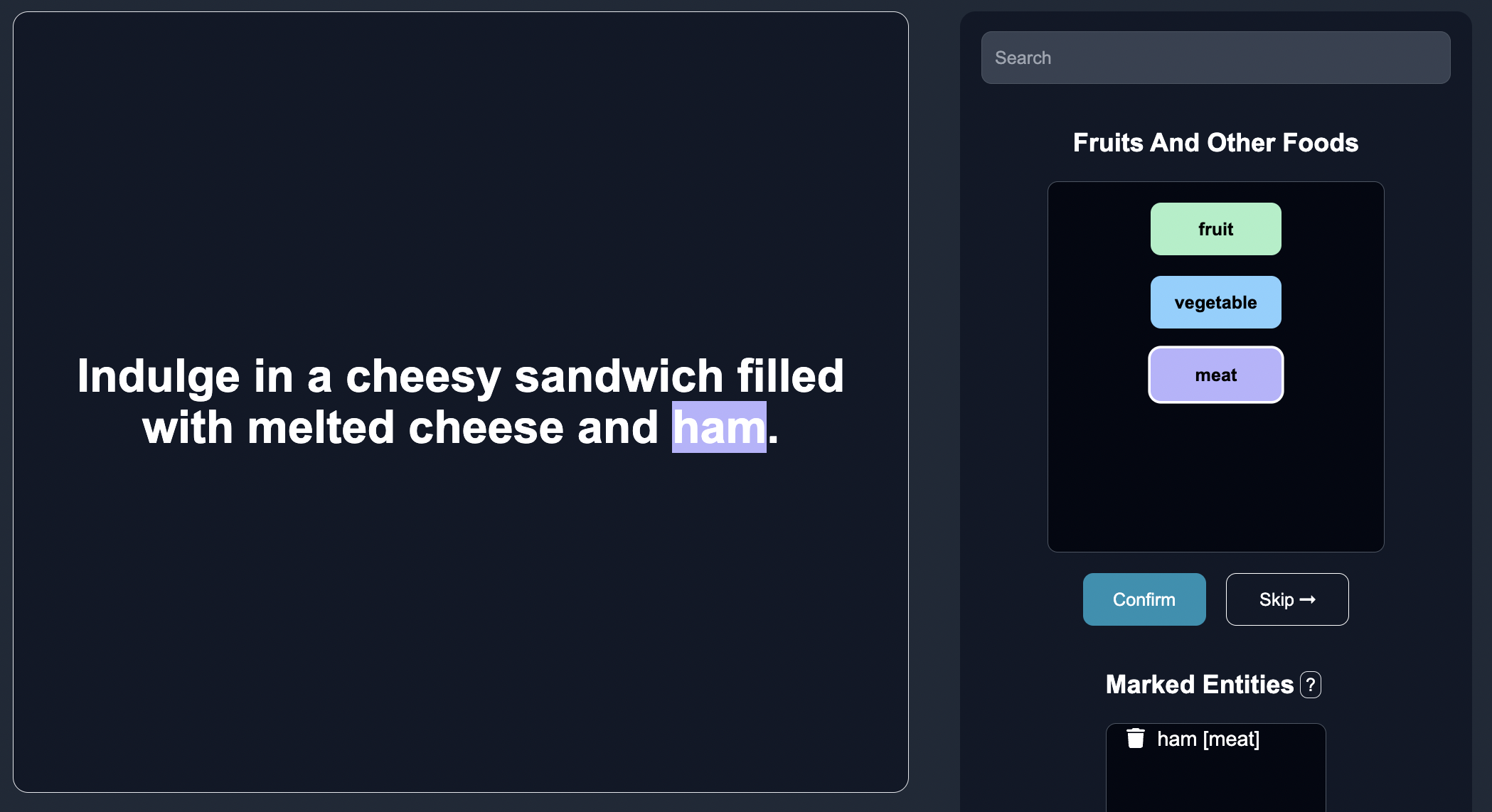
Iteration 4: Adding More Entities
In the fourth iteration, we further expand the dictionary by adding new entities to the dictionary, grain and dairy:
data = {
"fruit": ["apple", "pear", "orange", "banana", "mango"],
"vegetable": ["broccoli", "spinach", "carrot", "celery"],
"meat": ["beef", "pork", "chicken", "lamb"],
"grain": ["rice", "wheat", "quinoa"],
"dairy": ["milk", "cheese", "yogurt"]
}
By incorporating additional values to the existing entity categories, Concise Concepts further improves its entity recognition capabilities. It recalculates four similar words for each expanded value and leverages conflict resolution for accurate categorization.
For Iteration 4, with top_n_similar_words = 4, the similar words for each value could be:
Fruit category:
-
apple(similar:fruit,peach,banana,mango) -
pear(similar:fruit,mango,banana,pineapple) -
orange(similar:fruit,lemon,grapefruit,tangerine) -
banana(similar:fruit,pineapple,mango,papaya) -
mango(similar:fruit,papaya,pineapple,banana)
Vegetable category:
-
broccoli(similar:vegetable,lettuce,spinach,carrot) -
spinach(similar:vegetable,carrot,broccoli,celery) -
carrot(similar:vegetable,celery,broccoli,cucumber) -
celery(similar:vegetable,cucumber,carrot,broccoli)
Meat category:
-
beef(similar:meat,chicken,pork,steak) -
pork(similar:meat,steak,chicken,bacon) -
chicken(similar:meat,turkey,beef,duck) -
lamb(similar:meat,goat,steak,chicken)
Grain category:
-
rice(similar:grain,barley,wheat,oat) -
wheat(similar:grain,oat,rice,barley) -
quinoa(similar:grain,amaranth,barley,rice)
Dairy category:
-
milk(similar:dairy,cheese,yogurt,buttermilk) -
cheese(similar:dairy,yogurt,milk,buttermilk) -
yogurt(similar:dairy,buttermilk,milk,cheese)
We continue to annotate more data to try to refine performance. As we do so, we notice that there are becoming a lot of fruits and vegetables, so we want the entities to become more granular. To account for this, we create subcategories of greens for vegetables, and red_fruits for fruits.
| Text |
|---|
| Slice spinach (vegetable:greens) and add it to your omelette. |
| Make a kale (vegetable:greens) salad with lemon vinaigrette dressing. |
| Toss lettuce (vegetable:greens) with cherry tomatoes and balsamic dressing. |
| Enjoy a crisp apple (fruit:red_fruits) for a healthy snack. |
| Make a strawberry (fruit:red_fruits) smoothie with yogurt and honey. |
| Bite into juicy cherries (fruit:red_fruits) for a burst of flavor. |
Iteration 5: Hierarchical Categories
In the fifth iteration, we introduce subcategories to enhance the entity classification. Let's update the dictionary by adding subcategories:
data = {
"fruit": ["apple", "pear", "orange", "banana", "mango"],
"fruit:red_fruits": ["apple", "strawberry", "cherry"]
"vegetable": ["broccoli", "spinach", "carrot", "celery"],
"vegetable:greens": ["spinach", "kale", "lettuce"],
"meat": ["beef", "pork", "chicken", "lamb"],
"grain": ["rice", "wheat", "quinoa"],
"dairy": ["milk", "cheese", "yogurt"],
}
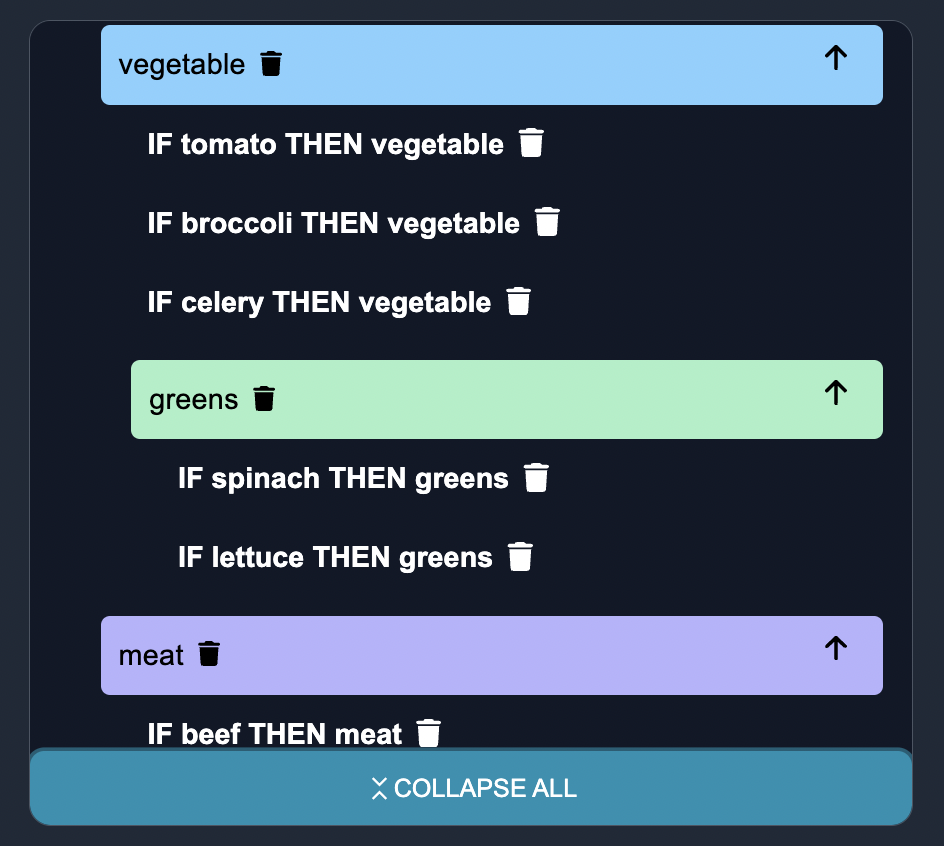
By introducing subcategories, we can further specify the types of vegetables and fruits. This allows for more precise entity classification and identification.
For Iteration 5, the dictionary now includes the following subcategories:
- Under the
vegetablecategory, we have thegreenssubcategory containing values such asspinach,kale, andlettuce. This helps distinguish leafy green vegetables from other types. - Under the
fruitcategory, we introduce thered_fruitssubcategory with values likeapple,strawberry, andcherry. This subcategory specifically denotes fruits with a red color.
The addition of subcategories enhances the granularity of the entity classification, providing more specific information about the types of vegetables and fruits.
Benefits of Active Named Entity Recognition
The iterative process of building the dictionary, finding similar words, and resolving conflicts demonstrates the active learning and continuous improvement capabilities of active named entity recognition. This is very useful in the case where zero shot entity recognition models are not accurate enough, when you are trying to find complex ontologies and large taxonomies of entities, or when you are trying to find entities that are not known via pretrained model. By actively involving human annotators in the NER process, domain expertise and insights can be leveraged to refine the model's predictions, providing higher accuracy over time. In addition, active Named Entity Recognition offers several other key benefits.
-
Efficient Labeling: With just a few labeled examples, the model can learn to recognize named entities accurately, reducing the need for extensive manual annotation.
-
Adaptability: The model can quickly adapt to new entity categories or variations in named entities, allowing for easy extension and customization. Anote's model can support hierarchical entities, providing granularity in regards to identifying tailored entities.
-
Improved Performance: Despite the limited labeled data, few-shot NER models can achieve impressive performance, enabling much better entity recognition than zero shot named entity recognition across different domains and languages.
Summary
Active learning from human input can enhance Named Entity Recognition tasks by utilizing generative AI models like Concise Concepts to identify edge cases, sorting and annotating these cases with human feedback, and incorporating the annotations into the model training to iteratively improve its performance. Through active learning, the model can dynamically select additional edge cases for annotation, focusing on the most uncertain or ambiguous examples. Via utilizing word2vec embeddings and applying conflict resolution techniques, it becomes possible to achieve accurate entity recognition, even with limited labeled data. This reduces the number of annotations required while maximizing the learning potential of the model.