About
About

In the world of human centric AI, data annotation and model inference are often done in conjunction. Oftentimes, your work with Anote may just be the start of your AI and modeling and journey, and as partners we would love to be there for the ride. After the data annotations are complete, we are there to help with model development, and to help you revisit your data label to iterate on your model and improve performance. For assistance with specific business use cases, and for product feedback, please contact the Anote team at nvidra@anote.ai.
Artificial Intelligence is here, is incredibly powerful, and will impact many sectors and people. At Anote, we believe that it is really important that not only the people with the biggest brains are involved, but also those with the biggest hearts. Here are a few answers to commonly asked questions about Anote, for additional context:
Why is Data Labeling Needed?
Many enterprises are blocked from the successful deployment of AI by the need for high quality, massively manually-labeled training datasets that modern ML approaches require.

Having labeled data to train ML models is crucial for success. However, less than 0.01% of the required data is currently labeled, resulting in a staggering 90% failure rate for AI projects. Data scientists realize this challenge, as they currently devote 80% of their time to data preparation, leaving only 20% for building ML models. This disproportionate allocation of time hampers productivity and impedes progress in AI development.
How do companies currently label data?
Right now, when companies need to label their data for AI projects, they may currently:
-
Leave their dataset unlabeled, resulting in the project failing from the onset
-
Label their data themselves in a spreadsheet, which is extremely tedious, time consuming and mundane work
-
Build internal tooling to help label their data, which oftentimes leads to failure as it usually takes years to build
-
Send their dataset to a team of manual data annotators to label, with workforces of millions of data labelers around the globe
What is the manual data annotation process like?

If companies decide to pay a team of manual data annotators to label their data, this can be extremely tedious work that takes the data annotators a lot of time (many months to years) to return labeled data. When companies get their data back from the data labelers, oftentimes they are not happy with the initial results, as they realize that there exist all of these label errors in their dataset. This usually results in a back-and-forth dialogue where companies ask the data labelers to fix the label errors, add more data to the dataset, and add more classes/categories of data as a result of changing business requirements. To make these adjustments, the data annotators need to manually label all of the data again.
At this point, companies have wasted months to years of their time to get high quality labeled data, which has been a massive pain point. Many companies spend high millions to low billions of dollars on data labeling, but have not seen the dividends pay off. Companies wish there was a better, faster and cheaper way to get labeled data for their AI project, but unfortunately without a high quality, massive labeled training dataset, their AI project can not succeed
What are the limitations of manual data labeling?
Manual data annotation presents several limitations and challenges:
Time: Manual data labeling is a slow process, often taking months to years to complete. This prolonged timeline delays AI project development and implementation.
Cost: The cost of manual data labeling can be substantial, consuming a significant portion of the AI development budget. This expense limits scalability and cost-effectiveness in the long run.
Accuracy: Human errors and inconsistencies in manual labeling can lead to inaccuracies in the labeled data. This lack of precision undermines the reliability and effectiveness of AI models trained on such data.
Changing Business Requirements: As business requirements evolve, new classes of data may need to be incorporated into the labeled dataset. This necessitates the iterative, manual relabeling of the entire dataset, adding further time and resource burdens.
Why should we convert unstructured data to structured data?
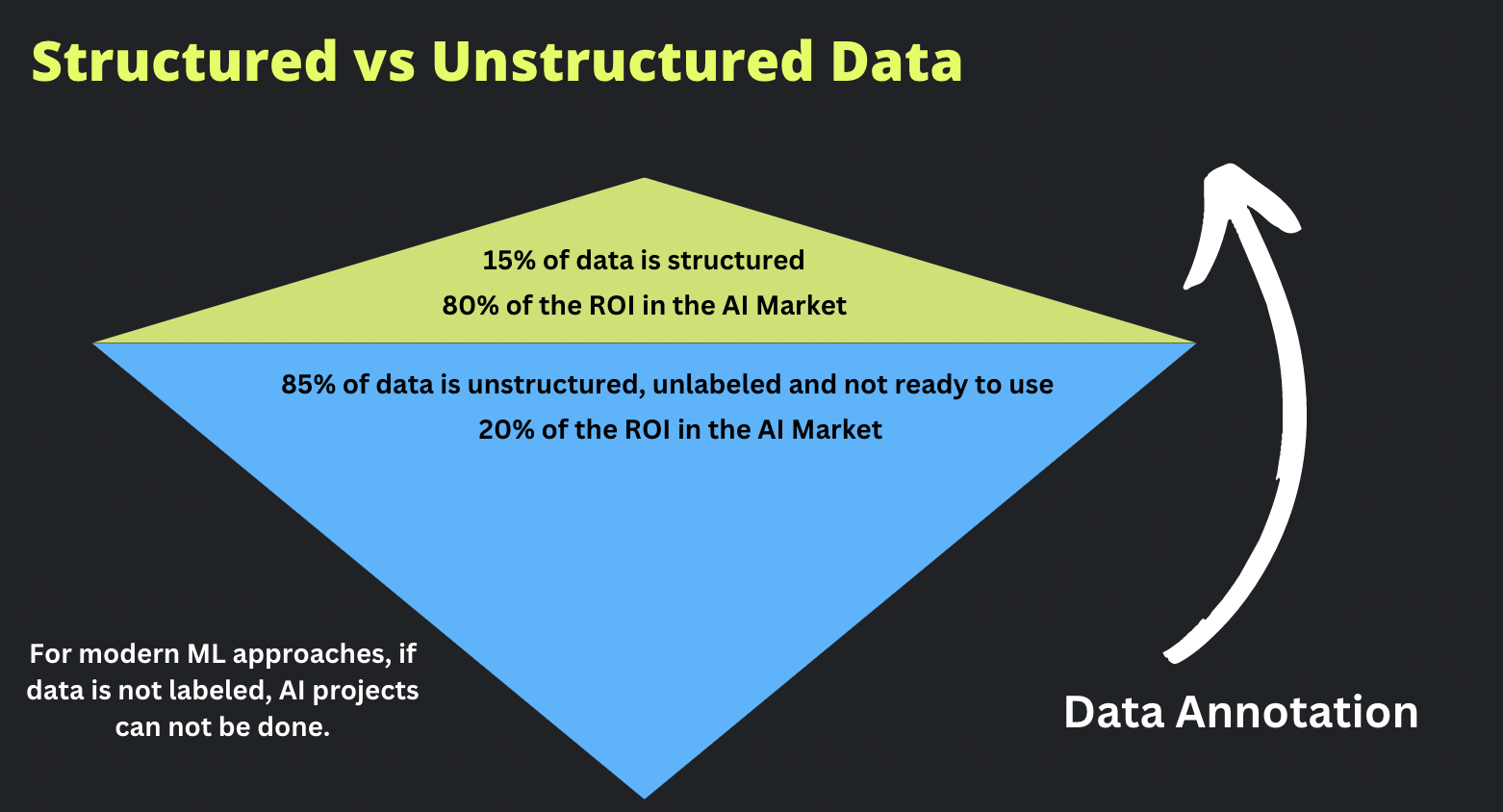
A vast majority, approximately 85%, of the available data is unstructured, unlabeled, and not readily usable for AI applications. This unstructured data poses challenges in terms of organizing, extracting meaningful information, and preparing it for machine learning models. In contrast, only about 15% of the data is structured, making it easier to work with and analyze.
Return on investment (ROI) in the AI market directly correlates to the ability to effectively handle unstructured data. Approximately 80% of the ROI in the AI market comes from converting unstructured data into usable insights, while structured data accounts for only 20% of the ROI.
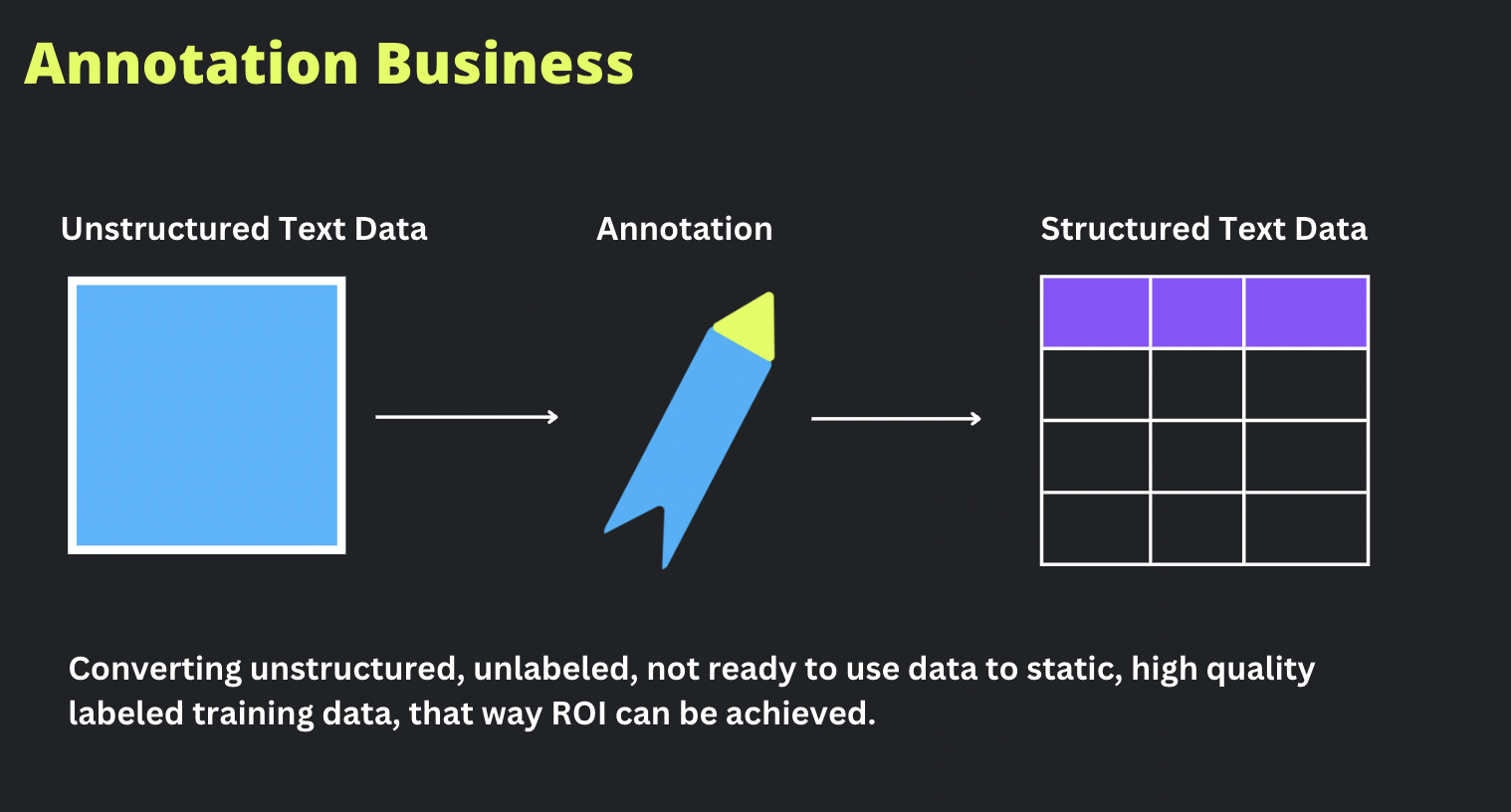
The data annotation business involves converting unstructured, unlabeled data into static, high-quality labeled training data. The data labeling process is essential to achieve accurate and reliable AI models, and is directly proportional to your enterprises ROI on AI investments.
Why focus on text data?
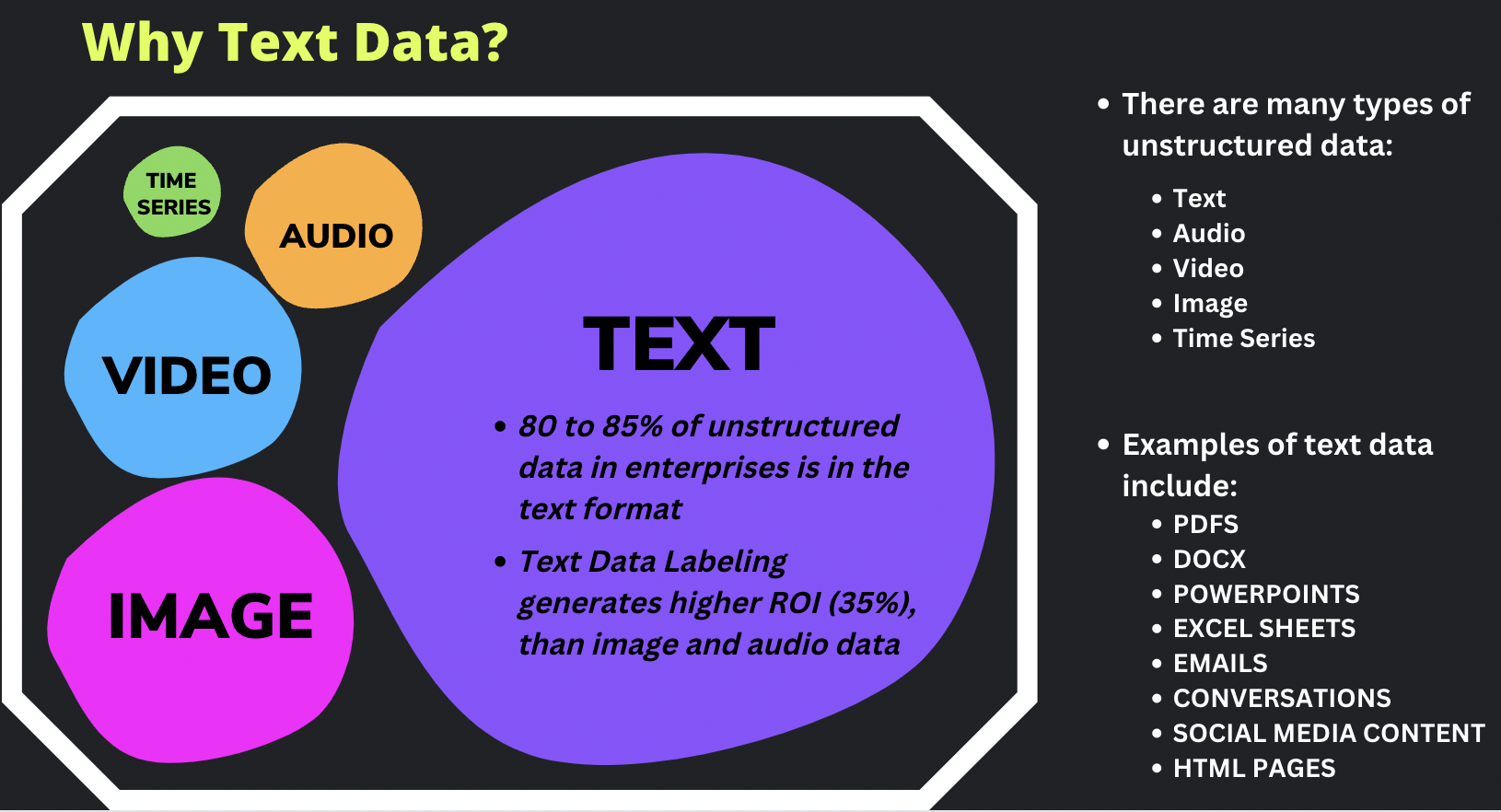
Text data plays a crucial role in AI projects due to the valuable insights it offers. With 85% of unstructured data in enterprises being in the form of text, text data provides information that can be extracted and leveraged in tasks such as sentiment analysis, text classification, named entity recognition, summarization and question answering.