Overview
The Fine Tuning Library provides a comprehensive set of tools for developers to train, fine-tune, predict, and evaluate models on various NLP tasks. It is designed to streamline the process of working with large language models (LLMs) by offering a flexible and extensible interface for integrating these models into custom workflows within your enterprise. Whether you're working on text classification, named entity recognition, or more advanced prompting tasks, the SDK is built to help you efficiently manage and deploy models tailored to your specific use case.
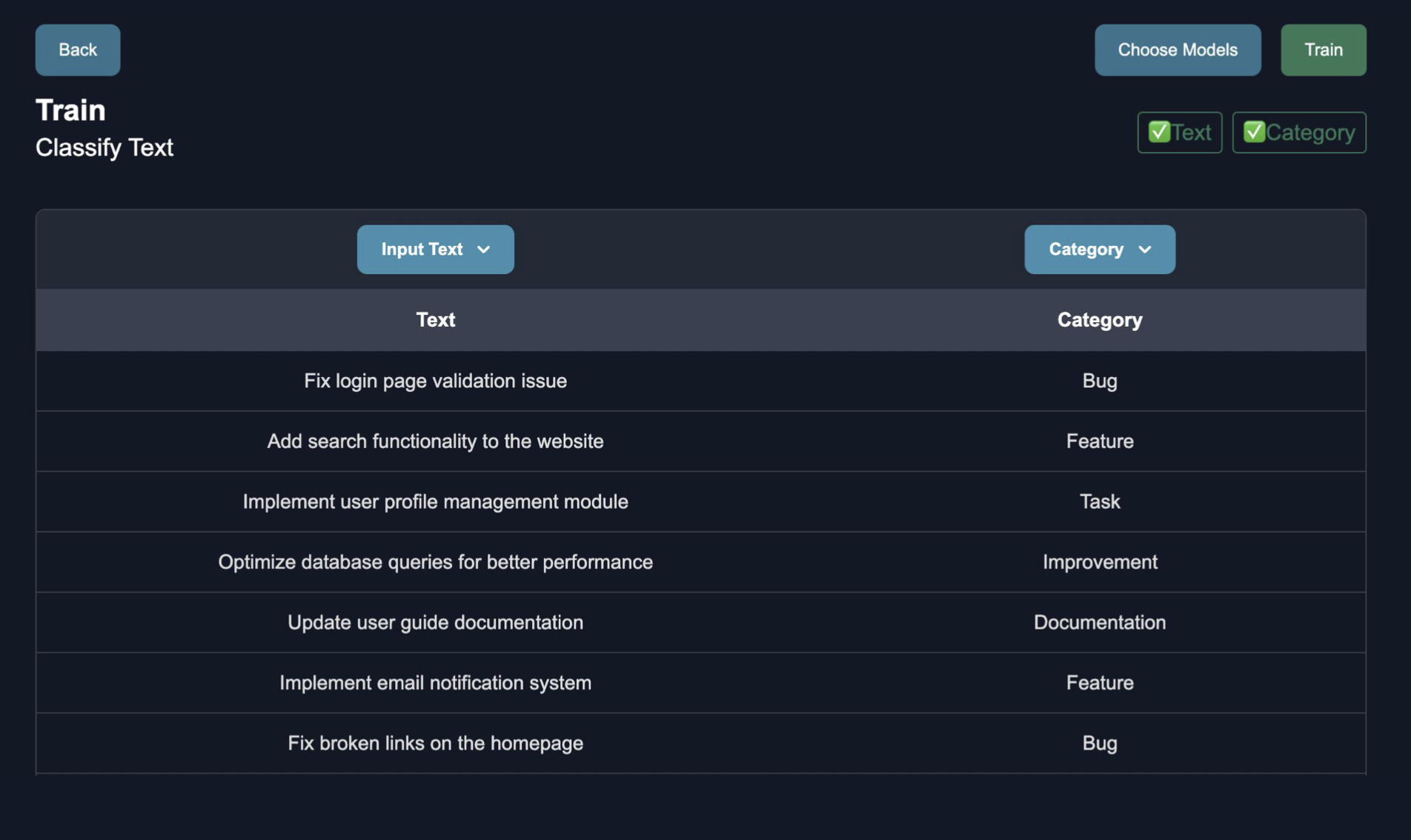
Fine Tuning Overview
Our fine tuning library leverages state of the art few shot learning to make high quality predictions with a few labeled samples. We support a variety of different types of fine tuning, including:
Supervised Fine Tuning: Fine tuning your model on structured, labeled data.
Unsupervised Fine Tuning: Fine tuning your model on raw, unstructured documents.
RLHF Fine Tuning: Actively improve your model from human / AI feedback.
Features
Our fine tuning library has the following features, which enable the end user to obtain the best model for their data:
Model Training: Train models on a variety of NLP tasks using different model types, including zero-shot models, fine-tuned models, and few-shot learning models.
Prediction: Make predictions on single pieces of text or entire datasets, with support for multiple model types and batch processing.
Evaluation: Evaluate model performance using a wide range of metrics, ensuring that your models meet the desired accuracy and reliability standards.
Custom Integration: Seamlessly integrate trained models into your custom workflows, enabling personalized and optimized model deployment across different applications.