Model-Centric AI
In Model-Centric AI, the focus is on the models rather than the training data. The training data is treated as a fixed input, something that is downloaded as a static file. New iterations and improvements of the project are achieved by making changes to the model itself.
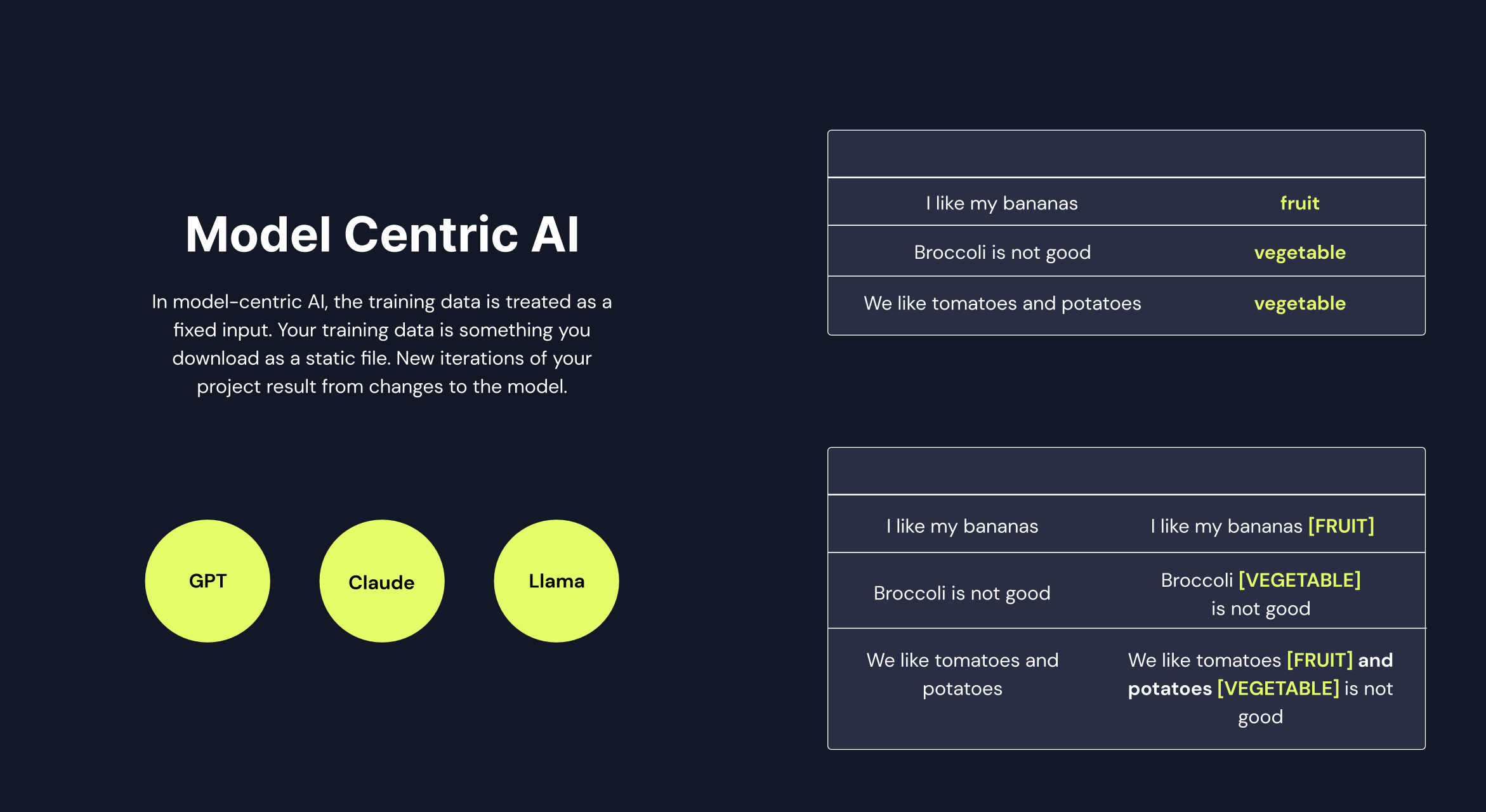
Text Classification Example
Let's consider a simple example of text classification to understand Model-Centric AI in action. Suppose we have the following training data:
| Text | Label |
|---|---|
| I like bananas | Fruit |
| Broccoli is not good | Vegetable |
| We like tomatoes and potatoes | Vegetable |
In Model-Centric AI for classification, the focus shifts to trying different models on static datasets. For instance, we may evaluate models like Naive Bayes, BERT or GPT-3 on this static dataset.
Named Entity Recognition Example
Named Entity Recognition (NER) is another area where Model-Centric AI can be applied. Let's assume we have the following entities:
- Fruits: {Apple, Orange}
- Vegetable: {Zucchini, Spinach}
Here's an example of how the training data may be transformed in Model-Centric AI for Named Entity Recognition:
| Entity_Text | Entity_Label |
|---|---|
| I like bananas | I like bananas [FRUIT] |
| Broccoli is not good | Broccoli [VEGETABLE] is not good |
| We like tomatoes and potatoes | We like tomatoes [FRUIT] and potatoes [VEGETABLE] |
In Model-Centric AI for NER, we can try different models on the static datasets. By exploring and evaluating various models, we can select the one that performs best on the given dataset.
Summary
Model-Centric AI enables flexibility in experimenting with different models, configurations, and techniques to achieve optimal results. It allows for iterative improvements to the model without changing the underlying training data.