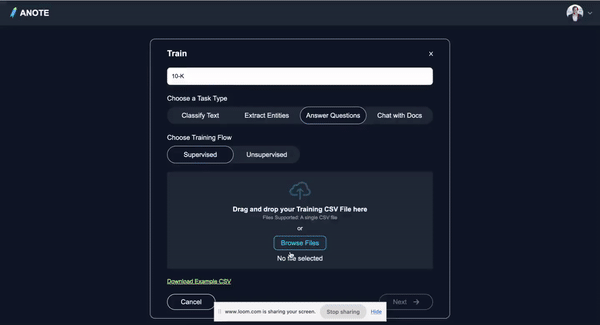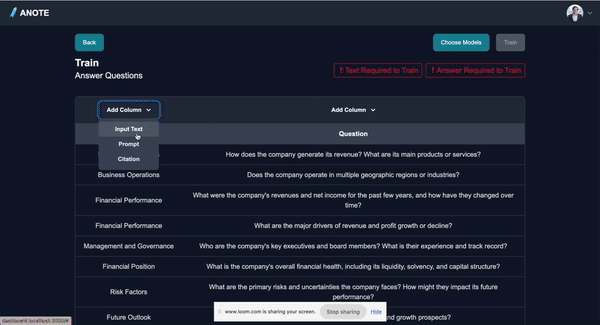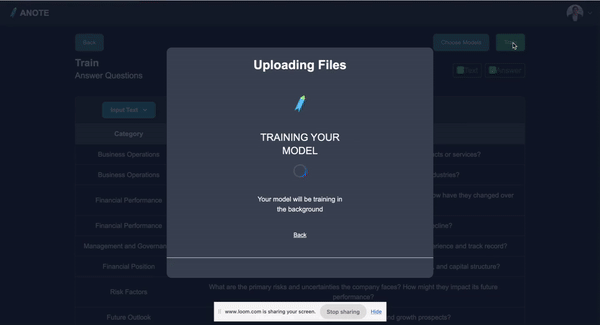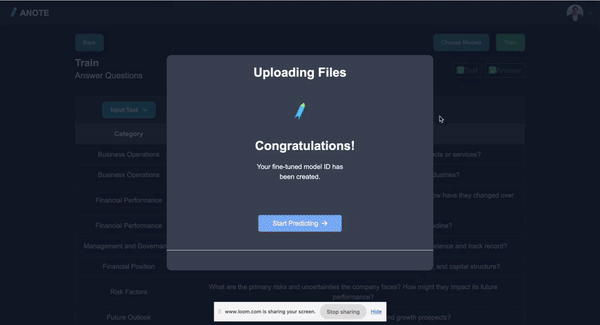
Supervised Fine Tuning
To improve from the baseline model performance, we will do supervised fine tuning on targeted questions and answers within the financial domain, that way the model can better serve analysts and industry professionals who require precise and reliable answers to questions.
Training Process
To do supervised Fine-Tuning, the process includes:
- Loading the FinanceBench dataset, a structured dataset that includes questions about financial statements / company performances, paired with corresponding answers / context.
- Extracting questions, answers, and contexts as training data, alongside the document links.
- Conducting supervised training with the Fine Tuned GPT library to enhance the model’s accuracy and contextual understanding for financial texts.
from datasets import load_dataset
from anoteai import Anote
api_key = 'INSERT_API_KEY_HERE'
Anote = Anote(api_key, isPrivate=False)
# Traing Fine Tuned Model using FT-GPT on Financebench
dataset = load_dataset("finance_bench")
train_df = dataset["train"].to_pandas()
x_train = train_df["question"]
y_train = train_df[["answer", "context"]]
file_paths = list(train_df["doc_link"])
fine_tune_model_id = Anote.train(
x_train_csv=x_train,
y_train_csv=y_train,
model_name="fine_tuned_gpt_on_financebench",
model_type="ft_gpt",
fine_tuning_type="supervised",
file_paths=file_paths
)['id']
Testing the Model
After fine-tuning, the model is tested on a separate testing dataset, such as Bizbench, to evaluate its effectiveness in a practical scenario. This involves using the fine-tuned model to answer the test financial questions.
test_df = pd.read_csv("Bizbench.csv")
# Test Fine Tuned GPT on Bizbench
for i, row in test_df.iterrows():
row["ft_gpt_answer"], row["ft_gpt_chunk"] = Anote.predict(
model_name="fine_tuned_gpt",
model_id=fine_tuned_model_id,
question_text=row["question"],
context_text=row["context"]
)
test_df[["id", "ft_gpt_answer"]].to_csv("ft_gpt_submission.csv")
Private Version of Supervised Fine Tuning
We can do this same fine tuning process with Llama3 using QLORA for a private version of the supervised fine tuning process.
from datasets import load_dataset
from anoteai import Anote
api_key = 'INSERT_API_KEY_HERE'
Anote = Anote(api_key, isPrivate=False)
# Traing Fine Tuned Model using Llama3 on Financebench
dataset = load_dataset("finance_bench")
train_df = dataset["train"].to_pandas()
x_train = train_df["question"]
y_train = train_df[["answer", "context"]]
file_paths = list(train_df["doc_link"])
fine_tune_model_id = Anote.train(
x_train_csv=x_train,
y_train_csv=y_train,
model_name="ft_llama3_on_financebench",
model_type="llama3",
fine_tuning_type="supervised",
file_paths=file_paths
)['id']
test_df = pd.read_csv("Bizbench.csv")
# Fine Tuned QLORA with Llama3 on Bizbench
for i, row in test_df.iterrows():
row["ft_qlora_answer"], row["ft_qlora_chunk"] = Anote.predict(
model_name="fine_tuned_qlora",
model_id=fine_tuned_model_id,
question_text=row["question"],
context_text=row["context"]
)
test_df[["id", "ft_qlora_answer"]].to_csv("ft_qlora_submission.csv")