Text Classification with Active Learning
Text classification is the process of automatically assigning predefined categories or labels to text documents. It plays a crucial role in various applications such as sentiment analysis, spam detection, and content categorization. While traditional approaches to text classification rely solely on training machine learning models with labeled data, actively learning from human input can significantly enhance the accuracy and efficiency of the classification process.
The Need for Active Classification
In complex scenarios with large and intricate taxonomies consisting of numerous categories and subcategories, relying solely on zero-shot classification predictions may not yield accurate results. The accuracy of categorization using zero-shot techniques might not be sufficient to make sound predictions in these cases. To address this challenge and obtain high-quality predictions tailored to specific domains, active classification is essential. Active classification involves learning from human feedback to improve prediction accuracy.
Definitions
Probability:
Probability (or uncertainty) in text classification refers to the degree of confidence associated with a prediction. It represents how sure we are about the correctness of the predicted label for a given text.
Entropy: Entropy in text classification measures the influence a prediction has on the remaining data. It quantifies the surprise, volitility or information contributed by a predicted label. Higher entropy suggests that the predicted label has a significant impact on the overall classification or decision-making process, while lower entropy indicates that the prediction has less influence.
Stability: Stability in text classification refers to the consistency and robustness of the classification process. It relates to the model's ability to produce consistent predictions despite minor variations in the input data. A stable model generates consistent results, ensuring reliability even with slightly different inputs.
Zero Shot Predictions
Before you make any predictions using generative AI models, it is beneficial to examine the zero-shot model predictions. These zero shot generative models, such as CLAUDE, GPT, BERT, or DistilBERT-base-uncased-MNLI, provide initial predictions on the data sample without any manual annotations. Here are some example zero shot predictions on a spam vs. not spam dataset:
| Text | Predicted | Probability | Entropy |
|---|---|---|---|
| Hi there, You have won a free vacation! Claim now! | spam | 0.95 | 0.42 |
| Dear customer, Your account balance is low. | not spam | 0.58 | 0.82 |
| Congratulations! You've won a million dollars! | spam | 0.97 | 0.36 |
| Urgent notice: Last chance to update your personal information. | spam | 0.92 | 0.51 |
| Hi, How are you doing? Let's catch up soon. | not spam | 0.58 | 0.75 |
| Important notice: Your package has been delivered. | not spam | 0.65 | 0.88 |
Sorting and Annotating Edge Cases
The first step in actively learning from human input is to generate a sorted list of edge cases. Edge cases are defined as samples where the model's predictions are uncertain, conflicting, or prone to errors. To start, the zero models have made a series of initial predictions on the data sample that you have uploaded, with each data sample having a probability score and an entropy score indicating the measure of confidence of the model prediction and the measure of importance of the data sample to the model, respectively:
Lets suppose that the accuracy of the models is low and we want to improve it. To do this, we want to know the data samples that are most important to classifying the dataset and focus on labeling those. To do this, we want to sort the above data by its entropy from highest to lowest:
| Text Body | Predicted | Probability | Entropy |
|---|---|---|---|
| Important notice: Your package has been delivered. | not spam | 0.65 | 0.88 |
| Dear customer, Your account balance is low. | not spam | 0.58 | 0.82 |
| Hi, How are you doing? Let's catch up soon. | not spam | 0.58 | 0.75 |
| Urgent notice: Last chance to update your personal information. | spam | 0.92 | 0.51 |
| Hi there, You have won a free vacation! Claim now! | spam | 0.95 | 0.42 |
| Congratulations! You've won a million dollars! | spam | 0.97 | 0.36 |
Once the sorted list of edge cases is available, human annotators can review and annotate each sample. The samples are rendered on the gui by the order of highest entropy, that way the labels have maximum impact, as shown below:
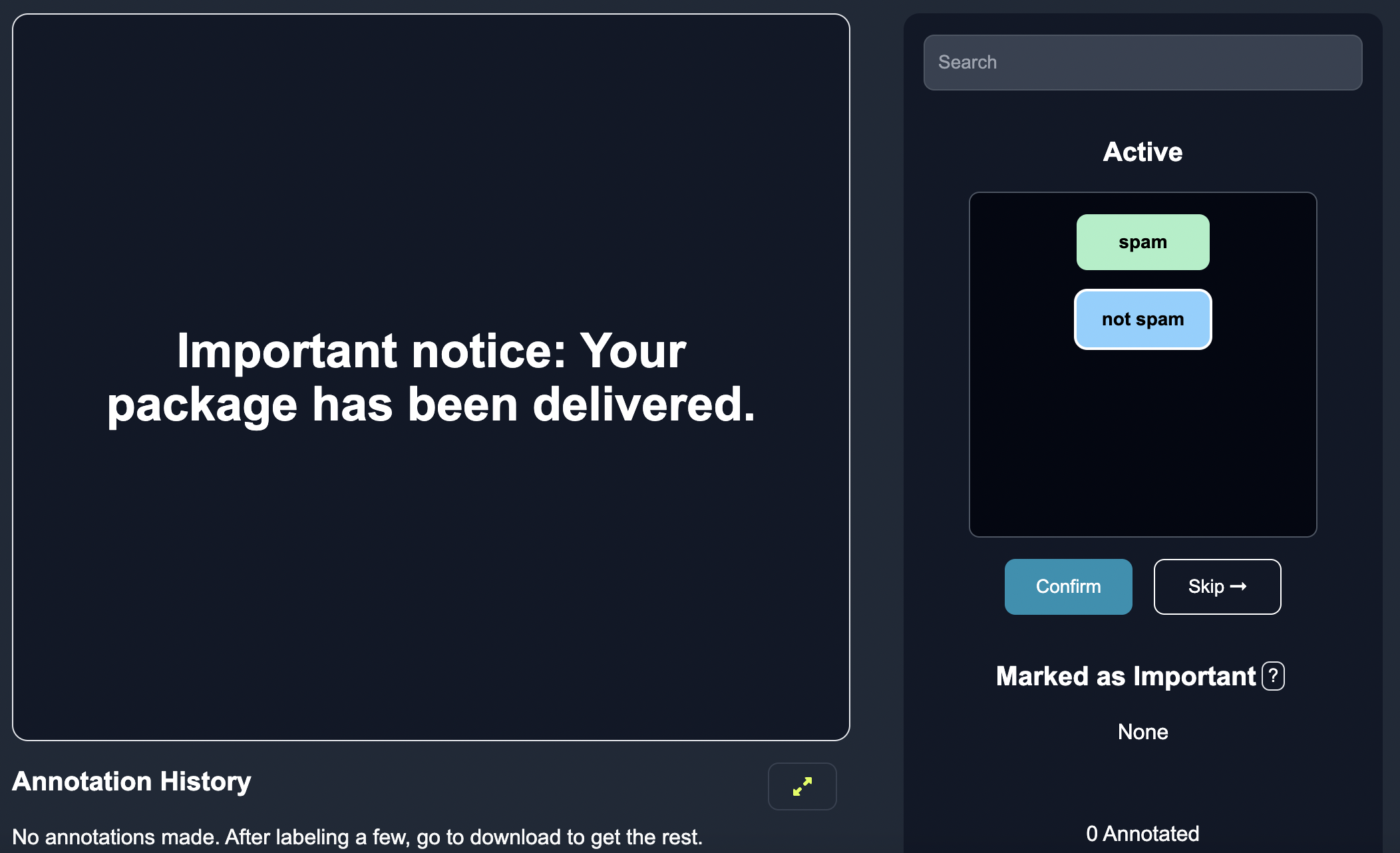
Here, we see the sentence Important notice: Your package has been delivered. which has the highest entropy. This row of data seems legitimate, so we label it not spam. We add this row of data to the annotation history, since it was actually labeled.

Active Learning with Human Annotations
As the human annotates each edge case as listed above in the table, the actively learning system can use this feedback to iteratively refine the classification model. In the example of spam email classification, as we confirm the correct category that the sample belongs to, the model updates based on that label.
For instance, in the table below, the predicted category for Urgent notice: Last chance to update your personal information. was changed to not spam, because the model may have picked up that the word notice was indicative of not spam. The corresponding probabilities and entropies are modified as the actual label is added.
| Text | Actual Label | Predicted | Probability | Entropy |
|---|---|---|---|---|
| Important notice: Your package has been delivered. | not spam | not spam | 1.0 | 0 |
| Urgent notice: Last chance to update your personal information. | not spam | 0.88 | 0.28 | |
| Dear customer, Your account balance is low. | spam | 0.70 | 0.76 | |
| Hi, How are you doing? Let's catch up soon. | not spam | 0.65 | 0.68 | |
| Congratulations! You've won a million dollars! | spam | 0.92 | 0.22 | |
| Hi there, You have won a free vacation! Claim now! | spam | 0.80 | 0.25 |
Iterate on Feedback
We iterate on this process again. The model once again is sorted by entropy, we render the row with the highest potential for impact on the gui.
| Text | Actual Label | Predicted | Probability | Entropy |
|---|---|---|---|---|
| Important notice: Your package has been delivered. | not spam | not spam | 1.0 | 0 |
| Dear customer, Your account balance is low. | spam | 0.70 | 0.76 | |
| Hi, How are you doing? Let's catch up soon. | not spam | 0.65 | 0.68 | |
| Urgent notice: Last chance to update your personal information. | not spam | 0.88 | 0.28 | |
| Hi there, You have won a free vacation! Claim now! | spam | 0.80 | 0.25 | |
| Congratulations! You've won a million dollars! | spam | 0.92 | 0.22 |
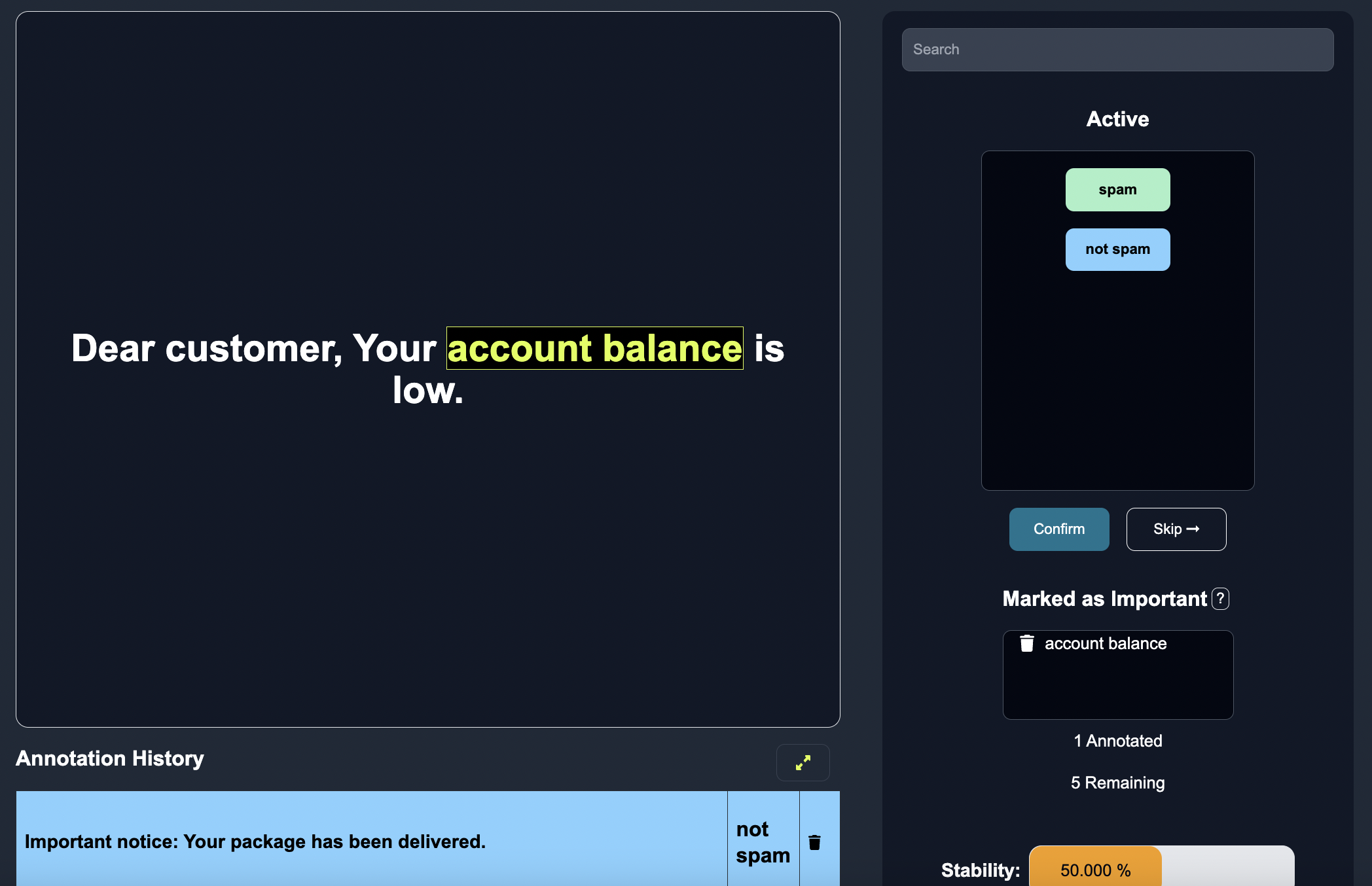
Here, we see the sentence Dear customer, Your account balance is low. which has the highest entropy of the non-labeled data points. We label this row as spam, largely due to the fact that the sentence is referring to account balance. Notice how this row of text data, with the corresponding label, is added to the annotation history once we confirm the annotation.
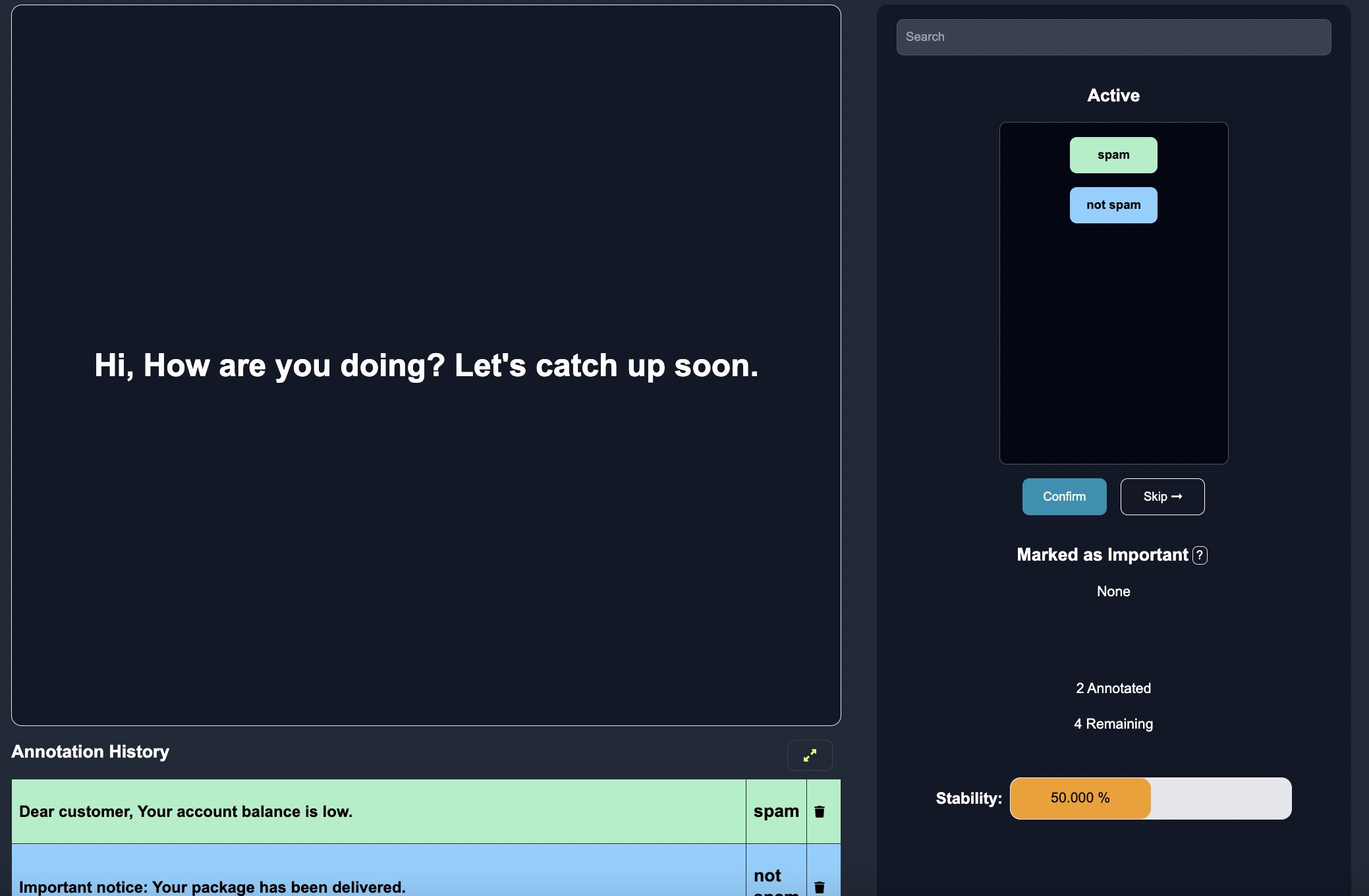
After this second label, the models predictions, uncertainty and entropy is adjusted once more.
| Text | Actual Label | Predicted | Probability | Entropy |
|---|---|---|---|---|
| Important notice: Your package has been delivered. | not spam | not spam | 1.0 | 0 |
| Dear customer, Your account balance is low. | spam | spam | 1.0 | 0 |
| Hi, How are you doing? Let's catch up soon. | not spam | 0.80 | 0.62 | |
| Urgent notice: Last chance to update your personal information. | spam | 0.86 | 0.18 | |
| Hi there, You have won a free vacation! Claim now! | spam | 0.75 | 0.20 | |
| Congratulations! You've won a million dollars! | spam | 0.88 | 0.18 |
Notice how over time, the entropy is decreasing as the model is becoming more stable as more human labels are added.
How many labels are needed
Oftentimes, annotators want to know how many labels they need to do to get a point where the accuracy is high enough, and the labels that they will make will not have too much more of an impact. While empirically this is very dependent on the dataset, our stability metric is used to answer the question of when can you stop adding feedback?
Mathematically, we define stability = alpha * entropy
We can break the concept of stability into three distinct buckets based on its value:
Insufficient Stability - Further Improvement Needed (Red): When stability is relatively low, it falls into the category of "Insufficient Stability - Further Improvement Needed." This indicates that the system or model lacks the desired level of stability and requires additional efforts to enhance its performance. In this stage, the system may exhibit more fluctuations and inconsistencies, highlighting the need for more data, fine-tuning, or adjustments to achieve a reliable and consistent state.

Moderate Stability - Making Progress (Yellow): When stability reaches an intermediate level, it falls into the category of "Moderate Stability - Making Progress." At this stage, the system or model has made significant strides in achieving stability. The behavior and predictions are becoming more aligned with the desired outcomes, indicating progress. However, there is still room for further refinement and enhancement to reach the desired level of stability and reliability.
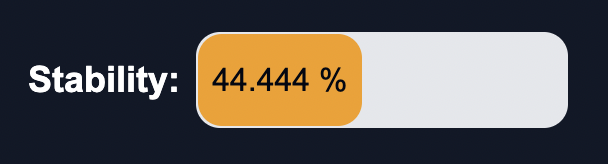
High Stability - Optimal Performance (Green): When stability is high, it falls into the category of "High Stability - Optimal Performance." This signifies that the system or model has attained a desirable level of stability. The behavior and predictions are consistent, reliable, and robust, demonstrating a state of optimal performance. The system operates in a balanced manner and is resistant to minor fluctuations or disturbances. This category represents the desired state where the system has achieved a high level of stability and reliability.

As seen in the plot below, when adding a few annotated labels to a few-shot model, the initial low stability gradually increases. With just a couple of annotations, the stability can increase by more than half, and we move from the Insufficient Stability - Further Improvement Needed bucket to the Moderate Stability - Making Progress bucket. With a few more annotations, the stability becomes even small, indicating reduced uncertainty in the model's predictions. We have now hit a threshold, and are at the High Stability - Optimal Performance bucket, where further annotations will minimally affect the accuracy of the model. By strategically labeling only a fraction of the samples, we can save time while achieving a reliable model with decreased uncertainty, thanks to the iterative process of progressively adding informative annotations.
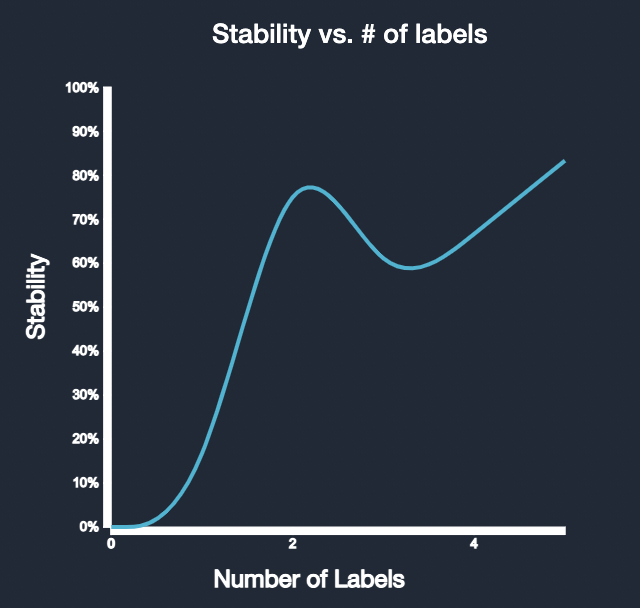
Please note that as you increase the number of samples that are manually labeled, the accuracy increases and the entropy of the entire dataset decreases. Once you hit the stability threshold, no more labels are needed.
Few Shot Learning
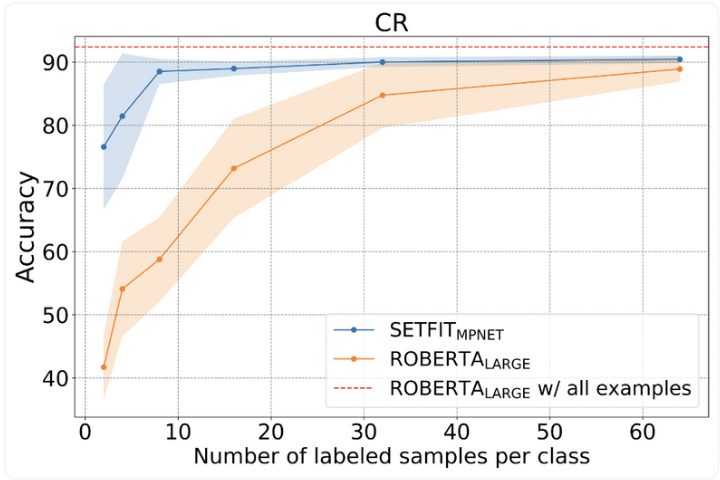
To incorporate human feedback into text classification, one effective approach is to start with few models, such as SetFit, TFew and QAID. After each row of data is labeled, our product actively learns from the data labeler using state-of-the-art Few Shot Learning. With our novel transformer-based Few Shot Learning model, we can learn predictions from a large number of labeled data points in a fraction of the time. Below is a plot of an open source model, Setfit, though you can read more about this in the Few Shot Classification Section.
Identifying Important Features
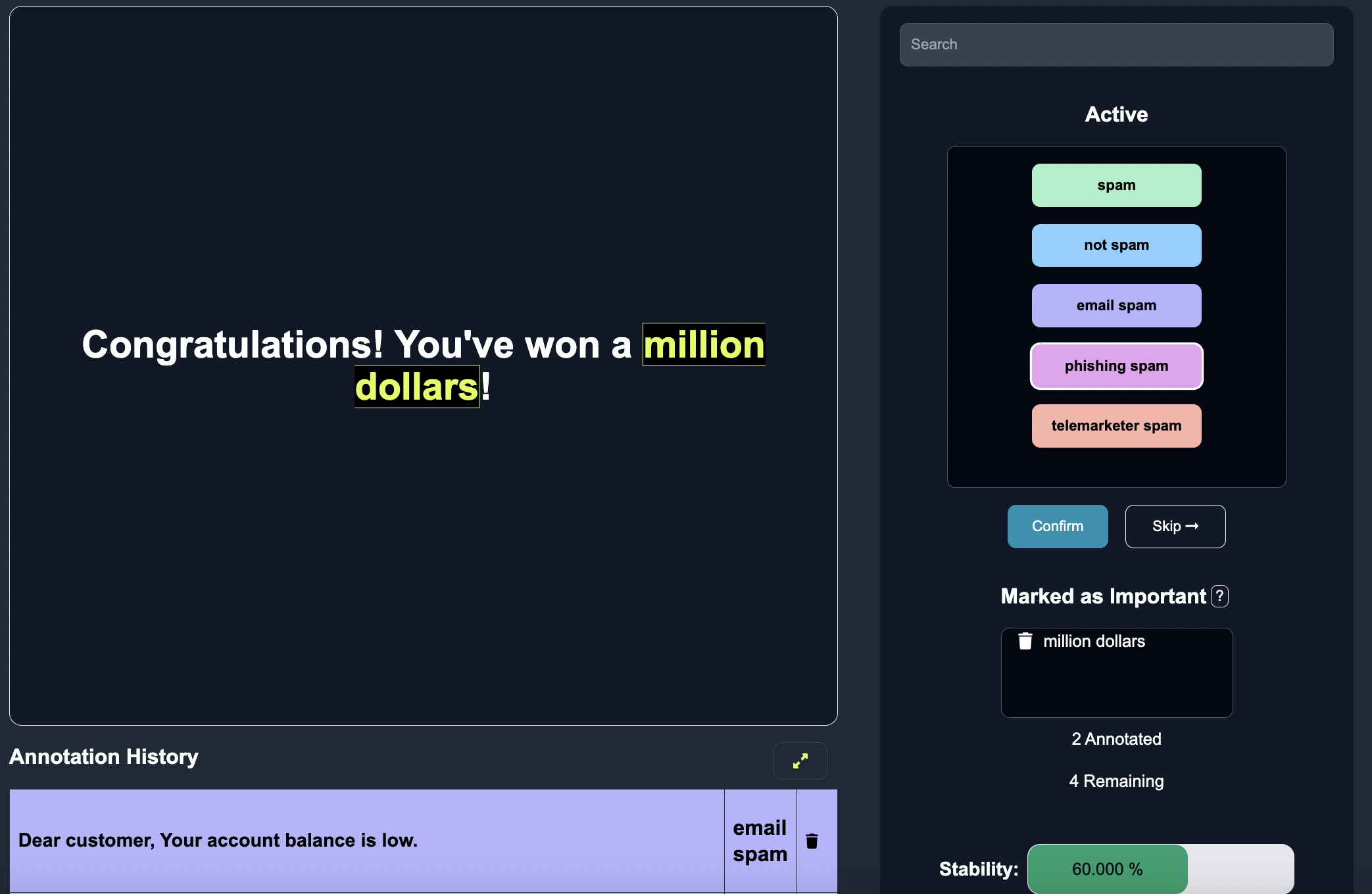
By annotating important features, human annotators can enhance the model's explainability and align it with human expectations. This process involves marking key characteristics and elements for each case, enabling a deeper understanding of the model's challenges and classification influences. To start, an annotator can highlight the key word that is important for the model prediction.
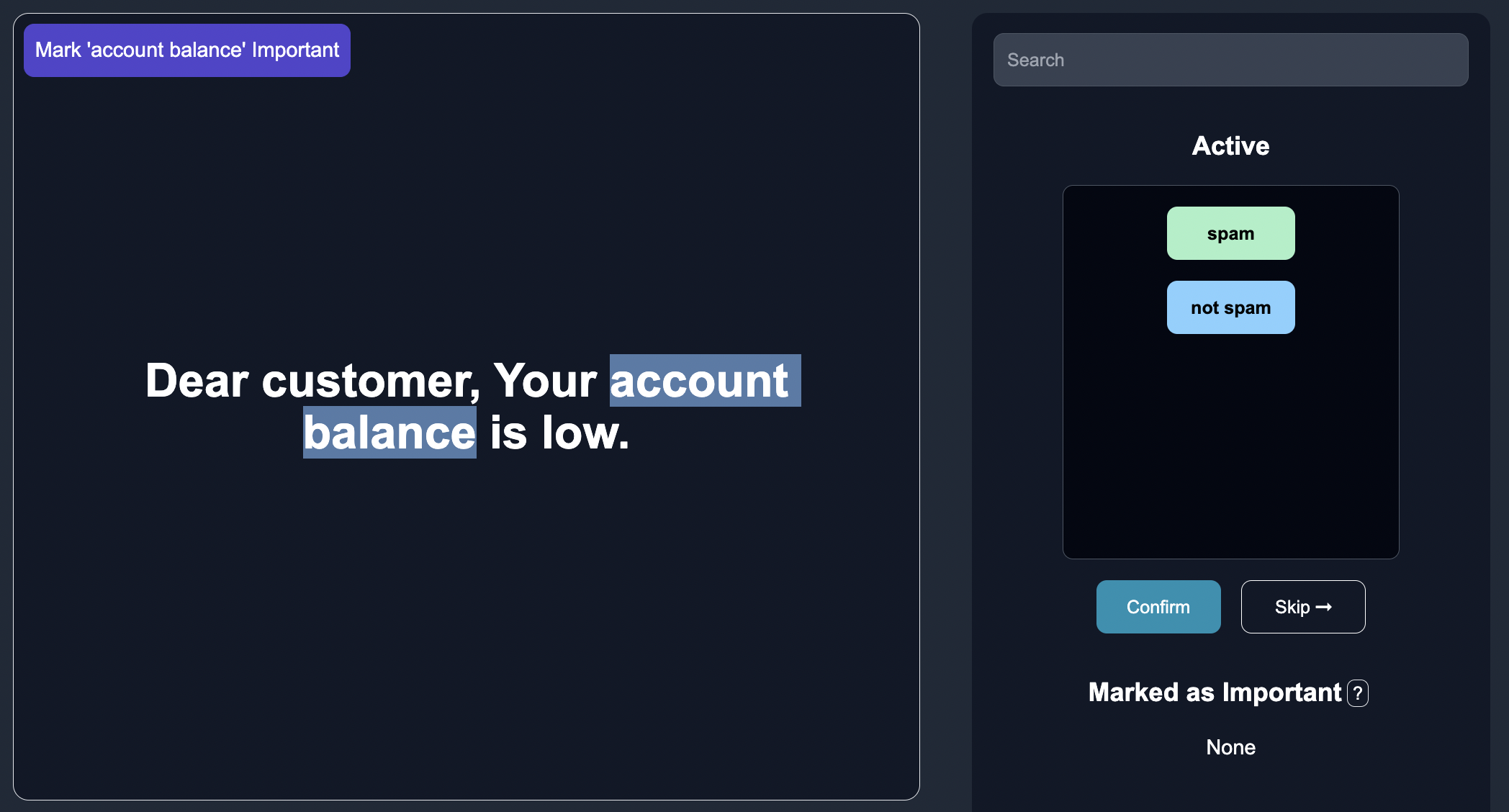
Then they can click on the important button to confirm that the keyword is important.
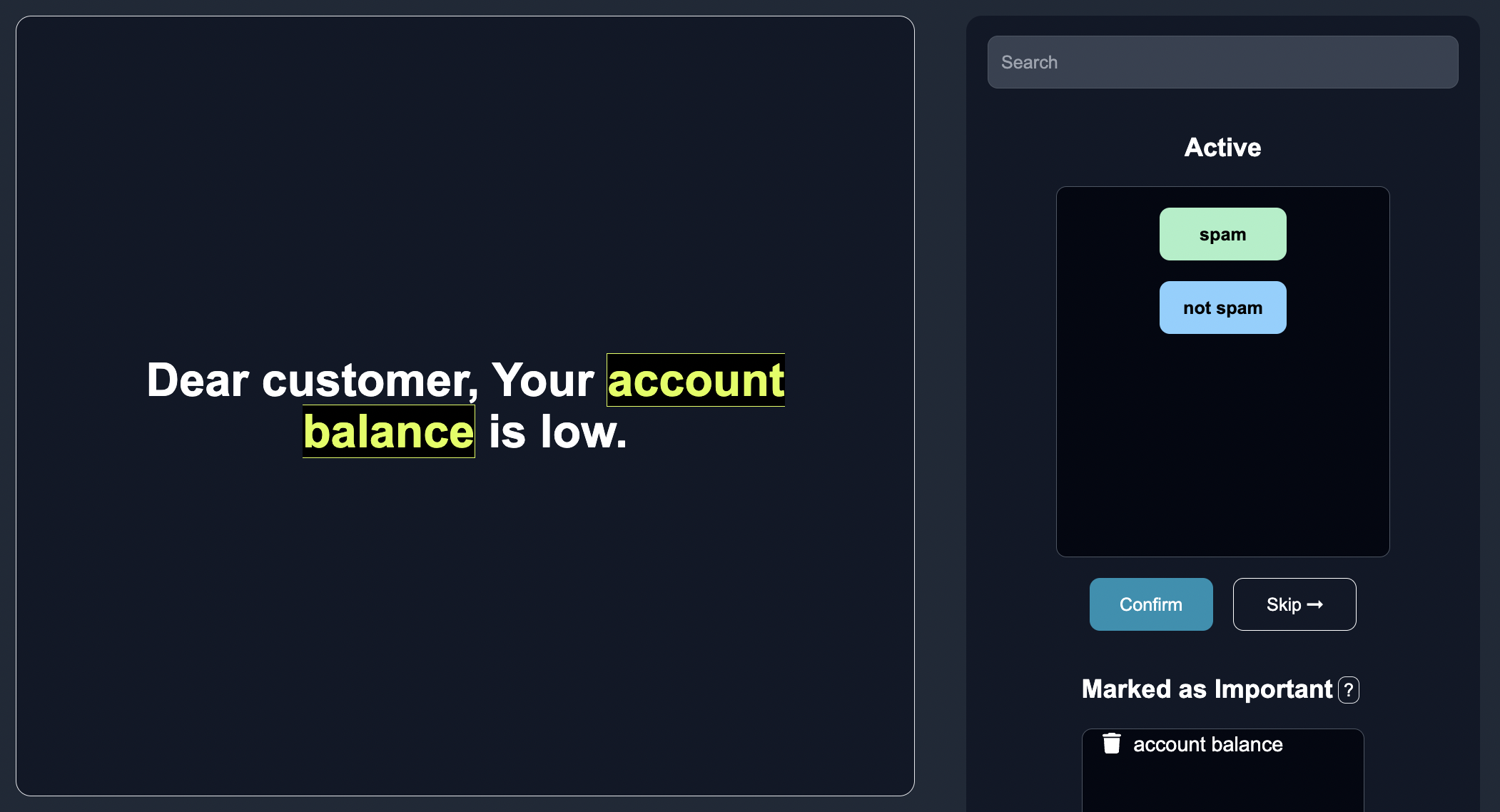
On the backend, we store the important word marked as a separate, hidden row, that is fed into our model to indicate the feature impacted a specific classification.

Incorporating these important features during training allows the model to recognize and interpret them more accurately. This refinement improves the model's performance, transparency, and decision-making process, ultimately leading to more informed and accurate text classification predictions.
Programmatic Labeling Functions
The ontologist is able to infuse their domain specific expertise into the model via programmatic labeling function. The subject matter expert is able to add labeling functions such as keywords or entity matches.
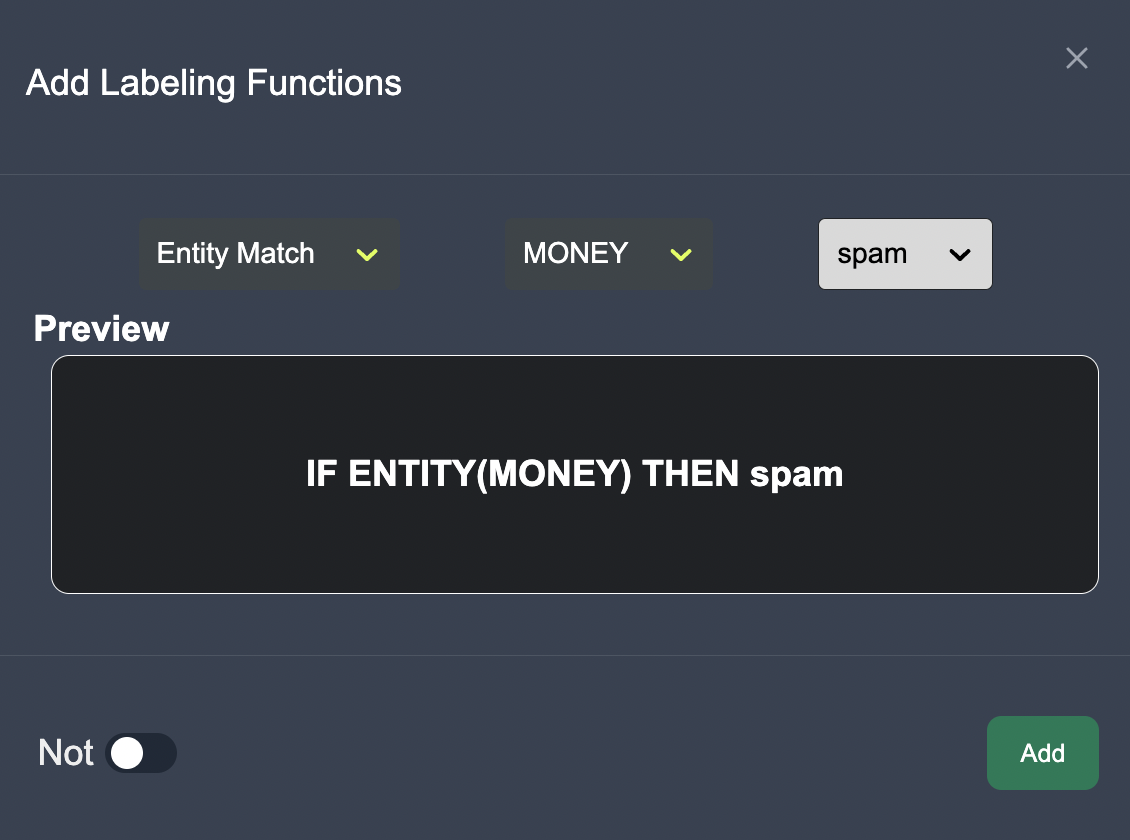
As they add labeling functions, the user can see the resulting labeling functions for each category. The user can also see the coverage of each labeling function in the table below, which they can export to CSV format.
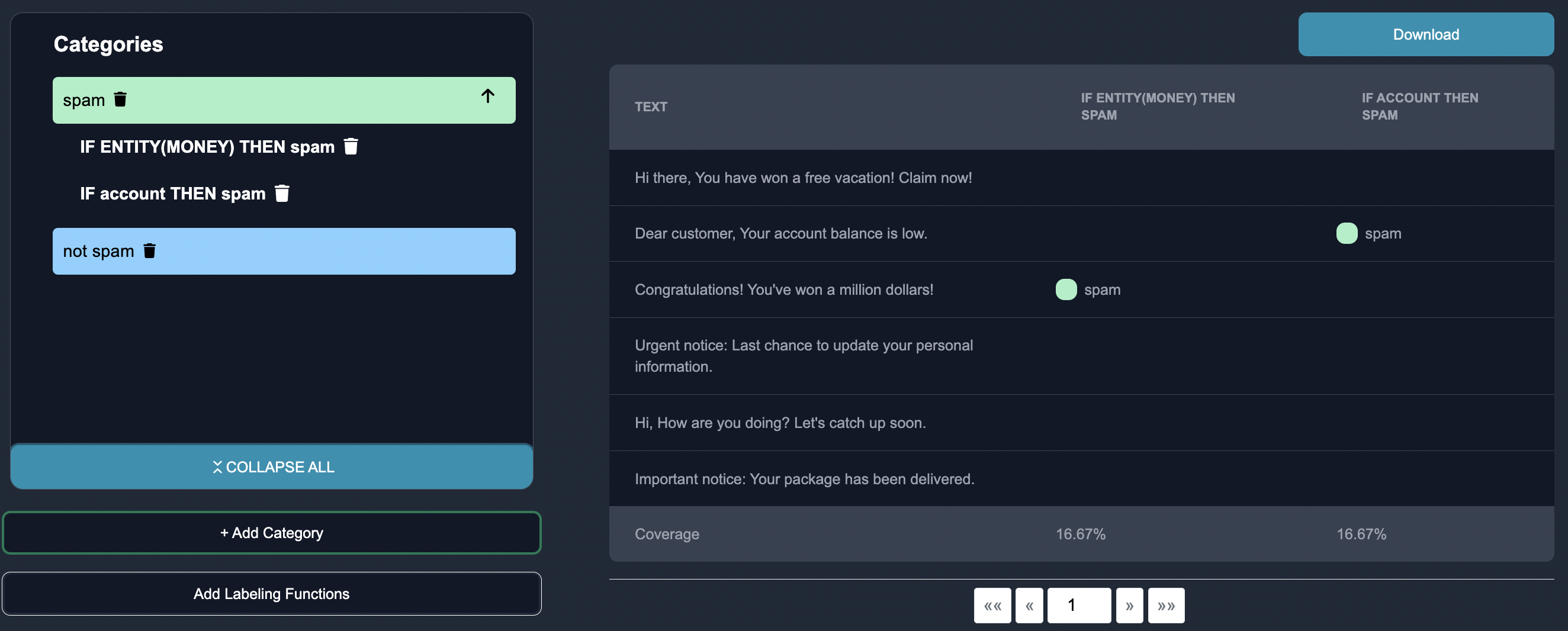
Coverage in the context of labeling functions refers to the proportion of the dataset that can be labeled by a particular labeling function. It represents the ability of a labeling function to provide annotations or labels for the input data points
Ensemble Model
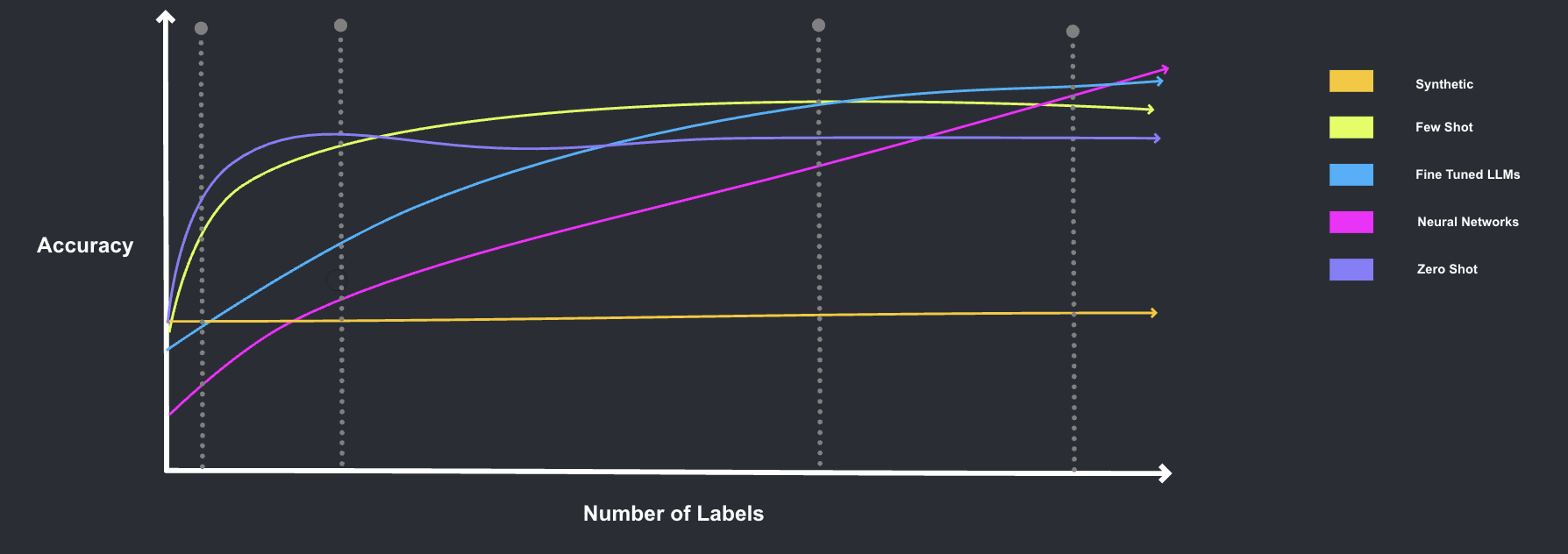
Our model is an ensemble of smaller, faster, and more accurate large language models, customized to domain-specific tasks based on the dataset, document types, and annotations. In other words, our model is a weighted average of many different models, each of which has its own stengths and weaknesses. There are 5 core types of models, which we store in our model registry:
- Zero Shot (GPT, Claude, Spacy): Performs well without the need for specific training or labeled data.
- Few Shot (Setfit, QAID): Can handle a moderate number of labels with limited training examples, performing well even with a few labeled data points.
- Fine Tuned LLMs (Bloomberg GPT, Legal GPT): Specialized models that require a larger amount of labeled data for fine-tuning to perform well in a narrow set of labels.
- Neural Networks (Autoencoders, RNNs): Require massive amounts of labeled data for training to achieve good performance across a wide range of labels.
- Synthetic Data (generated data with GPT): The performance depends on the quality and relevance of the synthetic data generated, which may require significant amounts of labeled data to ensure accuracy.
Please note that these observations are general trends, and the actual performance can still be influenced by factors such as data quality, model architecture, and domain-specific characteristics.

When a user adds a new category, marks a feature as important, or labels a row of data, we run all of our models together. We are able to run these models asychronously, that way the user sees the updated data in their download table instantaneously, though in reality there are many model processes running behind the scenes. We use Ray to parallelize the model running operations, which enables us to run many models on large quantities of data at scale.
@ray.remote
def run_zero_shot_model(datasetId):
# Define model
modelType = ModelType.NO_LABEL_TEXT_CLASSIFICATION
# Train model
train_model_helper(datasetId, modelType)
# Update database with predictions and probabilities
merge_predictions(datasetId, modelType)
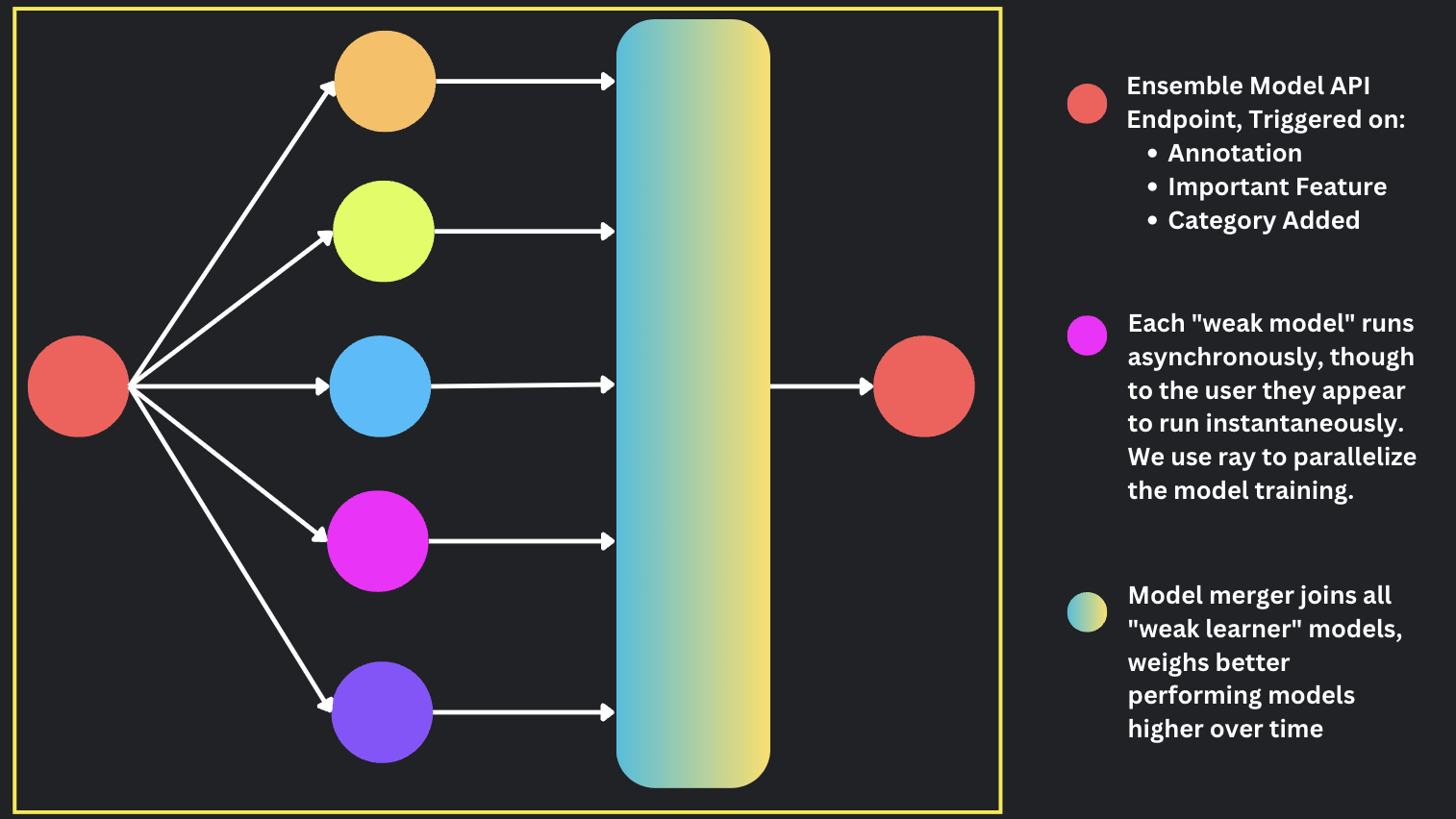
When a given model task finishes running, we ensemble our models together. This enables continuous learning in real-time from the input of people, that way we can choose the best combination of models at any given time.
Merging Logic
The naive way one can merge or ensemble models together is via taking the most common predicted class among the algorithms and calculate the average probability score. In the given example below, the most common predicted class is Spam since it appears in two out of three algorithms. The probability score for the Spam category would be (0.85 + 0.78) / 2 = 0.815.
| Algorithm | Predicted Class | Probability Score |
|---|---|---|
| Algorithm 1 | Spam | 0.85 |
| Algorithm 2 | Not spam | 0.92 |
| Algorithm 3 | Spam | 0.78 |
While it is beneficial to merge many models together to mitigate the weaknesses and biases of individual models, weighing models equally has many limitations. For instance, we would prefer to weigh zero shot models and few shot models higher when there are less labels, and we would prefer to weigh neural networks and fine tuned LLMs higher if our dataset is larger. Within these specific buckets, certain models (i.e.GPT) may be performing better than other models (i.e. Claude) for specific amounts of human feedback, so in the ideal world we would want to choose to best model for a given domain, dataset, and task.
Proprietary Merging Logic
At Anote, we have built proprietary merging logic to fuze many models together. This logic takes a lot of parameters into account, such as stability, entropy, uncertainty, domain, task type, important features marked, labeling functions and the number of labels. This is insanely impactful because we are label to learn the best model as a function of the dataset that we have. As we iterate on the data, we iterate on the many models to choose the best model combination for the end user. What this means is that we are able to convert many weak general purpose models to domain specific use cases.
For example, if you are looking at documents of healthcare data, our model is able to provide you domain specific healthcare results tailored to your use case. As you provide human feedback to the model, the model can recognize over time that you are looking for healthcare inquiries, and can prioritize the healthcare models that would be best for you given your dataset.
Benefits of Active Learning in Text Classification
Active learning for text classification is very useful. With many complex taxonomies and ontologies, accuracy becomes a massive problem. There really is no way to actually get accurate enough results with zero shot models, but you shouldnt have to label every row of data. Active learning at a minimum is as good as a zero shot model, and at minimum is as good as labeling millions of rows of data in your current workflow. In addition, active learning with text classification offers several advantages.
Efficiency: By involving human annotators, we are able to dramatically speed up the training process. For certain domain-specific tasks, our goal is to leverage active learning to accurately predict the labels of one million rows of data with just one thousand labels. This saves data annotators time with the remaining 999,000 rows of data while still incorporating their subject matter expertise into the AI model. For contrast, in normal workflows, teams of 50 to 100 annotators need to label millions of rows of data before the AI team could even train their models.
Explainability: Incorporating human feedback and marking important features contributes to interpretability, allowing better understanding of the model's decision-making process. This transparency is essential for building trust, addressing biases, and ensuring ethical considerations in text classification applications.
Accuracy: Active classification is crucial for obtaining accurate results in intricate categorization tasks. It allows the model to leverage human expertise, learn from corrections and annotations, and achieve tailored, domain-specific predictions. This iterative learning process empowers the model to provide more reliable and valuable insights, especially in situations where zero-shot classification predictions are inadequate.
Domain Specific Expertise: By incorporating human feedback into the training process, the machine learning model can refine its understanding of the complex taxonomies and enhance its prediction capabilities. This harnesses domain expertise and enables the model to learn from their insights, helping improve the accuracy and reliability of the classification model. Through iterative loops of human annotation and model refinement, active classification enables the model to achieve higher-quality predictions tailored to the domain specific expert.
Dataset Versioning: As you provide human feedback, the accuracy of your model improves and gets better over time. We enable end users to save models at given timepoints so you can see how accuracy is affected as you label data. This way you can directly contrast the performance of zero shot models on unlabeled datasets, few shot models on semi-labeled datasets, and fully annotated datasets, to see the results of using Anote firsthand. As an end user, you can easily keep your same workflow, but as you see the cost-benefit analysis of achieving higher data accuracies versus time spent, we let you choose the optimal result for your use case.
Adaptability: As you add new rows of data, add new categories, or as business requirements change, the model is able to adjust accordingly, in real time, with human feedback. In contrast, oftentimes with traditional labeling tasks, annotators will label millions of rows of data, and their labels will become obsolete as new categories and requirements regarding the ontology is needed. This just does not scale when requirements change 15 to 20 times in a project. On Anote, we are able to store the knowledge of previous annotations, and adjust dynamically as requirements change, giving you real time analysis based on your human feedback.
Running End to End on Anote

Let's say for example that you're trying to label a set of emails as spam or not spam. First, you upload the data onto the tool under the Upload tab:
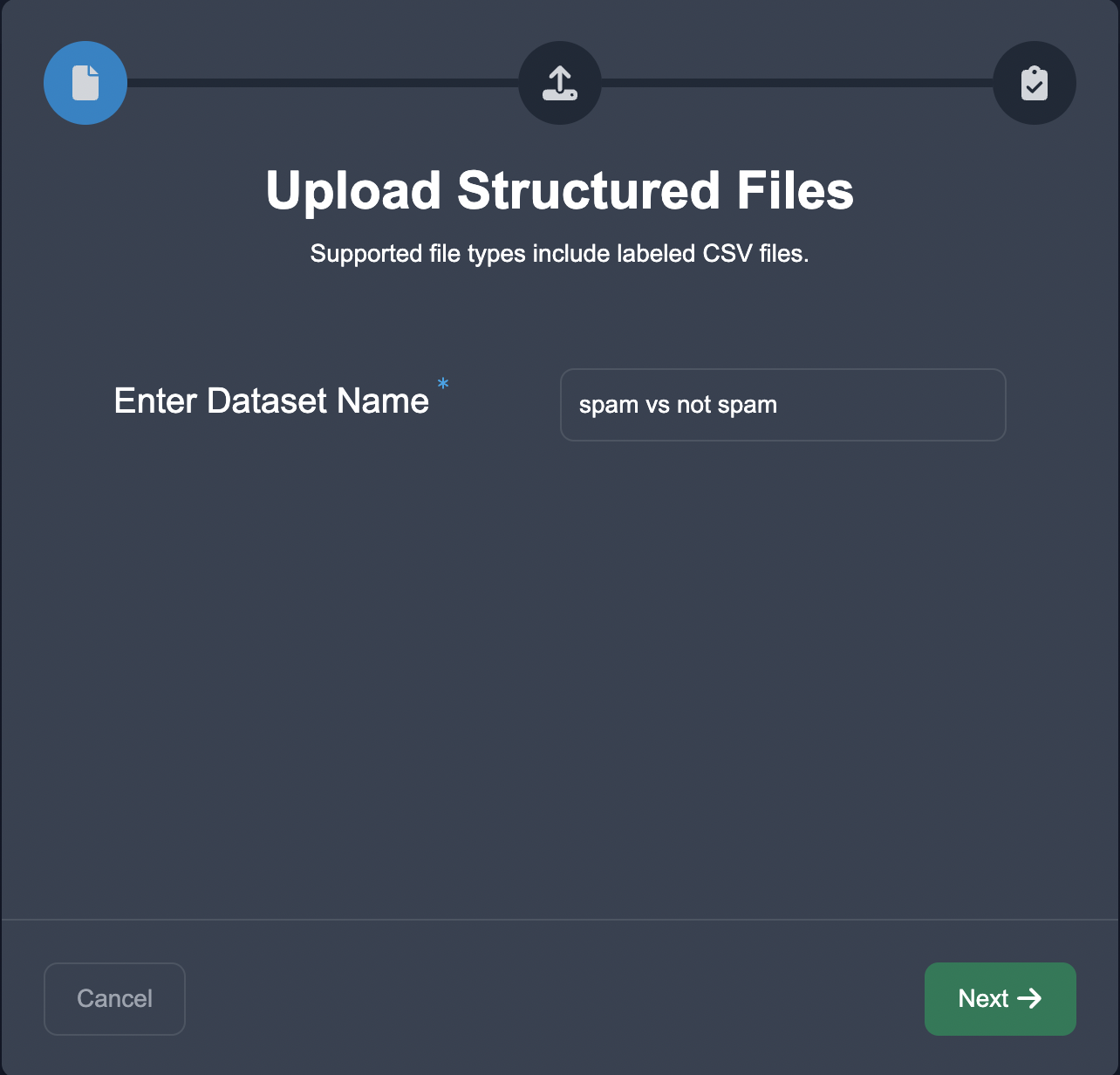
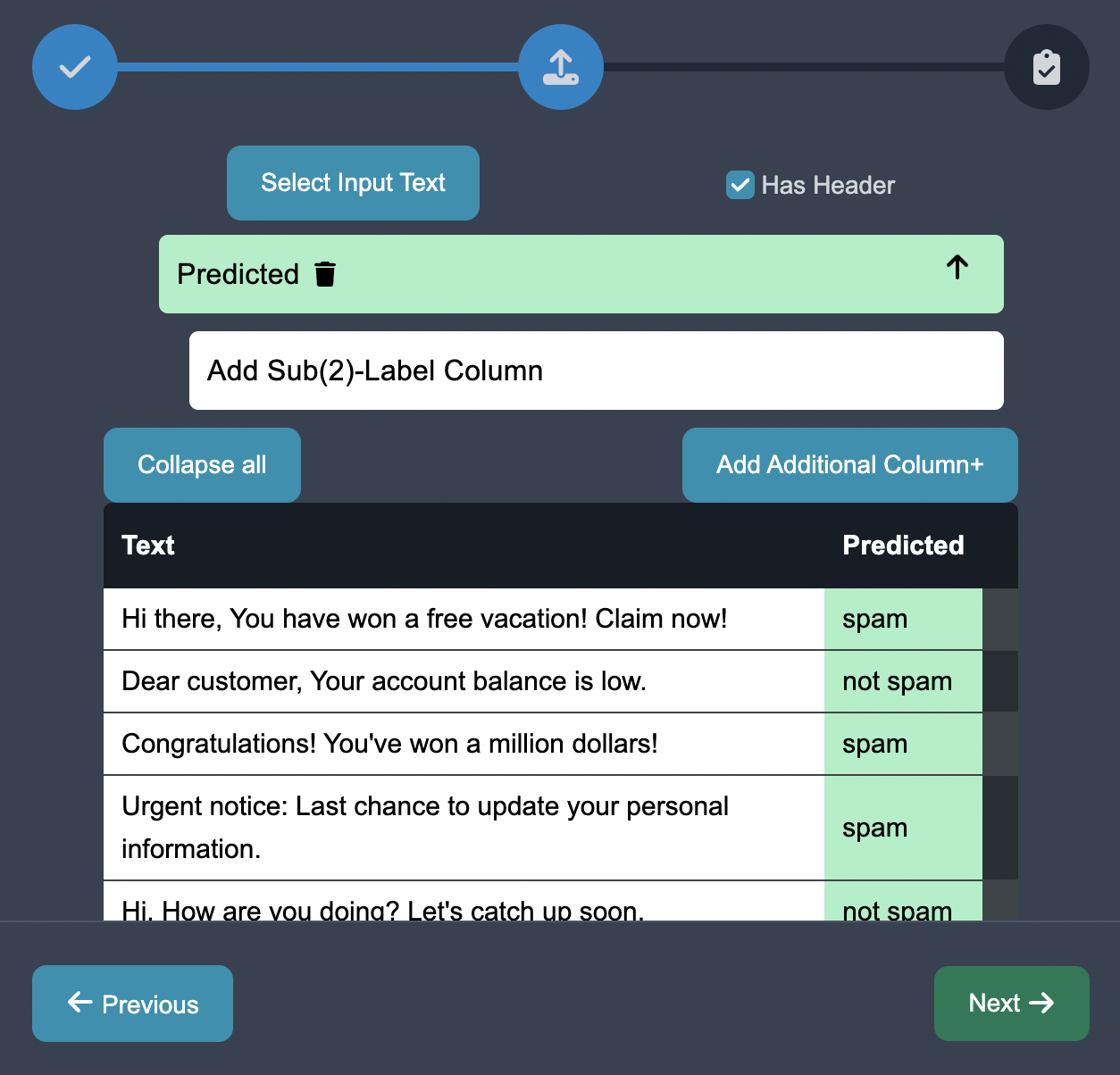
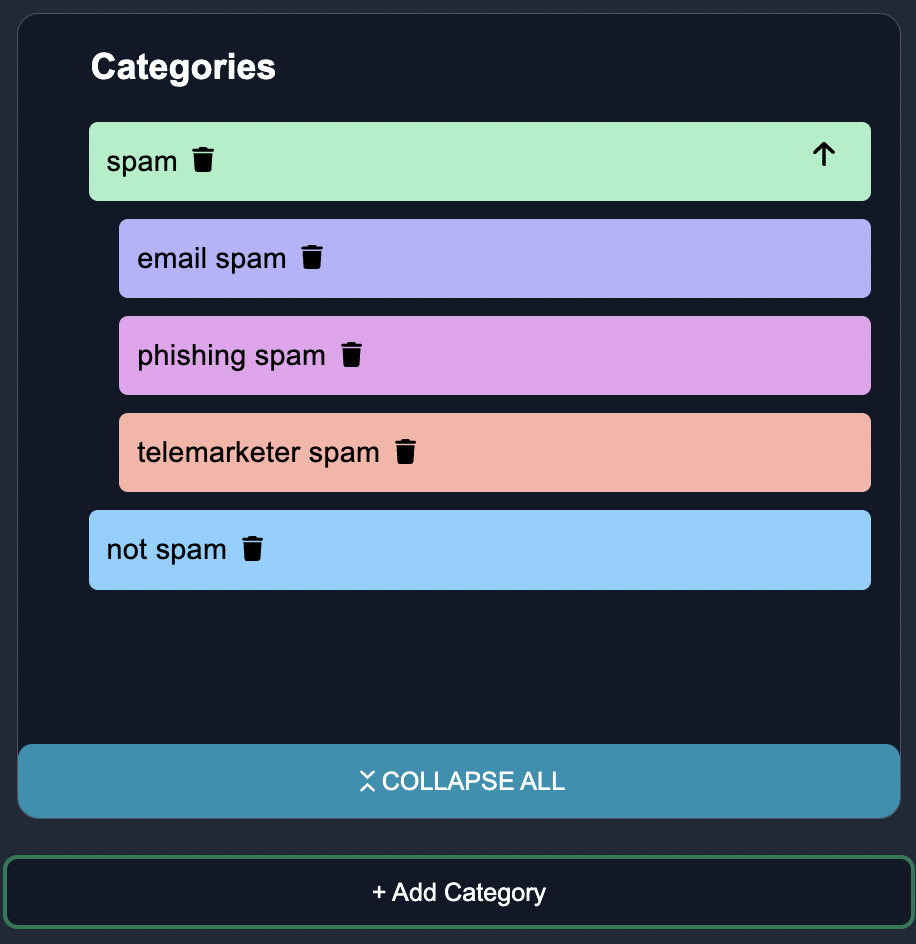
In the subsequent tab Customize, you can add the categories Spam and Not Spam, as well as subcategories of spam such as bitcoin spam and phishing spam:
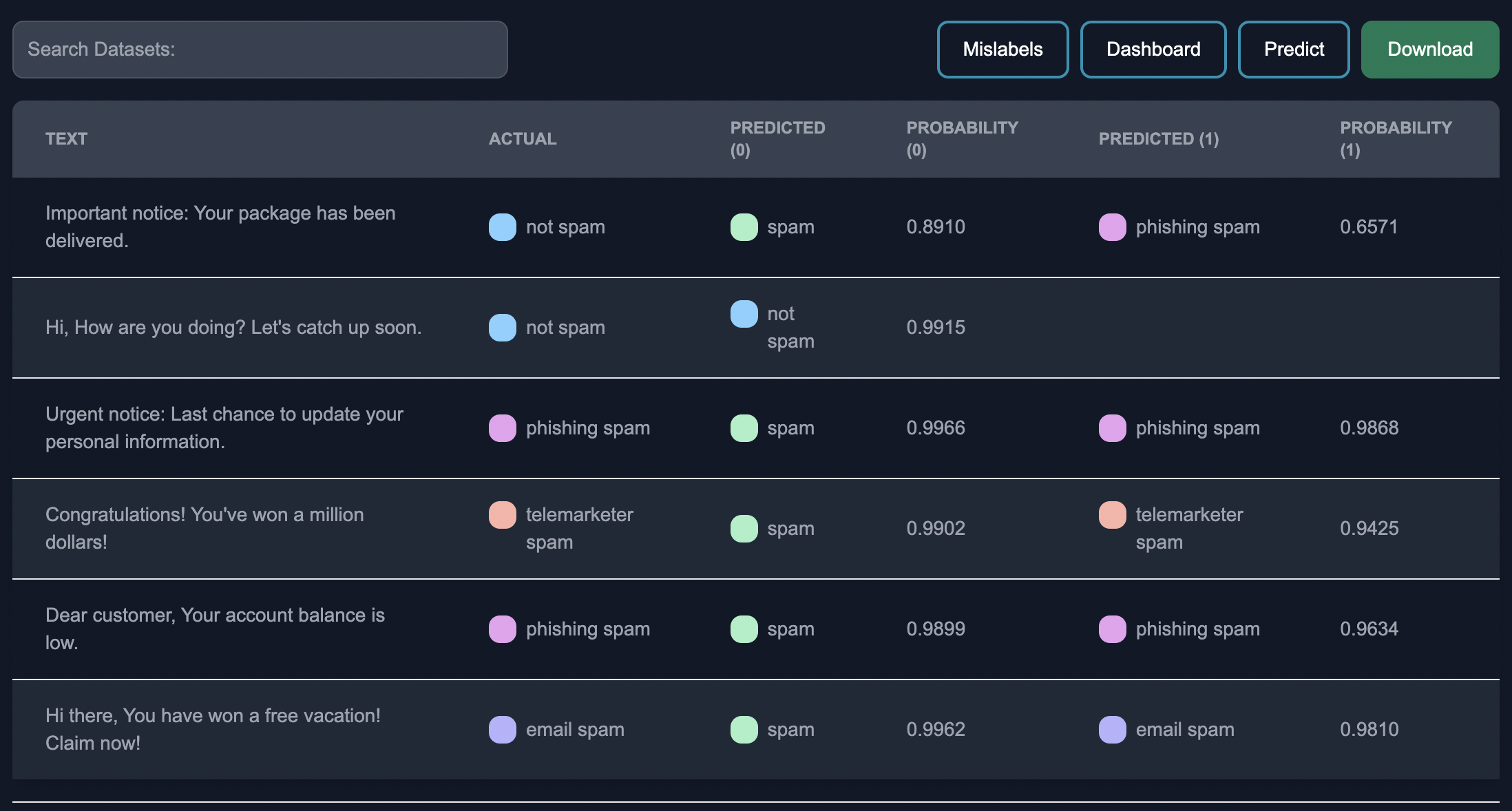
In the subsequent tab Annotate, Annotators assess the correctness of the model's predictions and classify the edge cases into appropriate categories or labels. This annotation process provides valuable feedback and helps identify the model's weaknesses and areas for improvement.
Once finished annotating, you can download the resulting predictions as a CSV in the Download tab.
Summary
Active learning from human input enhances text classification by leveraging generative AI models, filtering by edge cases, and incorporating human feedback to improve the AI models performance. By incorporating human feedback, the model can adapt and improve its predictions over time. Active learning algorithms, such as uncertainty sampling or entropy-based sampling, can dynamically select additional edge cases for human annotation, maximizing the learning potential while minimizing annotation efforts. This iterative approach empowers the classification model to learn from human expertise, improving efficiency, explainability and accuracy in text classification tasks.