Advancements in Few-Shot Learning in NLP
Anote leverages novel breakthroughs in NLP and few shot learning to label unstructured text data in a faster and better way, as well as identify and fix mislabels in structured datasets. Oftentimes, rather than download labeled data, users would like to export their fine tuned model to make improved, more accurate model predictions via our inference API, or interact directly with our APIs via our software developer kit.
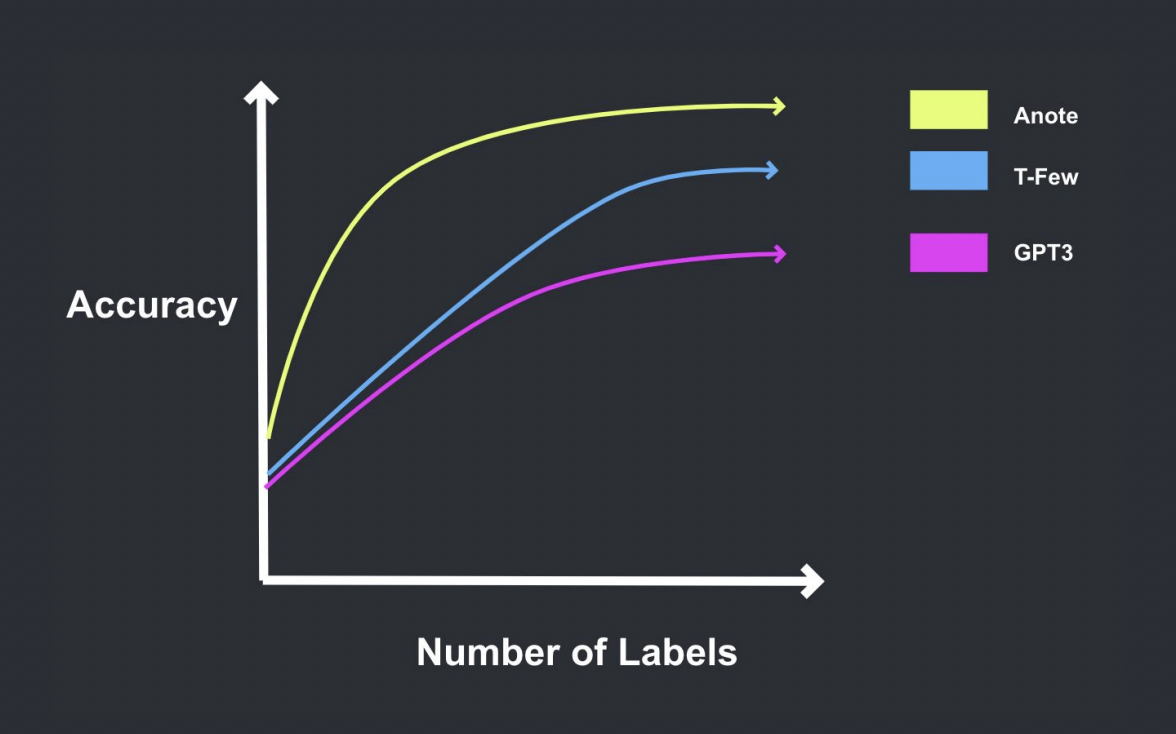
Understanding Few-Shot Learning
Few-shot learning is a subfield of machine learning that focuses on training models to make accurate predictions with only a few labeled examples. In traditional machine learning, models require a large amount of labeled training data to generalize well and make accurate predictions. However, in real-world scenarios, obtaining abundant labeled data may be impractical or expensive.

The unique challenge in few-shot learning is to develop models that can learn effectively from a limited number of labeled examples and generalize to unseen data. This scenario mimics how humans learn, as we can often recognize new concepts or objects with just a few instances or even a single example.
The Key Elements of Few-Shot Learning
-
Small Labeled Training Set (X, Y): In few-shot learning, the training set comprises only a few labeled examples, denoted as (X, Y), where X represents the input data and Y represents the corresponding labels. The labeled examples are typically a small subset of the overall dataset available.
-
Unseen Testing Data (X*): The goal of few-shot learning is to train models that can accurately predict labels for new, unseen testing data denoted as X*. These unseen examples are not part of the initial labeled training set and are used to evaluate the model's ability to generalize.
-
Generalization and Adaptation: Few-shot learning models aim to generalize well beyond the limited labeled examples provided during training. They need to adapt quickly to new tasks or classes with only a few labeled examples, making accurate predictions for unseen data points. The models should capture the underlying patterns and characteristics of the data distribution to make reliable predictions.
The Power of Few-Shot Learning
Few-shot learning, a subfield of machine learning, focuses on the ability of models to generalize and make accurate predictions with limited labeled training data. Traditionally, NLP models required large amounts of labeled data for effective training. However, the advancements in Transformers have transformed the landscape of few-shot learning in NLP.
Transformers
Transformers have revolutionized the field of natural language processing with their attention-based mechanisms, enabling effective modeling of long-range dependencies. The seminal paper "Attention Is All You Need" introduced the Transformer architecture, which has become the foundation for many state-of-the-art models in NLP. Advancements in Transformers have made few-shot learning possible, practical and achievable in many NLP tasks.
Examples of Advancements
Several research papers demonstrate the advancements in Transformers and few-shot learning, making it more practical and effective:
-
BERT: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" by Devlin et al. showcased the power of pre-training with Transformers. BERT achieved state-of-the-art performance on various NLP tasks, even with limited labeled data. Read more
-
GPT-3: "Language Models Are Few Shot Learners" by Brown et al. introduced GPT-3, a massive language model capable of generating coherent and contextually appropriate text. GPT-3 demonstrated impressive few-shot learning capabilities, enabling accurate predictions with minimal fine-tuning. Read more
-
Flamingo: "Flamingo: a Visual Language Model for Few-Shot Learning" by Li et al. presented Flamingo, a visual language model designed specifically for few-shot learning tasks. Flamingo showcased the potential for leveraging Transformers in few-shot learning scenarios, bridging the gap between visual and textual information. Read more
-
Simple Open-Vocabulary Object Detection with Vision Transformers by Zhu et al. proposed a vision transformer-based approach for simple open-vocabulary object detection. This approach demonstrated the effectiveness of Transformers in few-shot learning tasks related to visual understanding. Read more
-
GLaM: "GLaM: Efficient Scaling of Language Models with Mixture-of-Experts" by Yang et al. introduced GLaM, an approach that efficiently scales language models using a mixture-of-experts framework. GLaM demonstrated enhanced few-shot learning capabilities by leveraging expert knowledge and a scalable architecture. Read more
-
PRODIGY: "PRODIGY: Plug and Play Method for Unsupervised Few-Shot Learning" by Schick et al. introduced PRODIGY, a method for unsupervised few-shot learning that leverages contrastive self-supervised learning and pre-training with a language model.
-
X2L: "Cross-Modal Transfer Learning for Few-Shot Classification" by Wang et al. presented X2L, a cross-modal transfer learning approach for few-shot classification tasks. X2L demonstrated the ability to transfer knowledge from different modalities to improve few-shot learning performance.
-
SHOT: "SHOT: A Framework for Self-Supervised Few-Shot Learning" by Tian et al. proposed SHOT, a self-supervised framework for few-shot learning. SHOT leverages self-supervision to learn from unlabeled data and improves few-shot learning performance. Read more
-
FiLM: "FiLM: Visual Reasoning with a General Conditioning Layer" by Perez et al. introduced FiLM, a method for conditional computation in visual reasoning tasks. FiLM enables few-shot learning by conditioning on a small amount of labeled data to perform accurate reasoning tasks. Read more
-
Petal: "Petal: Few-Shot Text Classification with Pattern-based Transformation and Auxiliary Tasks" by Choi et al. proposed Petal, a few-shot text classification approach that leverages pattern-based transformations and auxiliary tasks to improve performance. Petal showcases the effectiveness of few-shot learning techniques in text classification.
These examples demonstrate the diverse range of research papers that have contributed to the advancements in Transformers and few-shot learning in NLP. These approaches leverage innovative techniques, self-supervision, cross-modal transfer learning, and conditional computation to improve few-shot learning performance in various domains.
The progress in Transformers and few-shot learning has opened up new opportunities for developing more adaptable NLP models that can generalize well with limited labeled data. By reducing the dependency on large amounts of annotated data, these advancements have accelerated the development of more practical and versatile NLP systems.
Anote - Building an Efficient, Robust Learning Process
Thanks to the remarkable capabilities of our novel transformer-based few-shot learning model, we can rapidly make high quality predictions for numerous labeled data points with just a few examples. Our goal, particularly for domain-specific tasks, is to accurately predict labels for one million rows of data using just one thousand labeled samples. This approach significantly reduces the burden on data annotators, saving them time while still incorporating their invaluable subject matter expertise into the AI model. Essentially, the process involves labeling a few data points, and our system automatically labels the rest.