Active Prompting using AI: Question and Answering
Question and Answering (Q&A) prompting is a powerful technique that leverages AI to extract specific information from text documents by posing questions. This documentation provides a step-by-step guide to Q&A prompting, including an example, a flowchart to visualize the process, and a table to demonstrate the data format.
Q&A Prompting
Using Anote, you can correct the answers generated by the language model based on your domain knowledge. This means that if you are working with legal documents, precision and accuracy are of utmost importance. With the interactive capability of the system, you can engage in a conversation with the documents and correct any inaccuracies or incorrect answers provided by the model.
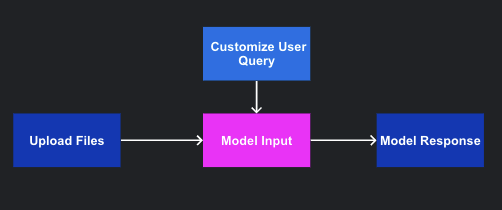
As you actively correct the model's responses and provide the correct answers, the system learns from your inputs. The feedback you provide helps the model understand the nuances of the domain and improve its performance over time. With each interaction and correction you make, the model becomes better at returning accurate and relevant answers. This iterative process ensures that the model adapts and improves, leading to increased accuracy and enhanced performance in answering questions related to your specific domain.
Steps Involved
After the successful loading of documents, the model proceeds with several steps that operate in the background to facilitate the Q&A prompting process. These steps are designed to handle the text documents effectively and extract the necessary information to generate accurate responses. The flowchart below presents a visual representation of the steps involved in Q&A prompting:
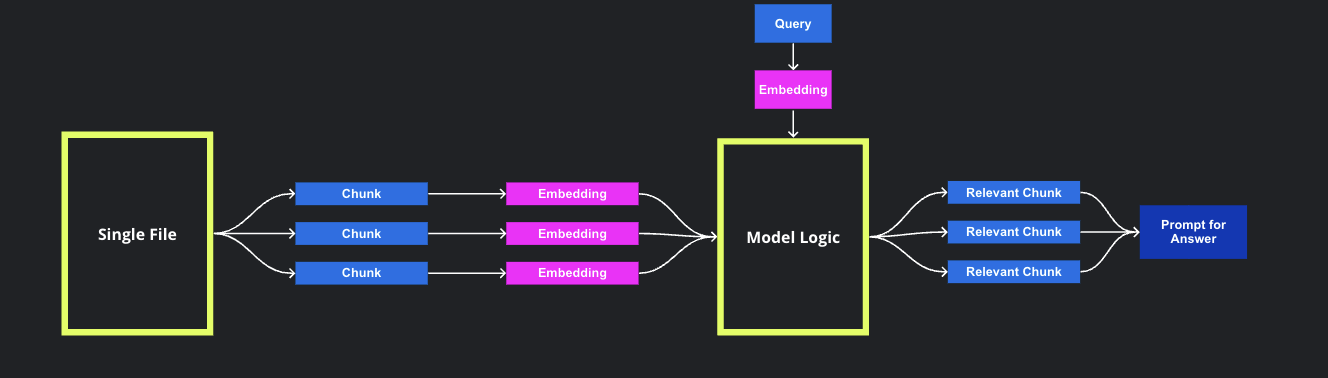
The steps involved are as follows:
-
Text Chunking: Initially, the text document is broken down into smaller, more manageable chunks. By decomposing the text, it becomes easier to analyze and match the content with specific prompts.
-
Chunk Embedding: Each chunk of text is transformed into a numerical representation, typically using embedding techniques such as word embeddings or sentence embeddings. These representations capture the semantic meaning and context of the text chunks.
-
Prompt Embedding: The user's question, known as the prompt, is also transformed into a numerical representation using the same embedding techniques employed in step 2. This enables a meaningful comparison between the prompt and the text chunks.
-
Similarity Matching: The embedded prompt is compared to the embedded text chunks to identify the most similar chunk. This comparison is usually done by calculating a similarity score based on the embeddings. The aim is to find the chunk that best matches the intent of the user's question.
-
Answer Generation: Once the most similar chunk is identified, the AI model generates an answer based on the content associated with that chunk. This can be achieved through a chatbot-like mechanism or by employing predefined responses associated with the matched chunk.
If there is multiple files, the decomposition structure can be very different. Each filetype and specific file should be decomposed and handled in a distinct way, and then will be merged to a singular text embedding. If the number of files or number of rows of text data becomes large, it is recommended to store the embeddings of text in a vector database such as pinecone or weaviate for cloud based offerings, or chroma for local on prem solutions, that way the queries can run efficiently on large corpuses of data at scale.

Once the language model is loaded and trained, you can engage in a conversation with documents using Anote. This interactive capability allows you to interact with text documents and obtain specific information through a question-and-answer format. The model can process various types of documents, including financial documents, legal contracts, research papers, and more.
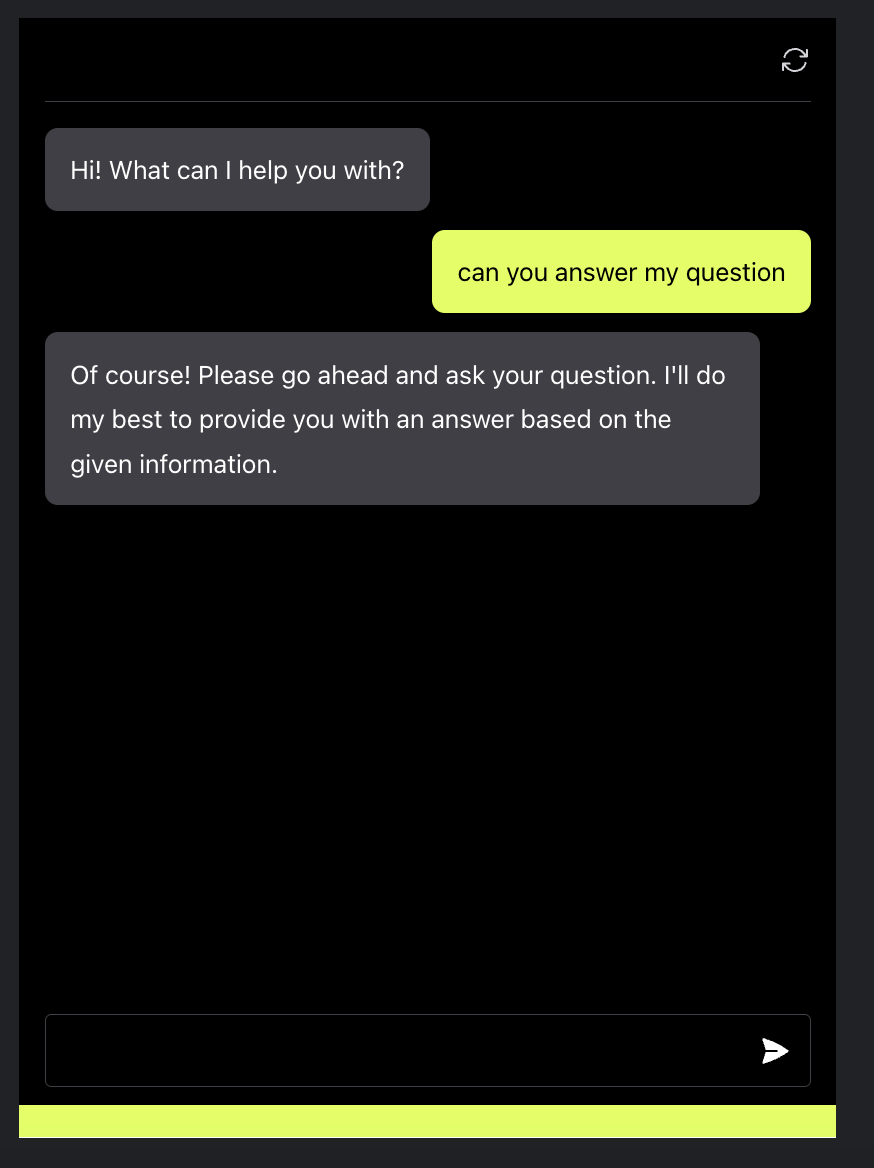
To illustrate the functionality of Q&A prompting, consider the following example. The picture showcases an example of using Anote to analyze a financial document consisting of 150 pages.

The image presents a snapshot of the system's response to a specific query related to the financial document. The generated answer provides valuable insights and information extracted from the document, demonstrating the AI-powered capability of Anote in extracting relevant details from large volumes of text.
One thing to note is that the LLM contains information and context outside of your document as well, pretrained on entire corpus of data to offer diverse perspectives. While the question and answering interface is tailored / fine tuned to your data, you can also ask questions that fall outside of the realm, as seen in the image below.
By leveraging Q&A prompting, you can navigate through lengthy documents efficiently, pose specific questions, and receive targeted responses that assist in understanding and analyzing the document's content. This interactive and conversational approach enhances the effectiveness and productivity of document analysis tasks.
Improving the Large Language Model with Human Feedback
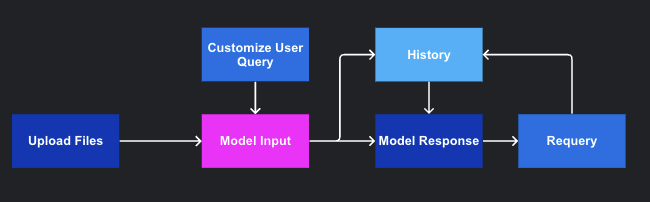
While the Q&A prompting approach aims to provide precise answers, it is important to acknowledge that there may be instances where the generated response is incorrect or lacks accuracy. This is where Anote truly excels. With the power of Anote, you have the ability to improve the overall accuracy by seamlessly integrating human feedback into the process. If the generated answer is identified as incorrect, you are presented with an opportunity to modify it based on your own knowledge and expertise. This iterative feedback loop not only refines the model's responses but also drives continuous improvement, ultimately boosting its performance and ensuring a higher level of accuracy.
At Anote, we employ several techniques to enhance the accuracy of the large language model using human feedback. Once you prompt the model, it generates an answer based on the steps mentioned above. However, if the generated answer is incorrect or inaccurate, you have the option to provide your own answer in the dedicated feedback window.
As you continue to correct the model's answers over time, the model learns from this feedback and adjusts its responses accordingly. Through incorporating human feedback, we continuously refine and enhance the large language model, ensuring that it becomes more accurate, reliable, and aligned with human knowledge and expertise. The goal is to reach a point where the model's predicted answer aligns with the human feedback you provide.
User Feedback Loop
User feedback plays a significant role in improving the question answering capabilities of language models. By analyzing the user's feedback and comparing it with the generated answers, we can enhance the model's performance and accuracy over time.
-
Comparison with User Answers: By comparing the generated answer with the user's answer or expected answer, we can identify discrepancies and areas for improvement.
-
Feedback Integration: Incorporating user feedback into the training process helps the model learn from its mistakes and refine its understanding of questions and answers.
-
Adjustment of Prompts: Based on user feedback, we can adjust the prompts or questions given to the language model to guide it towards more accurate and relevant answers.
-
Fine-tuning and Retraining: By including user-generated question-answer pairs in the training data, we can fine-tune and retrain the model to improve its performance in question answering tasks.
Download Result
Once the model incorporates human feedback and achieves a satisfactory level of accuracy, users have the opportunity to download the report of the Q&A process in a convenient table format. This report provides a structured overview of the questions posed, the model's predictions, and the actual human feedback for each question.
The table format organizes the information in a tabular manner, allowing for easy readability and analysis. The report typically includes the following columns:
- Document: Represents the document or text from which the model is extracting information and generating responses. It can be a PDF, text file, or any other source of information.
- Question: Refers to the user-inputted question or prompt. It is the specific query or inquiry that the user wants the model to answer based on the given document.
- Response: Represents the model's predicted answer or response to the question. It is generated by the language model based on its understanding of the document and the provided question.
| Document | Question | Pred |
|---|---|---|
| Financial Management and Real Options | What is financial management? | Financial management is the process of managing money and other financial resources in order to achieve an organization's goals. It involves planning, organizing, controlling, and monitoring the financial activities of an organization. |
| Financial Management and Real Options | Can you explain the significance of cautiousness in financial management? | Cautiousness is an important concept in financial management because it involves making decisions that are both financially sound and ethical. Cautiousness requires financial managers to consider the long-term consequences of their decisions and to act in the best interests of their organization. |
| Financial Management and Real Options | How does cautiousness contribute to risk management? | Cautiousness contributes to risk management by ensuring that financial managers make decisions that are well-informed and carefully considered. |
Summary
Q&A prompting using AI offers an effective and interactive way to extract specific information from text documents. By following the steps of text chunking, embedding, similarity matching, and answer generation, users can obtain precise answers to their questions. The iterative process of incorporating human feedback ensures continuous improvement, allowing the model to provide more accurate and reliable responses.