10ksdecomposition
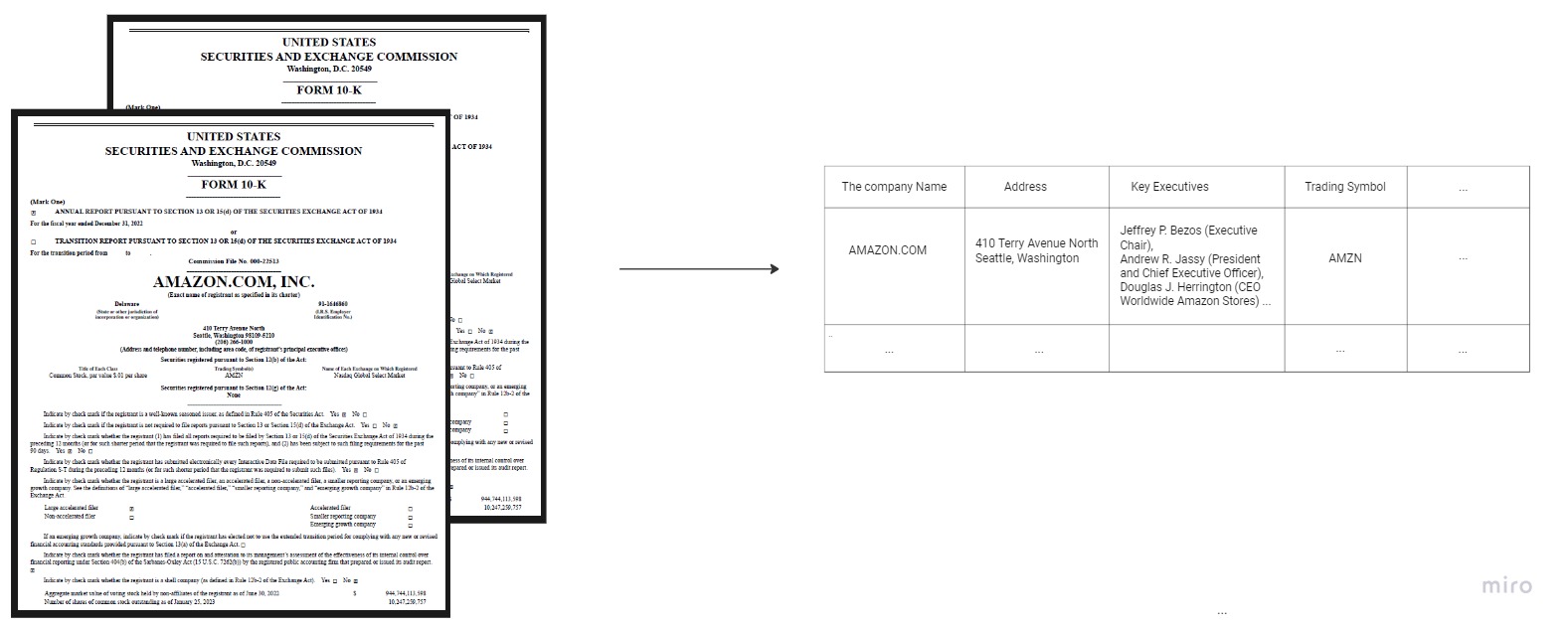
Example of Decomposition of 10-Ks
Decomposing 10-K reports involves extracting sections such as the business overview, financial statements, risk factors, and management discussions. By decomposing 10-Ks, we can analyze the specific sections and extract relevant information for financial analysis, regulatory compliance, or investment decision-making. Here is a code example of how we use unstructured.io to perform document specific decomposition of 10-Ks:
"""## Section 1: Pulling in Raw Documents:
Decomposition: https://github.com/Unstructured-IO/pipeline-sec-filings
Edgar API: https://www.sec.gov/edgar/searchedgar/companysearch
10-K Filings: https://www.sec.gov/edgar/searchedgar/companysearch
First, let's pull in a filing from the SEC EDGAR database.
In this case, we'll pull in the most recent 10-K for Royal Gold (RGLD),
a publicly traded precious metals company.
"""
import nltk
from prepline_sec_filings.fetch import (
get_form_by_ticker, open_form_by_ticker
)
text = get_form_by_ticker(
'rgld',
'10-K',
company='Anote',
email='vidranatan@gmail.com'
)
"""## Section 2: Reading the Document:
The first step is to identify and categorize text elements within the
document. When we get the SEC document from EDGAR, it is in `.xml` format.
Like most text documents, XML documents contains text data we're
interested along with other information that we'd like to discard. In
an XML or HTML document, that could be styling or formatting tags.
Other document types, like PDFs, might have headers, footers, and page
numbers we're not interested in.
To help with this, Unstructured has created a library of
***partitioning bricks*** to break down a document into coherent chunks.
Different document types have different partitioning methods. For HTML
or XML documents, we identify sections based on text tags and use
NLP to differentiate between titles, narrative text, and other section
types. For PDF documents, we use visual clues such as the layout of the
document.
"""
from unstructured.documents.html import HTMLDocument
html_document = HTMLDocument.from_string(text).doc_after_cleaners(skip_headers_and_footers=True, skip_table_text=True)
"""Here, we see that the `HTMLDocument` Brick was able to extract
text from the raw source XML document. This is a generic
`HTMLDocument` class that does not have any special knowledge about
the structure of EDGAR documents.
"""
for element in html_document.pages[0].elements[71:75]:
print(element)
print("\n")
"""## Section 3: Custom Partitioning Bricks:
In addition to the partitioning bricks Unstructured provides out of the
box, a given recipe may require custom partitioning bricks. In this case,
we're interested in identifying sections within the SEC filing. To
support that, we'll create a custom partitioning brick to identify
section titles. This will help distinguish section headings from sub-headings.
"""
import re
from unstructured.documents.elements import Title
ITEM_TITLE_RE = re.compile(
r"(?i)item \d{1,3}(?:[a-z]|\([a-z]\))?(?:\.)?(?::)?"
)
def is_10k_item_title(title: str) -> bool:
"""Determines if a title corresponds to a 10-K item heading."""
return ITEM_TITLE_RE.match(title) is not None
"""## Section 4: Cleaning Bricks:"""
from unstructured.cleaners.core import clean_extra_whitespace
titles = []
for element in html_document.elements:
element.text = clean_extra_whitespace(element.text)
if isinstance(element, Title) and is_10k_item_title(element.text):
titles.append(element)
print(element)
With robust document decomposition, we can find key information in 10-Ks, as seen in the image below: