Evaluation Overview
Anote provides evaluation workflows for measuring model quality across classification, named entity recognition, and question answering tasks. These docs cover how to benchmark model behavior, compare systems, inspect failure cases, and use both human feedback and automated metrics to improve reliability over time.
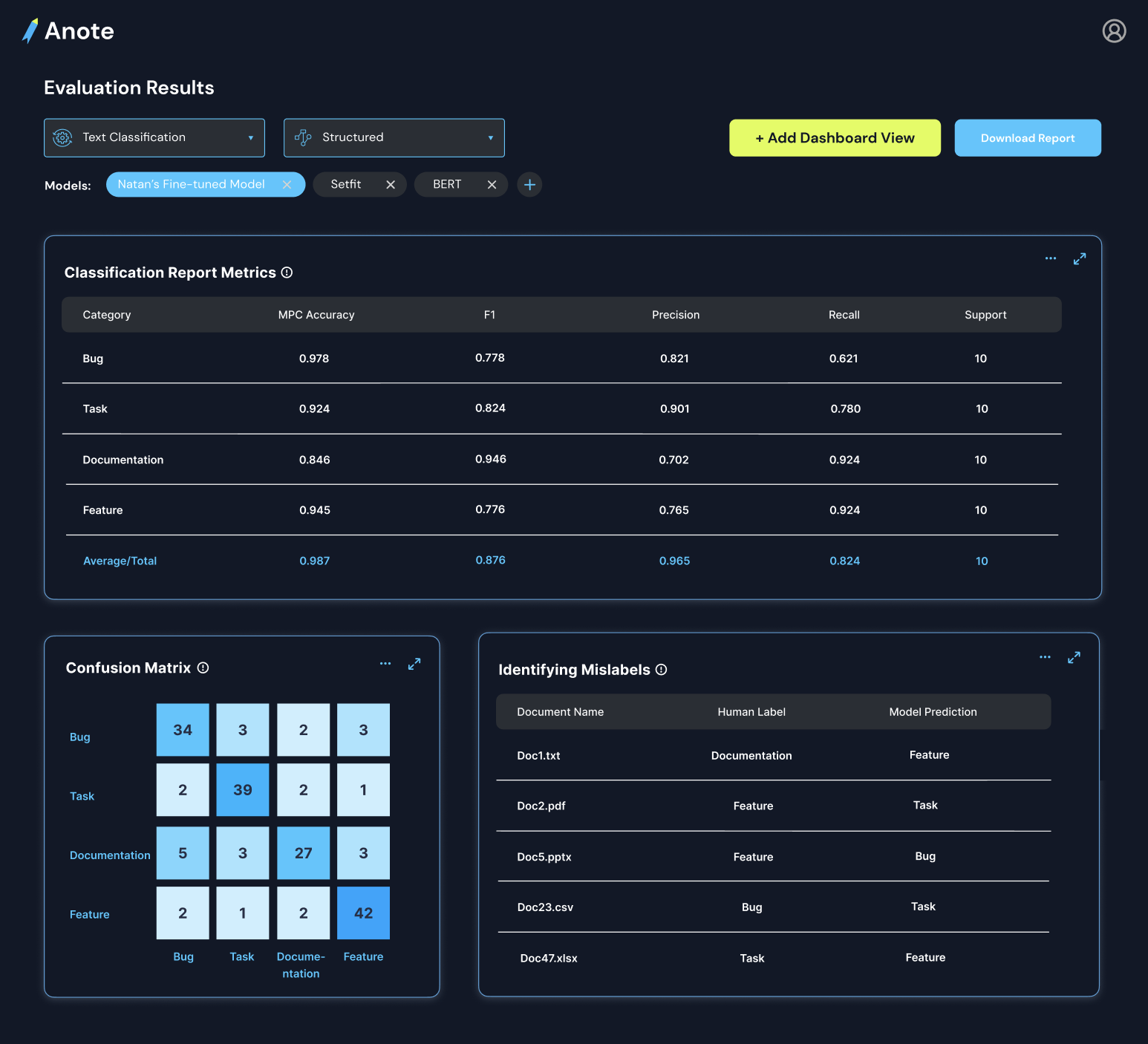
What Evaluation Measures
Evaluation helps teams understand how well a model performs on real tasks, not just whether it can generate an output. Depending on the workflow, this can include:
- Prediction Accuracy: Compare model outputs against labeled ground truth data.
- Retrieval Quality: Measure whether the model found the right document, page, or chunk before answering.
- Answer Quality: Score generated answers using semantic similarity, overlap-based metrics, or LLM-based review.
- Data Quality: Identify mislabeled rows, ambiguous examples, and areas where additional feedback is needed.
Structured vs. Unstructured Evaluation
There are two common evaluation settings throughout the Anote platform:
Structured evaluation uses labeled answers, labels, or entity spans as ground truth. This makes it possible to compute metrics such as accuracy, precision, recall, F1 score, cosine similarity, BLEU, and Rouge-L.
Unstructured evaluation is used when ground truth is not available. In these cases, evaluation focuses on whether the model response is grounded in the retrieved context and whether it answers the question well. This is especially useful for chatbot and retrieval-augmented generation workflows.
Supported Evaluation Workflows
Anote supports evaluation across the major workflows in the platform:
- Classification: Track accuracy over time, inspect confusion matrices, and analyze class-specific performance.
- Question Answering: Evaluate both retrieval quality and answer quality for document-based Q&A systems.
- Named Entity Recognition: Measure how predicted spans compare to ground truth entities across precision, recall, and overlap.
- Benchmarking Models: Compare baseline models, fine tuned models, and human feedback driven systems on the same evaluation set.
Why It Matters
Reliable evaluation helps teams move from experimentation to production. Instead of relying on anecdotal examples, you can quantify whether a model is improving, determine where it fails, and decide what data or feedback will have the highest impact.
This is especially important for enterprise and domain-specific AI systems, where correctness, consistency, and traceability matter more than generic benchmark performance.